Some industry works about how to utilize DRAM+PM archi as cache (from facebook and twitter).
(ATC '21) Improving Performance of Flash Based Key-Value Stores Using Storage Class Memory as a Volatile Memory Extension
PM is cheaper than DRAM, and lots of applications are memory hungry, especially for read-heavy workloads like block cache of DB. So they use PM as a second layer cache behind DRAM. They implemented cache admission and memory allocation policies.
note: I just saw a funny img about optane series 200 from StorageReview. Though it's super not professional, Random write workloads is really not Optane's area.
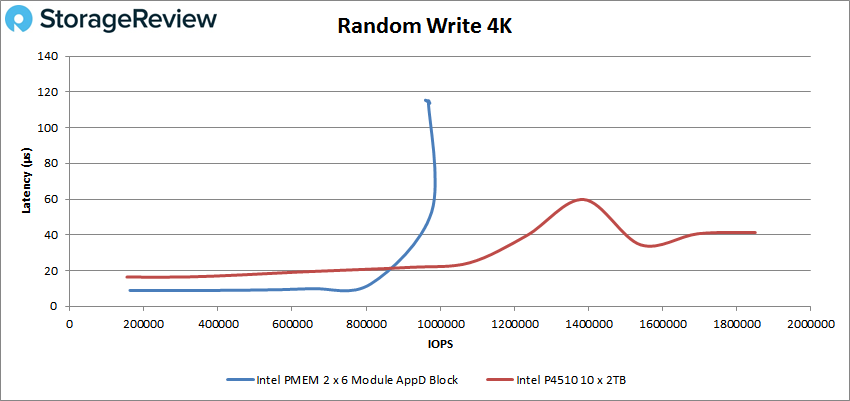
"We were able to match the performance of large DRAM footprint servers using small DRAM and additional SCM while decreasing the TCO of read dominated services in production environment."
their target goal is only read-dominant workloads with strong locality, which is easier to cache. When it comes to write-heavy ones (like facebook feed), the config of 32-256 is almost even with 64-0 (with default strategy), due to extra reads from stale cache.
note: it only proves that bigger simple cache is not effective for write-heavy. so, still some place to fill with here. Like placing memtable in PM…
they left persisting block cache and memtable in PM for fast warmup and write as future work.
industry works ha…
they tried 3 cache admission policies:
- DRAM first admission policy
- new data will be first written to DRAM. And stale data evicted by LRU will write to PM.
- SCM(PM) first admission policy
- new data will be first written to PM. if the refence counter exceeds the threshold, move data to DRAM.
- Bidirectional admission policy
- new data will be first written to DRAM.
- data in PM with big refence counters will be written back to PM.
note: this one combines the 2 above, and is a little bit similar to SplitFire.
intuitively, the 3rd seems better, but…
system design is simple:
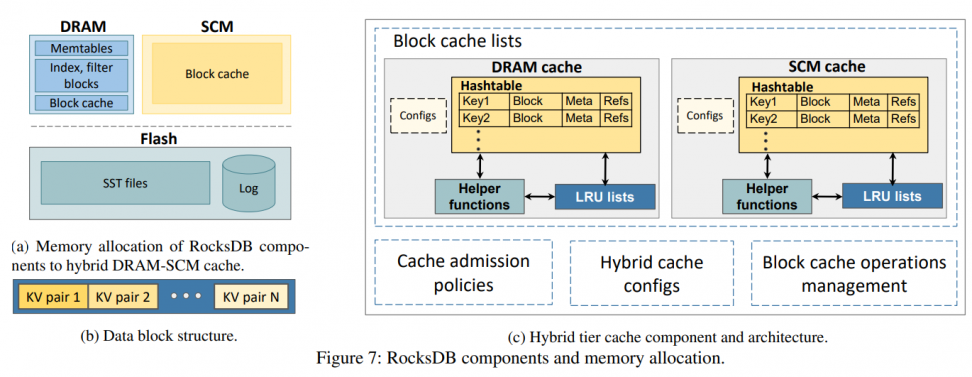 config: each socket * 2 memory controllers * 3 channels * (16GB DDR4 REG DRAM + 128G Optane PM) [aka 2-2-2 config]. And they use memkind of PMDK to develop this system.
config: each socket * 2 memory controllers * 3 channels * (16GB DDR4 REG DRAM + 128G Optane PM) [aka 2-2-2 config]. And they use memkind of PMDK to develop this system.
note: memkind provide malloc-style API to use PM as volatile memory.
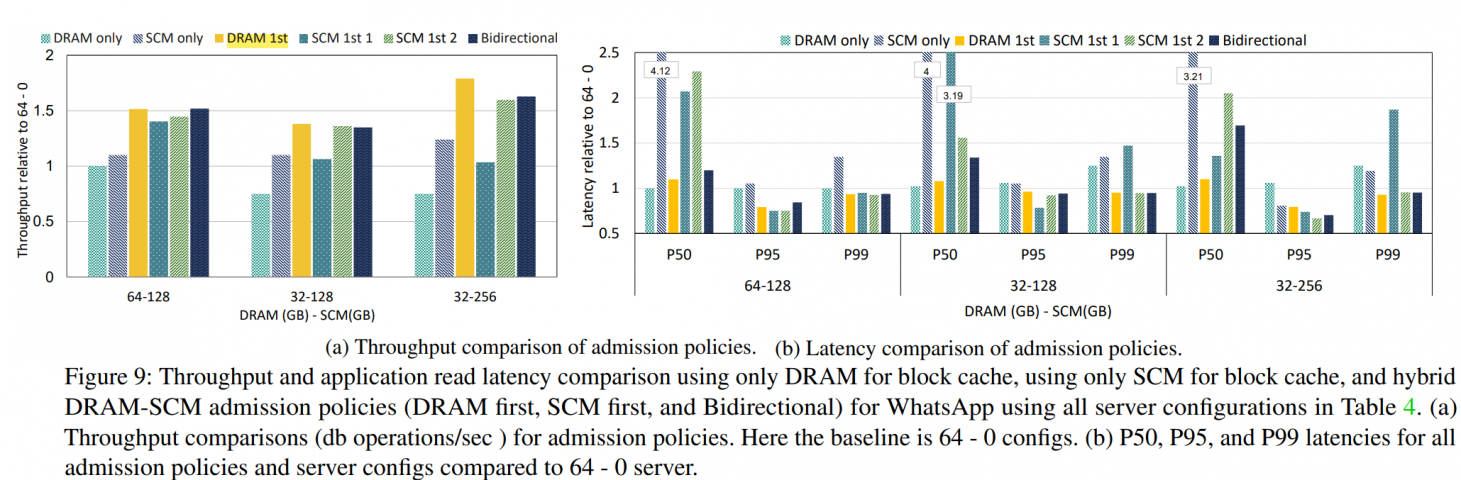
check this figure:
- throughput
- the improvement on throughput is about 25%~80%
note: throughput highly depends on the capacity!
- 32-128 config is better than 64-0
- DRAM 1st is the winner of three admission policies. The reason is that other policies create data transfer from PM to DRAM, which create more bandwidth consumption across the DDR bus, especially on the big block cache case.
note: DDR bus throughput can be the bottleneck… then is there memory-channel level locality?
Not a problem if PM is on CXL?
- the improvement on throughput is about 25%~80%
- latency
- P50 is only affected by DRAM
- DRAM 1st is the best trade-off
- benefit of latencies at higher percentiles is trivial.
Also, CPU utilization is within the one CPU limit.
because all strategies above are simple.. You can check some CPU utilization discussion about RocksDB in [4]
Cost-performance:
- In their cases, 32-256 config is the best with 23% cost increase and 50% - 80% performance improvement.
but higher density means more…
- deploy SCM of 1P instead of 2P in an overall cost saving of 40+%.
(SDC '20) Twitter Segcache
they bring Segcache[1] to PM.
tips: Only in memory mode, the config with few but larger PM dimms is bad for tail latency, which has lower bandwidth than more but small dimms. So if you don't have enough PM dimms, use AppDirect mode.
Use PM to store all slabs and DRAM to keep volatile metadata (like some pointers). The re-construction will cost about several minutes.
They rebuild Pelikan for PM (refer to Segcache[1]).
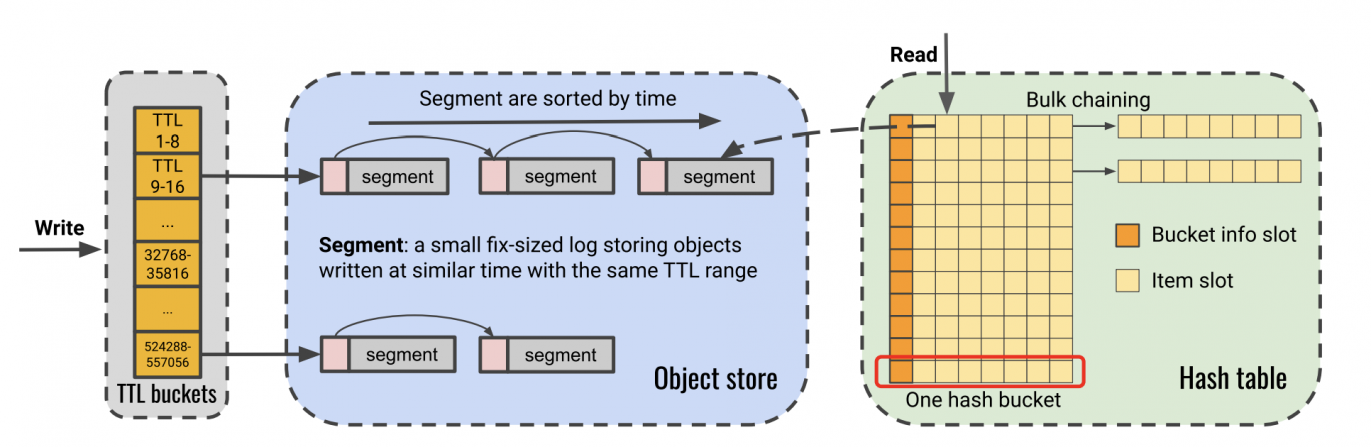
- PM only stores objects, while DRAM keeps metadata (the Hash Tables in the img above). So when updates or deletion, random ops will not access PM
- Use segments instead of slab
- segments are small append-only logs storing objects with the similar TTL and creation time
- all objs in the segment share a copy of metadata
note: I guess the metadata here only means creation timestamp, TTL, ref counters?
- delete: remove hash table entry
- expire: one segment at a time
- move shared segment header into DRAM, so that don't have to update metadata in PM
note: won't introduce inconsistency?
experiments:
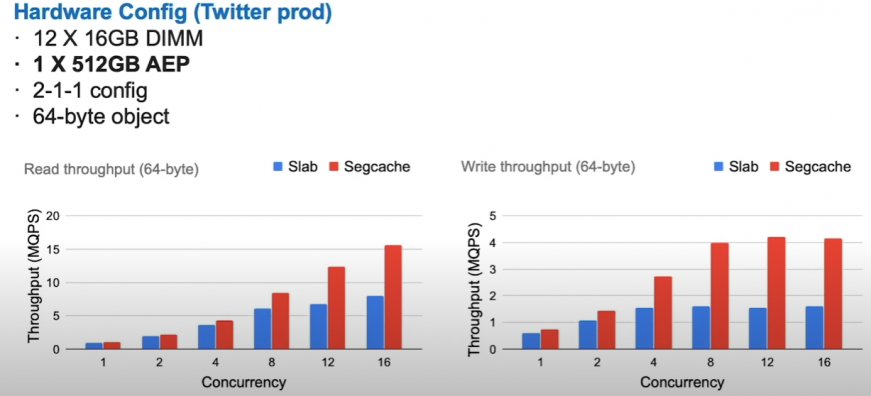
about 2.5x
random thoughts
refer
- Yang, Juncheng, Yao Yue, and Rashmi Vinayak. "Segcache: a memory-efficient and scalable in-memory key-value cache for small objects." NSDI. 2021.
- SDC2020: Caching on PMEM: an Iterative Approach https://www.youtube.com/watch?v=lTiw4ehHAP4
- Kassa, Hiwot Tadese, et al. "Improving Performance of Flash Based Key-Value Stores Using Storage Class Memory as a Volatile Memory Extension." 2021 {USENIX} Annual Technical Conference ({USENIX}{ATC} 21). 2021.
- Dong, Siying, et al. "Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience." 19th {USENIX} Conference on File and Storage Technologies ({FAST} 21). 2021.