(SIGMOD '18) HYMEM: Managing Non-Volatile Memory in Database Systems
HYMEM[1] managing NVM as a middle level between DRAM and SSD. Since NVM is byte-addressable, DRAM doesn't have to load the whole NVM page. Instead, using cache-line granularity can utilize the full throughput of NVM.
HYMEM design a 3 level storage system, and NVM is only a persistent buffer. All accesses will go directly to DRAM.
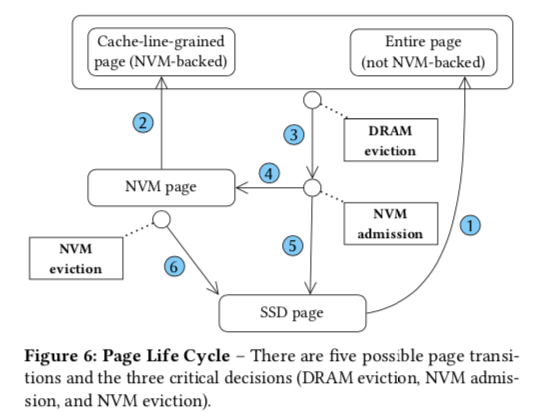
When eviction from DRAM, HYMEM uses ARC[2] to evict warm pages to NVM. It considers the page as warm if the admission request is the second one for this page.
And a dirty cache-line will go through DRAM to NVM, and finally to SSD.
HTMEM uses some bit masks to track cache-line status (in DRAM? is dirty?)
Although the access granularity is cache-line, allocating size in DRAM is still a whole page. So HYMEM uses mini-page (a slot array) to record the relationship between NVM cache-lines and DRAM cache-lines. An overflowed (>16 cache-lines) mini-page will be promoted to a full page.
SplitFire
HYMEM is limited by data copying, duplication and potentially wrong evictions of hot pages in DRAM just for space to read a cold page from SSD.
insights
- DAX NVM
- Exploits data flow from SSD to NVM
method
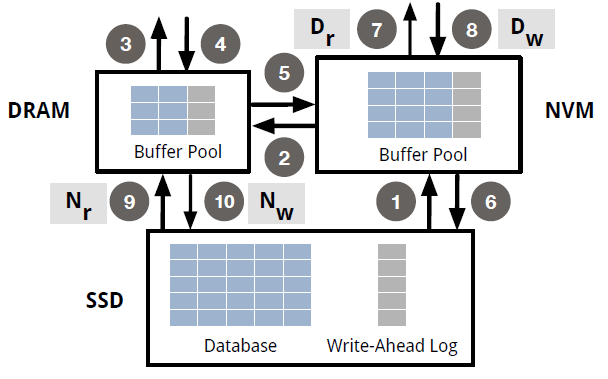
Data paths showing on the pic above involve three storage pools, and each pair of them can do admission and eviction. And NVM buffer pool is directly connected with CPU cache (DAX).
Like HotRing, they randomly sample NVM page references to detect data hotness for promotion. So here comes a hyper-parameter, sampling rate. A smaller sampling rate will detect fewer hot pages to increase precision. And it's considered that the sampling rate of HYMEM is 1.
In the whole data path, there are such 4 parameters in 4 additional paths: Dr, Dw, Nr, Nw.
note: the bigger values of those parameters, the more like the original HYMEM approach.
- Dr: when read, move data from NVM to DRAM. A smaller Dr works better when the working set is too large to fit in DRAM.
- Dw: when write, bypass DRAM and directly write to NVM, which improves latency and prevents evicting hot pages from DRAM.
- Nr: when read, bypass NVM, data directly loaded from SSD to DRAM. It's good for read-only pages from SSD and saves extra writes to NVM.
- Nw: when write, move data from DRAM to NVM
SplitFire uses simulated annealing[4] to optimize those hyper parameters, which is a classic probabilistic technique for approximating the global optimum of a given function. Not like gradient descent, simulated annealing is good for this kind of discrete searching space. $cost(Policy)=\frac{1}{Throughput}$.
curious about the convergence process…
And some popular tricks.
experiment
Q: "How should we provide a storage system given a cost budget?"
A:
- For three-tier hierarchies, Spitfire-Lazy is the ideal policy for delivering the highest throughput.
- For read-intensive or small working-set workloads, Spitfire- Lazy is the ideal policy as it increases the effective buffer capacities and ensures that the hottest data remains in DRAM.
- For write-intensive or large working-set workloads, NVM-SSD hierarchy stands out due to its buffer capacity advantage and its ability to reduce the flushing overhead of recovery protocol by performing persistent writes to the pages in NVM buffer.
note: quite intuitive results…
refer
- van Renen, Alexander, et al. "Managing non-volatile memory in database systems." Proceedings of the 2018 International Conference on Management of Data. 2018.
- Megiddo, Nimrod, and Dharmendra S. Modha. "ARC: A Self-Tuning, Low Overhead Replacement Cache." FAST. Vol. 3. No. 2003.
- Xinjing Zhou, Joy Arulraj, Andrew Pavlo, David Cohen. "Spitfire: A Three-Tier Buffer Manager for Volatile and Non-Volatile Memory" SIGMOD 2021 : International Conference on Management of Data
- https://en.wikipedia.org/wiki/Simulated_annealing