Background
EC is mainly for cold storage, providing low redundancy costs and availability. While hot storage need to keep QoS, so expensive replication is more common.
Also EC introduces expensive encoding and transferring costs when writing or reading data. As a result, more CPU and disk I/O will be used. But thanks to ISA-L and some lib, encoding in cache is quite fast. So usually, encoding is not the bottleneck in a carefully designed EC system.
Some popular EC works:
- reading
- LRC, Clay…
- writing
- logging: append update of data and parity to prevent write-after-read when updating, but it will incur extra reading cost.
- Parity Logging: only logging parity deltas to improve READs(data), and small updates. But logging of parity stills makes recovery slow (random read).
- Parity Logging with reserved space (PLR, FAST '14): pre-allocate space beside the primary parity chunks to prevent random read when recovery.
- PARIX (ATC '17): use delta of data instead of delta of parity to encode new parity.
Why we need EC in hot storage?
- distributed memory systems cause high tail-latency
- EC can off-loads requests to nodes in low loading, while keeping lower redundancy -> but degraded read here may lead to read-amplification
- recovering over 100GBs DRAM cache from other machines or local disks is time consuming for services
- replication on DRAM is expensive
Caching
(OSDI '16) EC-Cache: Load-balanced, Low-latency Cluster Caching with Online Erasure Coding
EC-Cache from K. V.Rashmi.
story: in-mem systems suffer skew workloads -> selective replication -> mem space is limited -> EC.
- Self-Coding and Load Spreading: split an object to k parts, and encode to $r$ parity. So a READ request for one object will be spreaded. => load balance
- Late Binding: when need to read k blocks, read k+delta blocks instead (including parities). So you can decode the first received k blocks to get k data blocks instead of waiting for possible delayed blocks. This approach can tame tail latencies.
w/o delta, directly reading k split-data-blocks will double tail latency.
They implement this on Alluxio.
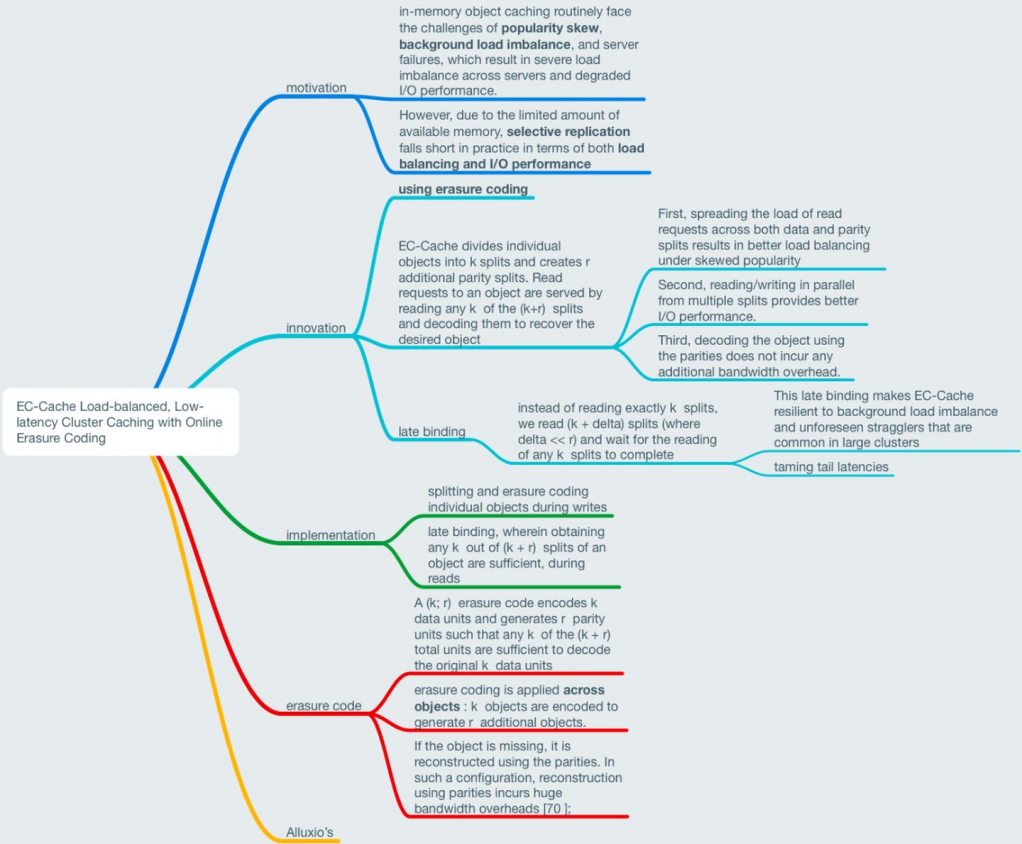
this pic is from 朱乐乐 in zhihu
read amplification? how to select delta? LB read strategies?
some extended works:
MSST'19 Parity-only caching for robust straggler tolerance. And extended version on JPDC22.
caching one parity to decrease tail latency:
- considering file popularity
- coding sub-chunk level
- pipeline encoding
SC'18 SP-Cache: Load-Balanced, Redundancy-Free Cluster Caching with Selective Partition. And extended version on TPDS22
mainly find the best num of EC slices(the $k$) based on data hotness and size. like the hotter, the bigger $k$ may be needed.
(FAST '16, ToS '17) Efficient and available in-memory KV-store with hybrid erasure coding and replication
Cocytus from IPADS, SJTU.
Just like MemEC, there are excessive updates on metadata
- -> so metadata in replication, and data in EC
Race Condition in Online Recovery.
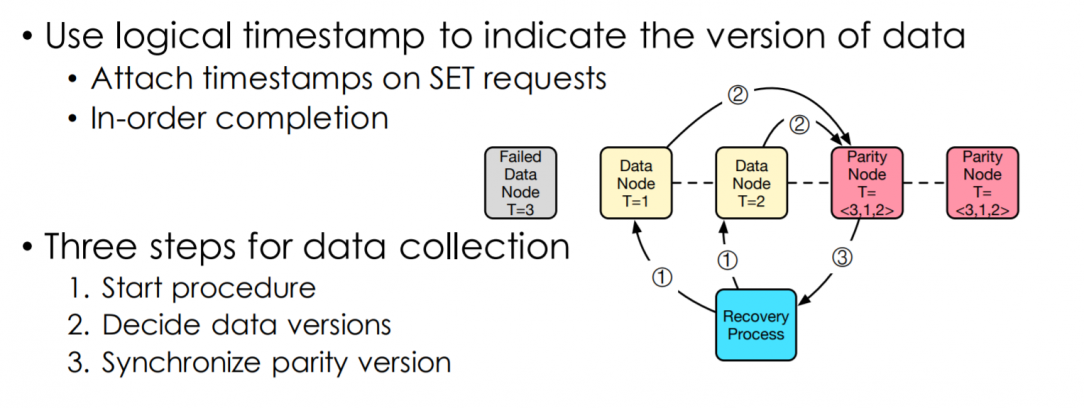 this is pic is from their slides.
this is pic is from their slides.
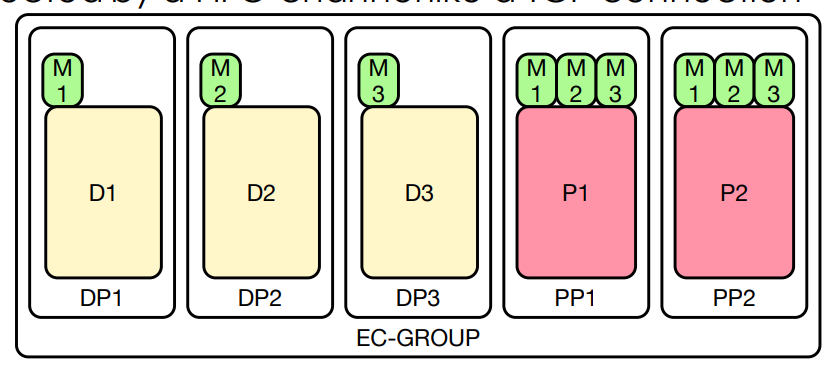
EC-GROUP is the basic component:
- M -> metadata
- D -> data
- P -> parity
To prevent 2-RTT when updating parity nodes, they used a piggybacking method, which combines data with a monotonously increased xid. When a parity node receive a xid, all smaller xids and the corresponding data in the buffer will be committed.
(SYSTOR '17) Erasure coding for small objects in in-memory KV storage
MemEC, which applies EC for big values of KVS.
hybrid encodings
To save storage cost while keeping availability, some researchers use EC for large data (like value).
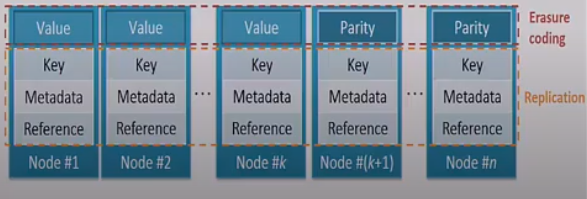
all-encoding
but if value is too small, then MemEC encode the whole objects. And one chunk (4KB) is related to multiple [metadata, key, value] pairs.
Once the size of a new chunk reach its limit, it will be sealed. And only sealed data chunk will be encoded. Also, data in chunks can be updated unless the size is larger than the limit. Because of linear combination, the cost of updating parity chunk is small.
Chunk and object index maps are based on cuckoo hashing.
seems like a lazy-approach…
(MSST'17) BCStore: Bandwidth-efficient in-memory KV-store with batch coding
A full-stripe update version of Cocytus.
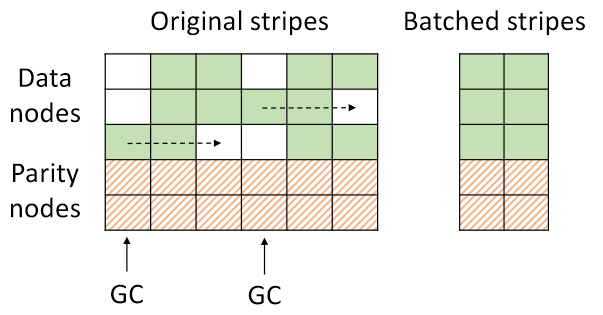
Batched coding: update in serveral new full stripes to trade latency for BW.
GC: full stripe update leads to invalid blocks, so GC is needed. To efficiently merge those partial valid stripes (less movements), the rule is merge the stripes with less valid blocks to those with more valid blocks. To make the distribution of invalid blocks more concentrated, the blocks in those updated new stripes are ordered by hotness.
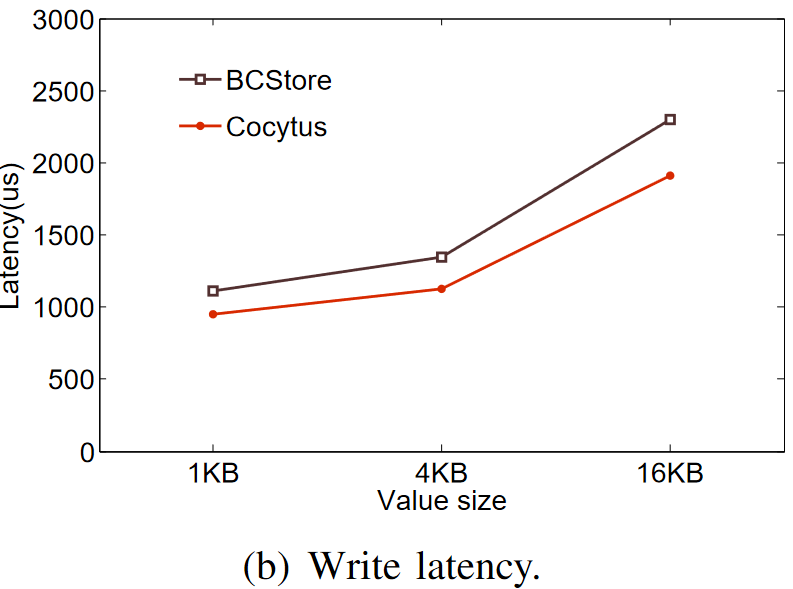
 They claim that the latency in queuing is not that great as big BW.
They claim that the latency in queuing is not that great as big BW.
Scaling
(SoCC '19) Coupling decentralized key-value stores with erasure coding
Some distributed KVSs use consistent hashing to distribute objects to minimize data movement when transfering. For LB, scaling incurs data movements. And data movements further triggers expensive parity updates.
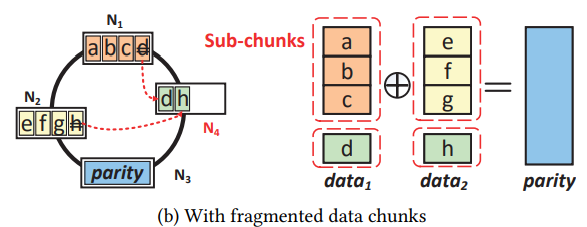
ECHash keeps mapping in old data node to new data nodes. (they called it sub-trunk, a smaller granularity than chunk) As a result the coding pair is not changed, so no need to update parity.
But in the fig above, d and h are in the same node, while they shouldn't be. What's worse, the scaling process itself will bring unavailability.
So how to ensure sub-chunks in different new nodes after removing and availability during scaling?
To cover this, they introduce multi-hash-ring, such that scaling only occurs at $n-k$ hash ring at a time.
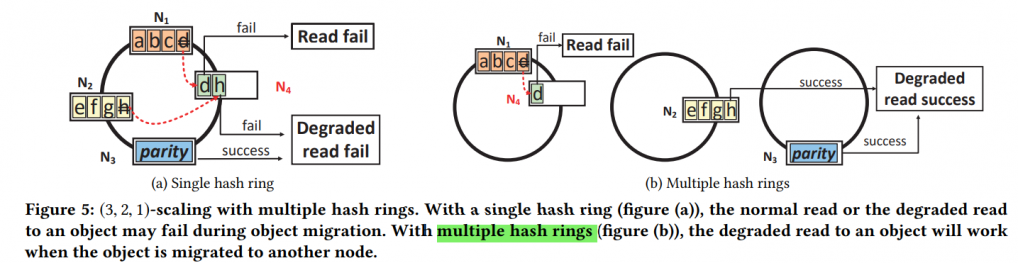
Seems like it will add weird contraints to scaling..
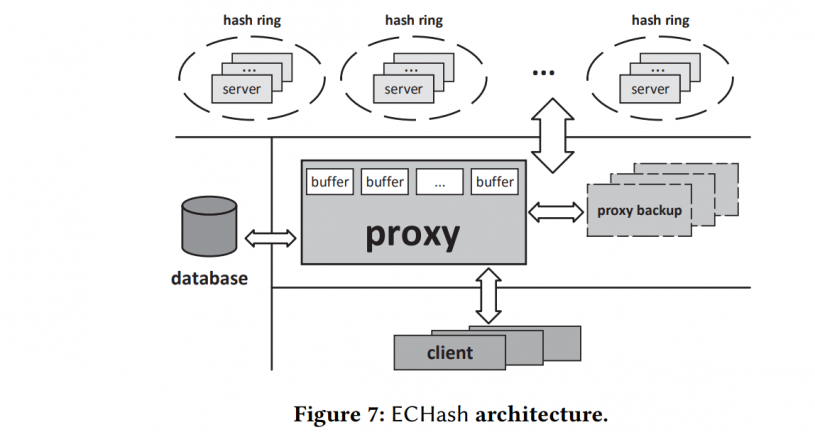
ECHash Archi:
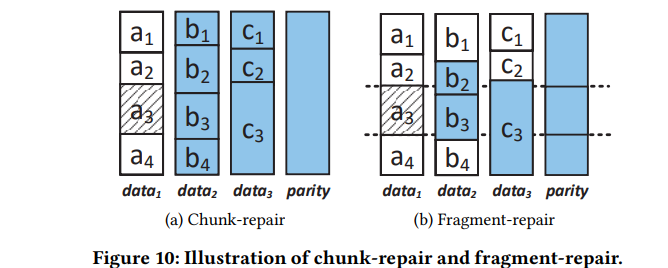
fragment-repair:
Proxy bottleneck? quote "We emphasize that the proxy is not the bottleneck in the scaling process, as the scaling performance mainly depends on the object migration and parity update overheads"
Note: GC (in batch)? the cost of precise repair?
(EuroSys '18) Fast and strongly consistent per-item resilience in key-value stores
This work is from ETH Zurich. Ring provide a resilient storage scheme for KVS with combining replication and EC. It built Stretched RS code to ensure the same key to node mapping for a range of RS codes with different $k$.
Stretched RS code:
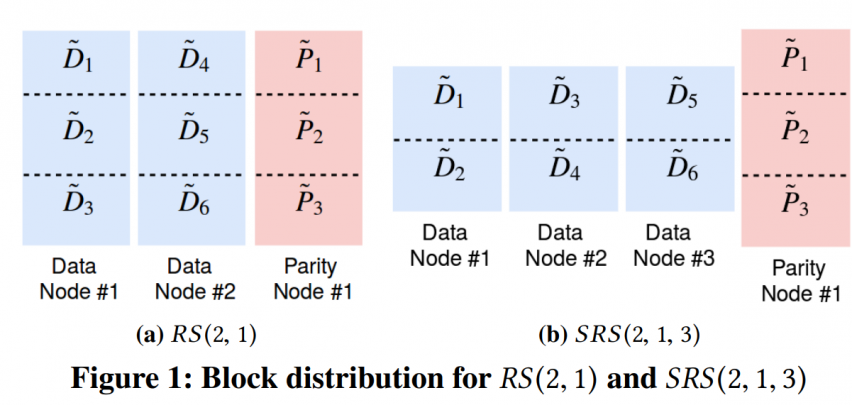
with $SRS(k,m,s)$ scheme, $k$ data blocks will be spread to $s$ nodes. So normal $RS(k,m)$ is equal to $SRS(k,m,k)$
SRS code just changes the placement strategy, like this figure above. The reliability of $SRS(2,1,3)$ and $RS(2,1)$ is same, while $SRS(2,1,3)$ share identical key to node mapping with $RS(3,1)$
note: encoding granularity is amplified from k blocks to lcm(k,s) blocks
quick SRS example:
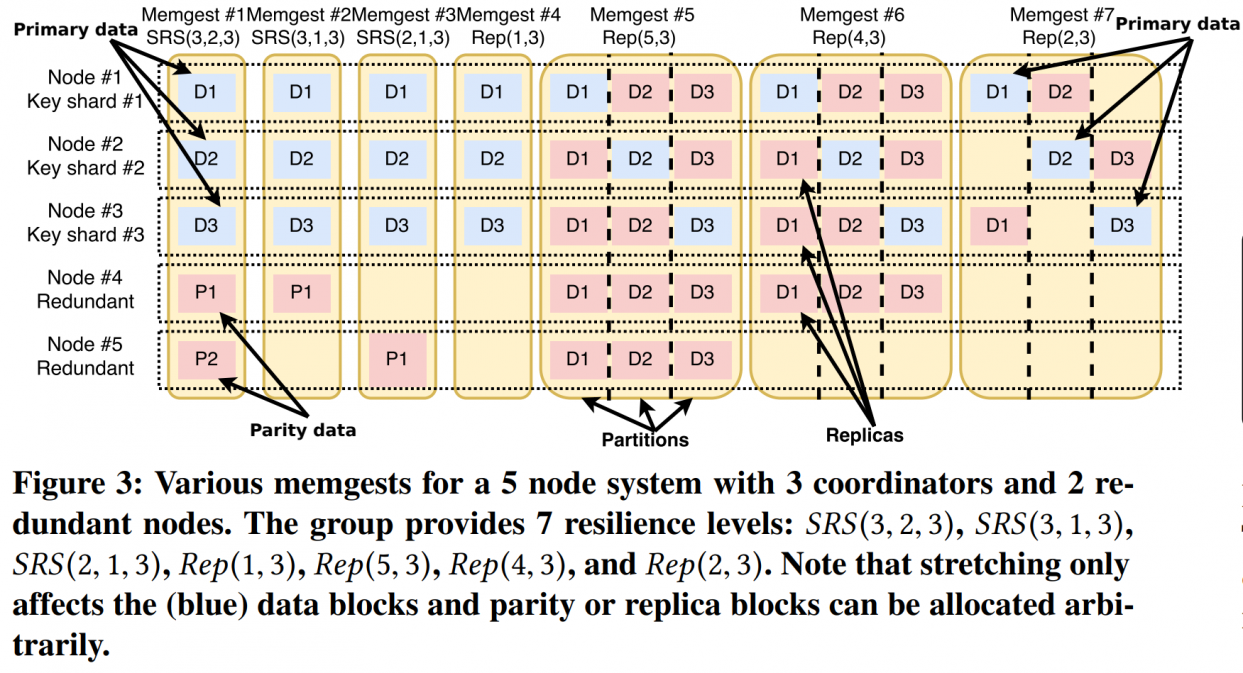
So that we can combine many storage schemes w/o changing the node layout, and access them with a unified key to node map.
Parity Updating
(SC '21) LogECMem: Coupling Erasure-Coded In-memory Key-Value Stores with Parity Logging
UPDATEs in in-mem EC KVS are expensive (mem footprint…) (and considering wide-stripe…) -> let's go for parity logging in disks of parity nodes as a lazy approach
but there is a big performance gap…
So details in my post
others related
I will choose an 黄道吉日 to update the second part, including the following papers :)
- CLUSTER'19 Li, Yuzhe, et al. "Re-store: reliable and efficient kv-store with erasure coding and replication." 2019 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 2019.
Some combined RDMA with EC..
- ICDCS'17 Shankar, Dipti, Xiaoyi Lu, and Dhabaleswar K. Panda. "High-performance and resilient key-value store with online erasure coding for big data workloads." 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS). IEEE, 2017.
- IPDPS'21 Xu, Bin, et al. "F-Write: Fast RDMA-supported Writes in Erasure-coded In-memory Clusters." 2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2021.
- FAST'22 Lee, Youngmoon, et al. "Hydra: Resilient and Highly Available Remote Memory." 20th USENIX Conference on File and Storage Technologies (FAST 22). 2022.
- OSDI'22 Yang Zhou, et al. "Carbink: Fault-Tolerant Far Memory." 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) 2022.
- CoNEXT'19 Kazhamiaka, Mikhail, et al. "Sift: resource-efficient consensus with RDMA." Proceedings of the 15th International Conference on Emerging Networking Experiments And Technologies. 2019.
And this one focused on availability in serverless in mem cache
- Wang, Ao, et al. "{InfiniCache}: Exploiting Ephemeral Serverless Functions to Build a {Cost-Effective} Memory Cache." 18th USENIX Conference on File and Storage Technologies (FAST 20). 2020.
ref
- Rashmi, K. V., et al. "EC-Cache: Load-balanced, low-latency cluster caching with online erasure coding." 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16). 2016.
- Litwin, Witold, Rim Moussa, and Thomas Schwarz. "LH* RS—a highly-available scalable distributed data structure." ACM Transactions on Database Systems (TODS) 30.3 (2005): 769-811.
- Yiu, Matt MT, Helen HW Chan, and Patrick PC Lee. "Erasure coding for small objects in in-memory kv storage." Proceedings of the 10th ACM International Systems and Storage Conference. 2017.
- Chen, Haibo, et al. "Efficient and available in-memory KV-store with hybrid erasure coding and replication." ACM Transactions on Storage (TOS) 13.3 (2017): 1-30.
- Cheng, Liangfeng, Yuchong Hu, and Patrick PC Lee. "Coupling decentralized key-value stores with erasure coding." Proceedings of the ACM Symposium on Cloud Computing. 2019.
- Taranov, Konstantin, Gustavo Alonso, and Torsten Hoefler. "Fast and strongly-consistent per-item resilience in key-value stores." Proceedings of the Thirteenth EuroSys Conference. 2018.