LogECMem uses a hybrid method of in-place update and Parity logging (PL) for parity updates.
motivation
old update policies:
- direct reconstruction: read all non-updated data, and compute the new parity with old parities. (huge data transfer costs)
- in-place update: read old parity, and compute the parity delta by data delta. (too many reads to old parity
- full-stripe update: out-of-place update, and GC stale data chunks. (no parity reads but it brings high space cost
- PL: logging the parity deltas (But PL is designed for disk-based systems
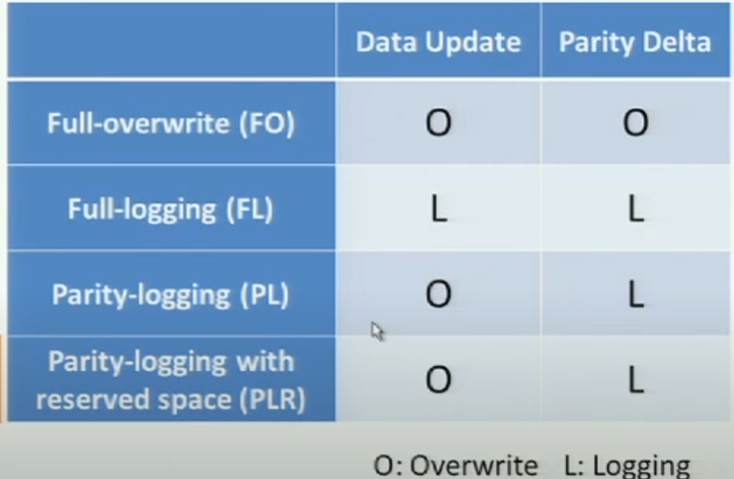
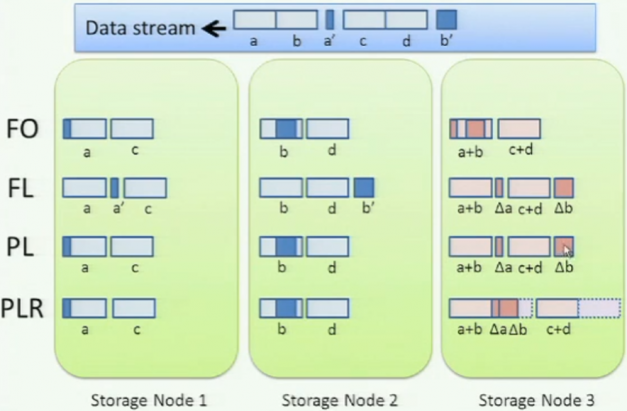
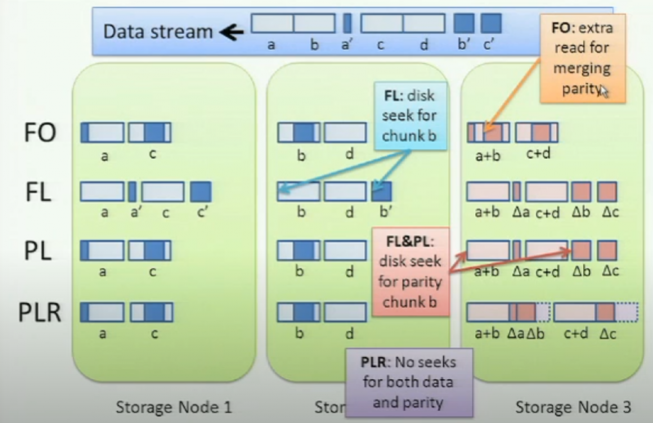
They claimed that:
- for wide-stripe EC, GC in full-stripe update will consume a lot of network bandwidth.
- full-stripe update will take more memory space due to invalid blocks
- single-failure is the most critical (in a MTTDL model)
So they built LogECMem by in-place update for XOR parity in DRAM and PL for other parities.
methods
design
Like buffer logging of RAMCloud[2], they use buffer logging for other parity chunks to accelerate writes:
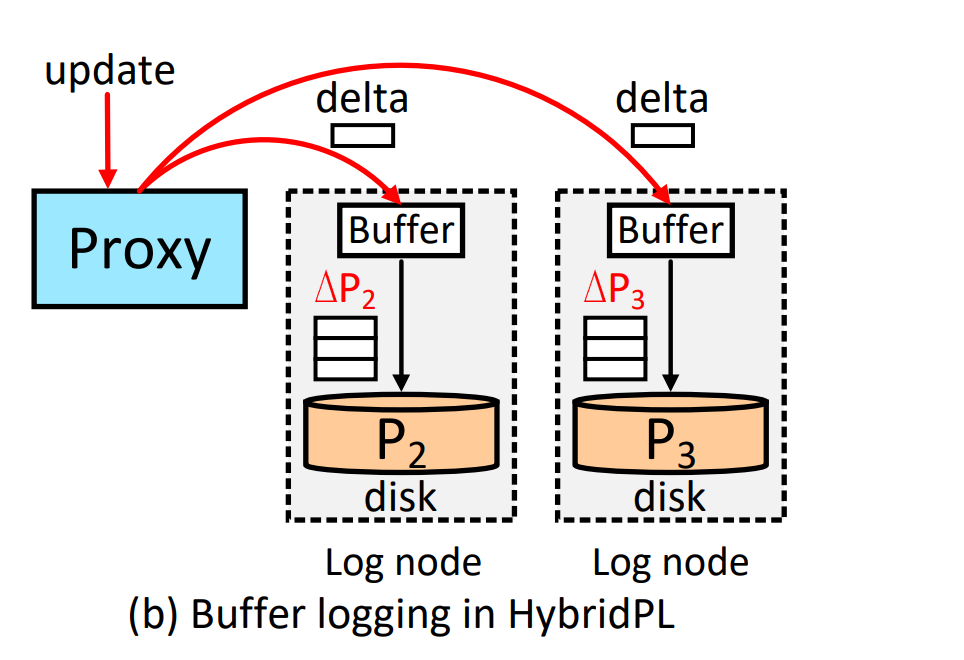 (the buffer here is DRAM)
(the buffer here is DRAM)
note: PM is a good log device, and not limited by capacity.
btw, the persistence in buffer logging of RAMCloud[2] is ensured by battery-based DRAM. So PM is appropriate and may provide fast recovery (since the gap between DRAM and disk is big)? But it's weird to talk about logging persistence on a storage system keeping all data in DRAM….
related: flatstore
With this XOR parity in DRAM, systems can perform degraded read in DRAM nodes.
Op
update:
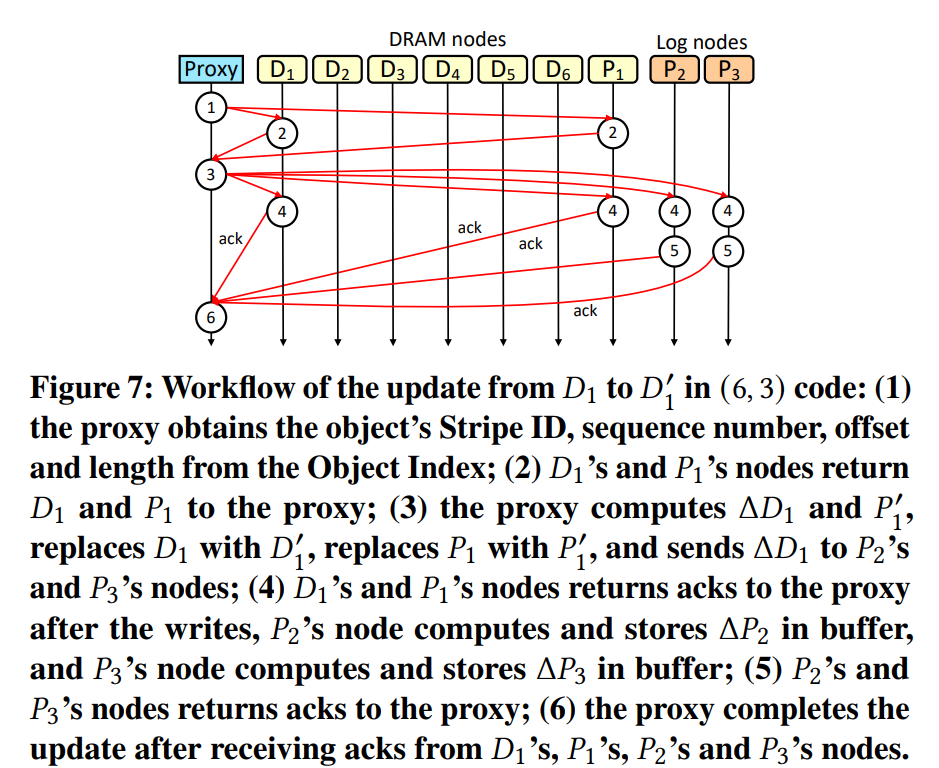
…check paper for details…
merge-based buffer logging: a log merging trick
multiple chunk failures repair
PLR (FAST '14) trades write performance for the repair performance. Simple merging logging on PLR only can merge incoming parity deltas.
So they use a lazy merging strategy (parity logging with merging, PLM) that writes parity to extra continuous disk space, and then reads them back for merging later.
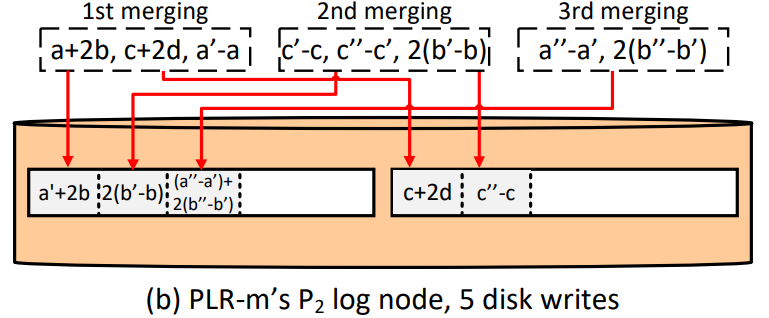
note: kindof 2-level? the first non-ordered level won't hurt perf?
also, any perf bottleneck in logging and 2nd-level logging replacement (GC-like)? It seems like only overall perf test in the experiment part.
expriments
……
ref
- Cheng, et al. LogECMem: Coupling Erasure-Coded In-memory Key-Value Stores with Parity Logging, SC '21.
- Ousterhout, John, et al. "The RAMCloud storage system." ACM Transactions on Computer Systems (TOCS) 33.3 (2015): 1-55.