简介
fatcache是来自Twitter, 基于SSD上面实现的cache, 使用mc的协议,数据存储在SSD (Ps:memcached是将数据放在内存中)。 fatcache的数据放在SSD(其实机械盘也可以,只是性能不佳), 所以相对于内存cache, 如memcached、redis,能容纳更多数据。 所以叫fat-cache(Ps: 这个是我自己意淫的), 中文翻译: "死胖子缓存"
1) 通过slab管理数据,跟memcached类似,但稍有不同. 2) 通过索引查找数据. 3) 单线程 4) 针对写SSD做了优化
更多的特性在后续详细介绍,这里不能说太多(PS: 不然这节会很长, Orz)。
对于SSD开发来说, 有两种不同的理解:
-
SSD是更快的磁盘,用作存储, 能保证数据的强一致性。
-
SSD是内存的扩展,当作慢内存使用, 作为cache,不要求数据的强一致性。
NOTE: fatcache从名字来看就是作为cache,只是更大更肥的cache。 (PS: 因为放在SSD,正常能容纳更多的数据)
a) 为什么选择SSD而不是直接使用内存?
-
内存虽然比SSD快了很多, 但是同等密度的容量,价格也高出很多,高帅富就全放内存就好了。
-
虽然时间推移, 数据会越来越多, 需要不断对内存不断横向扩容
-
对于数据来说, 只有很少的一部分数据会被经常访问, 我暂时叫热数据 当冷数据(访问比较少)比例大大高于热数据时, 这种存储方式就很不划算
b) 使用场景
fatcache比较适合使用在符合下面条件的场景:
- 数据量比较大,屁大的数据内存能放下,成本又不高的,别来凑热闹了好么!!!
- 请求性能可以接收会比全内存差一点,又比DB好一点的地方,这个位置挺好,又挺尴尬的.
也就是很适合那种数据全部放在内存成本太高,放大部分在DB,DB访问压力比较大的尴尬场景. (PS: 这样的条件还看不懂的,也不适合用)
c) Fatcache Vs Memcached
-
fatcache的实际存储数据在SSD,一小部分cache在内存, mc全部内存
-
fatcache多了一层索引。 索引除了快速判断key是否存在,同时用来记录数据所在位置,快速读取value
-
mc 哈希表存储真实数据, fatcache哈希表只存储索引信息
-
fatcache是单线程
-
fatcache不支持二进制协议
-
slab实现上有所区别
d) 针对SSD的优化?
-
批量写, fatcache每次写磁盘都是slab为单位, 默认1M, 减少大量的小IO写, 同时避免写放大
-
随机写转化为顺序写
NOTE: fatcache是随机读, 在性能上, 写的性能远好于读, 具体的性能可以参考: Performance
[<下一节 配置参数="">](./configure.md)
配置参数
初学者如果对启动参数不了解,可以参照下面解释,否则可以跳过这节。
Usage: fatcache [-?hVdS] [-o output file] [-v verbosity level]
[-p port] [-a addr] [-e hash power]
[-f factor] [-n min item chunk size] [-I slab size]
[-i max index memory[ [-m max slab memory]
[-z slab profile] [-D ssd device] [-s server id]
Options:
-h, --help : this help
-V, --version : show version and exit
-d, --daemonize : run as a daemon
-S, --show-sizes : print slab, item and index sizes and exit
-o, --output=S : set the logging file (default: stderr)
-v, --verbosity=N : set the logging level (default: 6, min: 0, max: 11)
-p, --port=N : set the port to listen on (default: 11211)
-a, --addr=S : set the address to listen on (default: 0.0.0.0)
-e, --hash-power=N : set the item index hash table size as a power of two (default: 20)
-f, --factor=D : set the growth factor of slab item sizes (default: 1.25)
-n, --min-item-chunk-size=N : set the minimum item chunk size in bytes (default: 84 bytes)
-I, --slab-size=N : set slab size in bytes (default: 1048576 bytes)
-i, --max-index-memory=N : set the maximum memory to use for item indexes in MB (default: 64 MB)
-m, --max-slab-memory=N : set the maximum memory to use for slabs in MB (default: 64 MB)
-z, --slab-profile=S : set the profile of slab item chunk sizes (default: n/a)
-D, --ssd-device=S : set the path to the ssd device file (default: n/a)
-s, --server-id=I/N : set fatcache instance to be I out of total N instances (default: 0/1)
上面是fatcache全部的用户可配置参数, 接下来看一下除了-h显示帮助, -V显示版本这两个配置,其他配置选项的作用。
-d, --dammonize
fatcache server是否后台运行,一般部署的时候,会后台执行,这个比较简单,略过。
-S, --show-sizes
打印slab, item和index的长度
-o, --output=S
日志输出路径, 默认是输出到终端
-v, --verbosity=N
日志级别,0~11, 默认是6, 下面是相关定义:
#define LOG_EMERG 0 /* system in unusable */
#define LOG_ALERT 1 /* action must be taken immediately */
#define LOG_CRIT 2 /* critical conditions */
#define LOG_ERR 3 /* error conditions */
#define LOG_WARN 4 /* warning conditions */
#define LOG_NOTICE 5 /* normal but significant condition (default) */
#define LOG_INFO 6 /* informational */
#define LOG_DEBUG 7 /* debug messages */
#define LOG_VERB 8 /* verbose messages */
#define LOG_VVERB 9 /* verbose messages on crack */
#define LOG_VVVERB 10 /* verbose messages on ganga */
#define LOG_PVERB 11 /* periodic verbose messages on crack */
-p, --port=N
监听端口,默认是11211. 这个也是没什么好说
-a, --addr=S
监听地址,如果有多块网卡的时候,可以设置监听的ip,默认是0.0.0.0
-e, --hash-power=N
这个参数决定item index的hash表的大小,hash的bucket数= 2 ** N, 这个数值如果设置太小,
可能会导致冲突变多,设置太大,会浪费空间, 应该根据实际的使用量来确定.
-f, --factor=D
每一层slab之间item长度的增长因子,默认1.25,比如slab calss有3级(实际应用中会有远大于3),
如果第一级item长度是20byte, 第二级的就是 20 * 1.25 = 25bytes, 第三级就是 25 *1.25, 以此类推...
设置这个参数,比较需要技术含量,如果算不准,就不要乱改了。
-n, --min-item-chunk-size=N
item最小长度,也就是slabclass第一层item的大小, 默认84bytes, 设置大小不能小于84.
-I, --slab-size=N
slab大小,默认是1M. 这个是fatcache写入磁盘的单位,所以如果有修改,需要对比一下性能.
-i, --max-index-memory=N
索引占用最大内存,索引数量 = max-index-memory/sizeof(itemx), sizeof当前在64bit操作系统上是44bytes.
索引的数量也就是能容纳k-v数,如果太小,可能会有大量k-v剔除。这个值要根据k-v大概数量先算好。
-m, --max-slab-memory=N
内存slab的最大内存,由于fatcache操作ssd是direct io, 这个相当于ssd的cache。
这个设置越大,读写速度会越快.
-z, --slab-profile=S
slab class优化配置,可以配置Slab每一层的item大小,不用factor作为增长因子。
-D, --ssd-device=S
数据存放的磁盘文件路径,如果是分区直接使用,如果是普通文件,需要先撑大文件。
比如设置1G, 需要把文件lseek到1G, 不然fatcache读出来的size = 0, 会产生错误.
-s, --server-id=I/N
当部署多个实例,需要设置这个参数,N表示实例个数,I表示当前实例编号。
多实例能更好利用ssd并发读写,比如ssd总共是8G可用,那么当前实例读写开始地址 = (8G/8) *I。
fatcache 的配置就是上面这些,阅读可以先大概知道,后续真正使用再回来看。
接下去看一下 Mc协议
MC 协议
MC指的是memcached, 它支持文本和二进制协议,fatcache只使用文本协议。 我们这里不对二进制协议做 解释,想要的可以看 mc二进制协议,同时下面罗列的也只是常用的协议。
我们常用的协议可以分为以下几类:
- Storage Commands, 写相关命令
- Retrieval Commands, 读相关命令
- Delete Comands 删除命令
- Touch Comands 修改过期时间命令
- 其他stats命令,fatcache不支持.
Storage 命令
请求行协议格式:
<command name> <key> <flags> <exptime> <bytes> [noreply]\r\n
cas <key> <flags> <exptime> <bytes> <cas unique> [noreply]\r\n
/** 字段注解 **/
<command name>: 对于写命令有set/add/replace/append/prepend这几种。
<key>: 查找value对应的关键字.
<flags>: 16bit数值,对server透明,返回时带回client,可用来标识当前value数据类型,1.2.1后为32bit.
<exptime>: 过期时间, 如果是0, 表示用不过期。
<bytes>: 后续发送data块(value)的字节数, 长度不包括(\r\n).
<noreply>: server不用回复client, 如果出错,server可能还会返回,client没有读取,就会错乱.
<cas unique>: 唯一的64bits数字,表示value的版本, 在做cas命令使用.
storage 命令由请求行和数据行两部分组成, 上面的协议格式是请求行, 接下来是数据行:
<data block>\r\n, 这个一般就是value.
上面我们可以看到cas命令的请求行格式跟其他命令不太一样,后面有个cas unqiue, 这个是由gets命令返回的
unique数值。 cas命令使用数值跟当前key的unique对比,如果不一样,表示当前key已经被更新过,返回失败。
还有对于prepend和append 两个命令,flags和exptime是不起作用的。
返回格式
- "STORED\r\n" 表示执行成功
- "NOT_STORED\r\n" 表示执行失败, 一般用来表示add或者replace条件不满足.
- "EXISTS\r\n" 表示cas命令的那个key已经被修改过.
- "NOT_FOUND\r\n" 表示cas的key不存在
Retrieval 命令
请求行协议
get <key>*\r\n
gets <key>*\r\n
/** 字段注解 **/
<key>* : 多个用空格分割的key
返回格式
get和gets都是支持多个key, 也就是返回可能会有多个value,最后以END\r\n表示结束.
格式类似:
value1
value2
...
END\r\n
每个value格式如下:
VALUE <key> <flags> <bytes> [cas unique]\r\n
<data block>\r\n
key flags bytes和Storage命令里面的意义一样,不再重复, [cas unique]只有gets命令才会返回,
datab block是返回的value。
Delete 命令
请求行协议
delete <key> [noreply]\r\n
/** 字段注解 **/
<key> 查找关键字
[noreply] client要求不回复, 同Storage命令.
返回格式
- "DELETED\r\n" 表示正常删除成功
- "NOT_FOUND" 表示key不存在
注: 删除还有一个flushall命令,删除所有key, 这里不解释.
Increment/Decrement 命令#####
请求行协议
incr|decr <key> <value> [noreply] \r\n
<key>: 查找关键字
<value>: 10进制数字,对key对应的value增加或者减少的大小.
返回格式
- "value\r\n" value是更新之后的value
- "NOT_FOUND\r\n" 表示key对应的value不存在
注: 如果decr的之后的value<0, 结果还是返回0. 对应incr溢出,大于64bit的最大值,则是截断.
Touch 命令
请求行协议
touch <key> <exptime> [noreply]\r\n
字段意义不变
返回格式
- “TOUCHED\r\n” 表示修改成功
- “NOT_FOUND” 表示修改的key不存在
The End
还有其他很多命令如Version, Quit, Stats, Slab 这些状态或者统计信息的命令我们这里没有细说, 想要了解可以自己去深入了解。
下一节是fatcache里面很重要的概念 slab机制
(四) slab分配机制
为什么要有slab?
我们前面说过,fatcache对于写磁盘做了优化,就是通过slab管理做到。slab管理简单来看,就是每次申请一块大内存(fatcache默认1M), 不必每次去申请一小块内存,而是直接从已经申请的slab中拿出一小块来写,当不使用时,不用释放,而是放回slab, 这样,就可以大大减少申请和释放的频率。
fatcache把磁盘空间切割成一个个的slab, 每次写满一个slab之后,才会写回磁盘,也就是说每次写入磁盘的数据都是一个slab长度(1M), 这样就可以不必每次写入一个kv都要写一次磁盘。
好处:
- 避免SSD的写放大,SSD每次写磁盘的最小单位是page(一般是4k),也就是即使是写入1byte,SSD内部也是相当于写4k, 这就是我们说的写放大,我们每次只会写入1个slab, 不会有写放大。
- 减少大量的小块的IO随机写, 同时把大量的随机写转化为顺序写,可以延长SSD的写寿命。
4.1 slab分配机制?#####
slab内存分配是一种用来高效管理内存的机制,可以避免频繁申请和释放内存带来的内存碎片问题, 同时提高内存分配效率。最早是在Solaris2.4的内核引入这个算法, 后面广泛应用在许多Unix和 类Unix(如FreeBSD)的操作系统上, 而在linux上直到2.6.23才成为默认的分配方式。 slab分配最简单的理解, 就是每次使用内存时,一次申请一片大内存,当需要使用内存时, 直接从slab分配,释放也是放回slab, 而不必从操作系统不断分配和释放。
为了可以重复分配和释放slab里面的item, 我们正常时把一个slab切分成长度相等的item, 比如slab是1M,每个 item是1024byte, 那么一个slab就是切分成1M/1024 = 1024个item.
简单版的slab如下图所示:
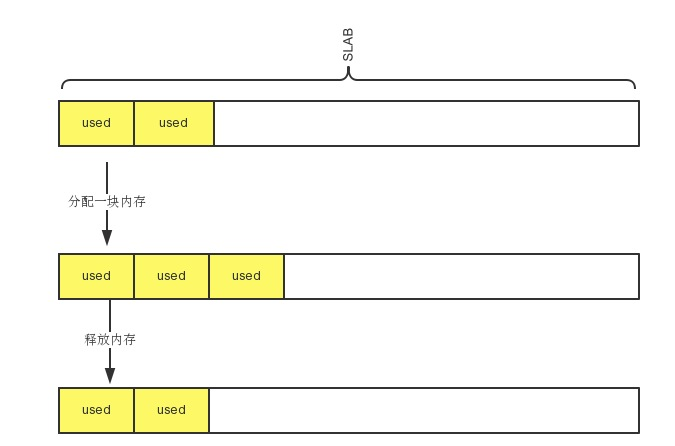 每次我们添加kv到fatcache的时候,直接从slab中拿到一个item,然后写入。
每次我们添加kv到fatcache的时候,直接从slab中拿到一个item,然后写入。
4.2 slab class
由于并不是所有的kv的长度都是一样的,这就需要不同item长度的slab, 而slabclass就是这些 不同长度item的slab的集合。在一般设计slabclass的时候,可以把slabclass看作一个item长度递增 的数组,并把slab放到对应的队列中。当在添加数据的时候,找到能容纳kv长度的slabclass,然后从未使用完或者空闲的slab, 分配一个item空间。
如slabclass有n级, 假设每个slab是1M, 第一级item长度是100byte, 每级增长因子是1.2。
第一级item的长是100bytes, item count = 1M/100
第二级item的长度是100byte*1.2 = 120byte, item count = 1M/120
第三级item的长度是120*1.2 = 144bytes, item count = 1M/144
以此类推.
当需要申请80byte的内存时候, 从第一级开始找,直到遇到第一个比它大的slab, 这里就是第一级的slab。 如果要申请130bytes的内存, 就是找到第三级.
回到fatcache, 在配置参数里面-f 选项就是配置增长因子, -I 配置slab大小。
4.3 memory and disk slab
fatcache的slab来自两个地方,一个是内存,另一个是磁盘。在启动的时候,可以指定内存slab大小, 默认是64M, 我们也会指定磁盘分区。然后再把内存和磁盘的空间,切分为一块块slab, 再添加到free slab队列。 fatcache的内存slab, 充当的角色是写缓存,每次写的时候,一定是写在内存slab, 当写入时,发现没有内存slab, 就将最老的slab刷入磁盘。
fatcache 写
1. 如果还有内存slab未写满,直接分配地址,返回。
2. 如果所有内存slab已经写满, 从内存full slab队列头部,剔除一个slab, 交换到磁盘slab,
空出内存slab, 重新分配。
我们可以看到,写的时候一定是写在内存里面,而读是,根据slab所在位置,直接读取,所以我们可以知道,
只有写才会让内存slab和磁盘slab数据进行交换, 读不会影响数据所在位置是在内存还是磁盘,换句话说,
只有更新才会影响fatcache的数据的热度。
4.4 slab在fatcache的使用
看过上面的内容之后,应该能知道slab大概的样子,以及Slabclass是干嘛的。 slabcloass每一级slab可以分配 的item长度和数量是固定的, 所以slab可能会有三种状态: free slab(完全没有使用), partial slab(部分使用), full slab(全部使用).
最开始, 由于没开始使用,只会有free slab, 当使用一段时间后,就转换为partial slab, 如果这个slab已经被分配完, 则会变为full slab.
在fatcache中, 会维护这三种状态的slab, 其中free slab, full slab队列是slabclass所有级公用,partial slab是每一级都有一个 队列。
当某一级需要分配空间, 会经历下面的步骤:
1. 如果这一级partial slab队列不为空, 先从这个队列里面取, 如果不为空,直接分配, 判断slab是满了,是?移到full slab队列。
2. 如果这一级parital slab队列为空, 从free slab队列获取一个slab, 放到这一级slab,重新分配。
我们以内存的slab作为例子, 在fc_slab.c里面, 我只列出关键部分:
struct item *
slab_get_item(uint8_t cid) {
....
/* item 索引使用耗尽,应该做一些剔除 */
if (itemx_empty()) {
status = slab_evict();
if (status != FC_OK) {
return NULL;
}
}
if (!TAILQ_EMPTY(&c->partial_msinfoq)) {
/* 如果不为空,则从partial slab队列里面取一个slab, _slab_get_item在下面定义*/
return _slab_get_item(cid);
}
.....
if (!TAILQ_EMPTY(&free_msinfoq)) {
/* 如果parital 为空则从free slab队列里面取一个,放到partial slab队列*/
sinfo = TAILQ_FIRST(&free_msinfoq);
ASSERT(nfree_msinfoq > 0);
nfree_msinfoq--;
TAILQ_REMOVE(&free_msinfoq, sinfo, tqe);
// 插入到partial slab队列
TAILQ_INSERT_HEAD(&c->partial_msinfoq, sinfo, tqe);
...
/* 仍然进入从partial slab队列获取的逻辑, 在下面函数 */
return _slab_get_item(cid);
}
}
static struct item * _slab_get_item(uint8_t cid) {
...
// cid是class id, 指的是在cid这层分配slab.
c = &ctable[cid];
// 获取第一个partial slab info
sinfo = TAILQ_FIRST(&c->partial_msinfoq);
// 这个slab应该是不为满的状态
ASSERT(!slab_full(sinfo));
/* 拿到slab地址 */
slab = slab_from_maddr(sinfo->addr, true);
/* 从partial slab分配一个item */
it = slab_to_item(slab, sinfo->nalloc, c->size, false);
it->offset = (uint32_t)((uint8_t *)it - (uint8_t *)slab);
it->sid = slab->sid;
sinfo->nalloc++;
/* 分配之后,判断slab是否满了, 如果满了,放到full slab队列中 */
if (slab_full(sinfo)) {
/* move memory slab from partial to full q */
TAILQ_REMOVE(&c->partial_msinfoq, sinfo, tqe);
nfull_msinfoq++;
TAILQ_INSERT_TAIL(&full_msinfoq, sinfo, tqe);
}
}
4.5 slab空洞问题
我们细心看一下 _slab_get_item函数,不难发现每次都是从Slab,末端开始分配。也就是说,如果item删除,
我们并不会重新利用,相当于这个item只有在内存slab耗尽时,刷到磁盘slab才会重新利用,这样这个带有空洞的slab
被刷到磁盘,也就是磁盘的数据也会有空洞, 不仅仅是内存刷到磁盘的slab造成空洞,直接删除磁盘slab里的item,也会
有空洞,造成空洞的过程类似下面:
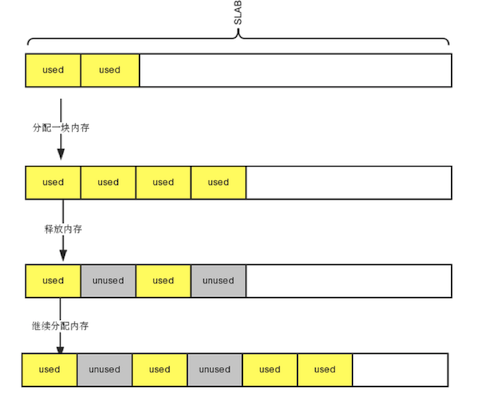
对于内存空洞,解决方案可以,对每个slab增加一个队列,记录空洞地址,使用时,优先从空洞队列分配,无空洞时, 从slab后面分配。同时放回slab时,如果是最后一个分配,直接放回slab, 否则放到空洞队列。
NOTE: 上面说的是针对内存空洞,不包含磁盘slab,因为fatcache主要是使用磁盘slab, 如果对每个磁盘slab, 增加空洞队列,可能会耗掉不少内存,需要提前评估。
注:这个应该并不是个“问题”,而是个trade-off的design。如果跟原作者所说的去额外维护一个free-slot-lits来track这些位置,即放弃了原设计的append的策略,带来的问题就是新和旧的数据被写入到同一个slab中,这样的混合的slab如果在生命周期特征比较明显的负载上,原始的FIFO的效果肯定就差很多了。尤其是在用大容量的SSD做backend的背景下,space cost应该是个弱考虑因素。 (grayxu on 2021/11/3)
the end
看完这篇, 应该要理解的几个东西:
1. slab 和 slabclass
2. slab 三种状态,以及三种状态的转换
3. fatcache不仅有内存slab还有磁盘slab.
接下来讲一下,另外一个fatcache很核心的东西,索引
索引机制
为什么要有索引机制?
fatcache的数据大部分在磁盘,只有小部分在内存中。查找一个key, 如果没有索引,每次都要到磁盘做查找,效率很低, 而且会有多次磁盘读。有了索引之后,在索引记录key, 以及数据所在的位置。查找时,只需判断索引是否存在,如果存在, 直接根据记录的磁盘位置,读取数据,最多只有一次读IO, 如果内存中找不到索引,说明key不存在,直接返回空。
fatcache在启动的时候,会根据设定索引的最大空间,然后把索引全部初始化放到索引的空闲列表。
1) 当set一个key-value的时候,fatcache会从索引的空闲队列中,拿出一个索引,然后记录key的sha1加密值以及数据存放的位置。
2) 当get一个key的时候, 先把key转为sha1值,然后从索引表里面找到索引项,然后读到数据。
3) 当删除一个数据,只需要把索引直接干掉。不需要真正的删除数据,下次过来就不知道索引,也会找不到数据,空出的空间会重新利用。
我们配置那一节有说到,-i就是用来配置索引的大小,单位是M,默认64M, 在64bit操作系统,每个索引占用的是44byte,
也就是能容纳100多万的k-v, 当索引用完,就会引发剔除老数据,回收索引。
我们可以先来看一下索引(itemx)的定义,在fc_itemx.h里面
struct itemx {
// 队列指针
STAILQ_ENTRY(itemx) tqe; /* link in index / free q */
// key的sha1加密值,如果sha1一样,认为是同一个key.
uint8_t md[20]; /* sha1 message digest */
// 这个key对应value的slab id.
uint32_t sid; /* owner slab id */
// 这个ke对应value在slab里面的偏移位置
uint32_t offset; /* item offset from owner slab base */
// 我们协议看到的cas unique值。
uint64_t cas; /* cas */
} __attribute__ ((__packed__));
itemx在hashtable里面的表示如下:
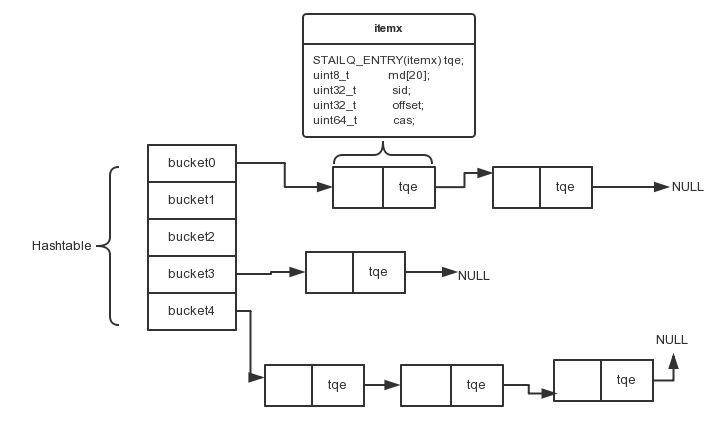
tqe: 我们看到,如果key hash冲突到同一个bucket, 就通过tqe指针,把这些冲突key,组成一个队列。
md: 这是一个长度为20的字符串,这个是key进行sha1后得到的,如果不同key通过sha1得到的相同字符串, 那么认为key相同,不过这个概率很小,基本可以忽略,所以可知,查找是通过对比md来对比,而不是真正的key, 这样可以减少key在itemx的存储空间, 又可以提高比较效率.
sid: 记录这个索引的key, 对应数据所在的slab编号。
offset: 记录这个索引的key,对应数据在slab中的偏移位置。
cas: 每个key都会记录一个unique数值,可以看作版本号,在check and set的时候使用.
通过上面描述,我们可以大概知道,如果查找一个key,应该是先对key做hash, 找到落在哪个bucket, 再对key做sha1,
得到md, 最后遍历这个itemx链表,找到对应itemx, 我们可以看一下代码, 在fc_itemx.c
1 struct itemx *
2 itemx_getx(uint32_t hash, uint8_t *md)
3 {
4 struct itemx_tqh *bucket;
5 struct itemx *itx;
6
7 bucket = itemx_bucket(hash);
8
9 STAILQ_FOREACH(itx, bucket, tqe) {
10 if (memcmp(itx->md, md, sizeof(itx->md)) == 0) {
11 break;
12 }
13 }
14
15 return itx;
16 }
1) 第一步就是通过itemx_bucket找到key所在hashtable里面的bucket,也就是一个itemx队列的头部
2) 第二部通过 STAILQ_FOREACH遍历整个itemx链表,找到md值一样的索引,返回。
所有的key都是转为sha1值, 如果有不同key, 得到一样的sha1值, 那么老的key会被覆盖,不过这个概率很小,
也是不影响使用,因为作为cache, 本身就会有剔除,这个可以看作是一种剔除.
根据itemx读数据
上述的过程是根据key找到了对应的itemx(索引), 而我们真正的数据是存储在slab中,接下来看看如何通过itemx找到对应数据。
我们来看看,fatcache里面处理一次get的过程,代码来自'fc_request.c',
static void
req_process_get(struct context *ctx, struct conn *conn, struct msg *msg)
{
struct itemx *itx;
struct item *it;
/* 上面解释过的函数, 先找到索引 */
itx = itemx_getx(msg->hash, msg->md);
/* 如果找不到索引,说明key不存在,直接返回. */
if (itx == NULL) {
...
rsp_send_status(ctx, conn, msg, type);
return;
}
/* 如果存在就读取到对于的item,我们下面细看一下 */
it = slab_read_item(itx->sid, itx->offset);
/* 如果读不到item是server异常,返回错误 */
if (it == NULL) {
rsp_send_error(ctx, conn, msg, MSG_RSP_SERVER_ERROR, errno);
return;
}
/* 判断是否过期 */
if (item_expired(it)) {
rsp_send_status(ctx, conn, msg, MSG_RSP_NOT_FOUND);
return;
}
/* 数据存在而且没有过期, 就返回 */
rsp_send_value(ctx, conn, msg, it, itx->cas);
}
1) 先找索引(itemx), 如果有索引,说明数据存在,用slab_read_item读取。
2)读到数据后,item_expired判断有没有过期。
3)没有过期的话,就通过rsp_send_value拼装成mc的返回结构数据,返回。
下面是具体slab_read_item实现:
struct item *
slab_read_item(uint32_t sid, uint32_t addr)
{
struct slabclass *c; /* slab class */
struct item *it; /* item */
struct slabinfo *sinfo; /* slab info */
int n; /* bytes read */
off_t off; /* offset to read from */
size_t size; /* size to read */
off_t aligned_off; /* aligned offset to read from */
size_t aligned_size; /* aligned size to read */
ASSERT(sid < nstable);
ASSERT(addr < settings.slab_size);
/* 根据sid找到slab info, sinfo是一个大数组,存放memory slab和disk slab的所有slab info. */
sinfo = &stable[sid];
/* 根据slab info里面记录slab info所在的slab class id, 找到对应slabclass */
c = &ctable[sinfo->cid];
size = settings.slab_size;
it = NULL;
/* slab 在内存里面 */
if (sinfo->mem) {
/* 计算slab在所在的位置+ key所在slab的偏移,计算item的位置 */
off = (off_t)sinfo->addr * settings.slab_size + addr;
/* 把item拷贝到readbuf */
fc_memcpy(readbuf, mstart + off, c->size);
it = (struct item *)readbuf;
goto done;
}
/* 如果item在磁盘,注意,读磁盘可能是设备,需要对齐读的地址 */
off = slab_to_daddr(sinfo) + addr;
/* item地址其实地址对齐到512的整数倍 */
aligned_off = ROUND_DOWN(off, 512);
/* item的长度对齐到512的整数倍 */
aligned_size = ROUND_UP((c->size + (off - aligned_off)), 512);
/* 读取item的数据 */
n = pread(fd, readbuf, aligned_size, aligned_off);
if (n < aligned_size) {
log_error("pread fd %d %zu bytes at offset %"PRIu64" failed: %s", fd,
aligned_size, (uint64_t)aligned_off, strerror(errno));
return NULL;
}
it = (struct item *)(readbuf + (off - aligned_off));
done:
/* 数据正确性校验 */
ASSERT(it->magic == ITEM_MAGIC);
ASSERT(it->cid == sinfo->cid);
ASSERT(it->sid == sinfo->sid);
return it;
}
我们可以看到读取item,经历了下面的几个过程:
- 先根据itemx里面的sid, 作为下标,在stable, 也就是slab info table,里面找到slab info.
- 根据slab info 里面的mem字段判断,item是在内存还是disk。
- 然后根据sid所在slab class id, 计算item长度, 计算item的长度,从内存或者disk读取到数据,返回.
总结上面, 需要找到key,需要找索引,然后找到slab info, 然后根据slab info找到slab, 再读取数据.
itemx 耗尽
参数配置 这一节里面-i, --max-index-memory=N, 就是最大索引的使用内存,默认64M,在64bit操作系统,
每个索引占用44bytes, 如果当key的数量超过索引的最大数目时,就会产生剔除。
过程大概如下:
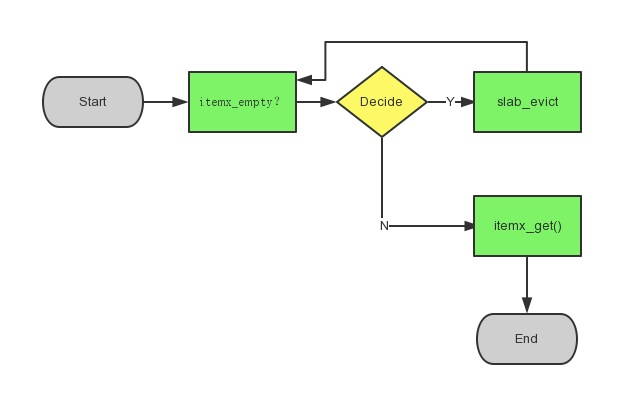
看一下fatcache里面的实现, 看一下fc_slab.c,可以看过,要分配item之前,会先判断索引是否已经用完,
如果用完的话,会把最旧的slab剔除,回收索引.
struct item *
slab_get_item(uint8_t cid)
{
...
if (itemx_empty()) {
/* item 索引使用耗尽,应该做一些剔除 */
status = slab_evict();
if (status != FC_OK) {
return NULL;
}
}
...
}
我们已经说过,索引数量是用户可配置的,如果索引耗完,就会通过slab_evict来把老的slab剔除,回收索引。
slab剔除函数我们后续再来详细说。
The End
这一节对itemx(索引)进行比较详细的介绍,包括在索引的作用,用法等。 还有一个注意的点,剔除slab的时候, 只是回收索引,然后将slab放到空闲slab队列,并没有真正擦除slab的数据,直接在下次写直接覆盖,减少擦除slab的时间。
我们知道了slab机制,索引机制,相当于知道数据如何存储,如何查找数据。接下来我们说一下Epoll, 对上面说过的所有东西重新梳理一下。
下一节 Epoll
网络框架
epoll
fatcache使用Epoll作为网络IO事件通知机制,也只支持Epoll。从代码上来说, fatcache和twitter的另外一个项目twemproxy代码相似度非常高,像message, mbuf, queue等基础数据结构, 都是直接使用,但twemproxy后面支持了其他的网络IO模型,而fatcache没有支持,也许是twemproxy在比较后面才支持。
这里稍微介绍一下epoll和其他IO模型如Poll, Select的一些区别:
Epoll: 和FreeBSD的kqueue类似,epoll监听多个fd的时候,使用的是红黑树,查找操作是O(1), 而Select, Poll是轮询,所以都是O(N), 就是说当监听10万个fd, Select, Poll需要从用户态拷贝大量fd到内核态,轮询一遍,这很费时。
Select: select对于监听的fd数目是有限制的,最大是FD_SETSIZE, 这个可以手动调整,当fd数目超过FD_SETSIZE时,
就会产生错误。
Poll: poll跟select基本一样,除了不对fd数目做限制之外。
需要注意的是,Epoll有两种触发模式: LT(level trigger)和ET(edge trigger). 两种方式不同在于: 假设现在有5k数据到来,每次只能读取4k.
LT: 在这种模式下,读取一次之后,还有1k数据未读,后续继续调用epoll_wait, 还是会立即返回fd, 继续读取剩余数据。
ET: 而ET比较有个性,如果这次只读了4k, 没有继续读剩余的1k, 下次epoll_wait不会返回这个fd,除非有写了新数据。
所以,使用ET模式,可能会不小心落掉一些数据,对开发者要求更高。
更加详细的使用方法,建议查看: How to use epoll这篇文章或者直接查看man手册。
fatcache Epoll
我们先对fc_event.c实现的函数都做一遍简单说明:
event_init 创建epoll, 这个函数在fatcache启动的时候调用。每个fatcache实例只会有一个epoll对象。
后续有需要监听的fd, 都是添加到到这个epoll对象。
int
event_init(struct context *ctx, int size)
{
int status, ep;
struct epoll_event *event;
ASSERT(ctx->ep < 0);
ASSERT(ctx->nevent != 0);
ASSERT(ctx->event == NULL);
/* 创建epoll对象 */
ep = epoll_create(size);
if (ep < 0) {
log_error("epoll create of size %d failed: %s", size, strerror(errno));
return -1;
}
/* 提前为Epoll的事件申请空间 */
event = fc_calloc(ctx->nevent, sizeof(*ctx->event));
if (event == NULL) {
status = close(ep);
if (status < 0) {
log_error("close e %d failed, ignored: %s", ep, strerror(errno));
}
return -1;
}
/* 把epoll相关数据结构都是放在ctx里面 */
ctx->ep = ep;
ctx->event = event;
return 0;
}
event_deinit 销毁epoll对象,这个只有在Fatcache关闭的时候会使用,只是关闭对应fd,比较简单, 自己去看。
event_add_conn: 我们注意到添加epoll的fd, 是包装成connection的形式传递进来。然后添加的监听参数都是
EPOLLIN | EPOLLOUT | EPOLLET, 并把connection放到event.data.ptr, 可以作为事件到来时,回调函数的参数。
int
event_add_conn(int ep, struct conn *c)
{
int status;
struct epoll_event event;
ASSERT(ep > 0);
ASSERT(c != NULL);
ASSERT(c->sd > 0);
/* 监听事件类型是in和out */
event.events = (uint32_t)(EPOLLIN | EPOLLOUT | EPOLLET);
/* connection作为event的data */
event.data.ptr = c;
/* connection的fd添加到epoll */
status = epoll_ctl(ep, EPOLL_CTL_ADD, c->sd, &event);
if (status < 0) {
log_error("epoll ctl on e %d sd %d failed: %s", ep, c->sd,
strerror(errno));
} else {
c->send_active = 1;
c->recv_active = 1;
}
return status;
}
event_del_conn是跟event_add_conn刚好相反,把一个链接的fd从epoll移除,也就是关闭链接。
int
event_del_conn(int ep, struct conn *c)
{
int status;
ASSERT(ep > 0);
ASSERT(c != NULL);
ASSERT(c->sd > 0);
/* 把connection fd从epoll中移除,即不再监听 */
status = epoll_ctl(ep, EPOLL_CTL_DEL, c->sd, NULL);
if (status < 0) {
log_error("epoll ctl on e %d sd %d failed: %s", ep, c->sd,
strerror(errno));
} else {
c->recv_active = 0;
c->send_active = 0;
}
return status;
}
另外两个函数int event_add_out(int ep, struct conn *c); 和 int event_del_out(int ep, struct conn *c); 的作用是,
添加和删除out事件,实现和event_add[del]_conn类似。
最后一个函数event_wait, 之前的实现是初始化和为epoll添加或者删除监听的fd,epoll真正的监听是从event_wait开始。
int event_wait(int ep, struct epoll_event *event, int nevent, int timeout)
{
...
for (;;) {
/* epoll等待事件或者超时 */
nsd = epoll_wait(ep, event, nevent, timeout);
if (nsd > 0) {
/* 有文件事件到来 */
return nsd;
}
if (nsd == 0) {
/* 超时 */
if (timeout == -1) {
log_error("epoll wait on e %d with %d events and %d timeout "
"returned no events", ep, nevent, timeout);
return -1;
}
return 0;
}
if (errno == EINTR) {
continue;
}
log_error("epoll wait on e %d with %d events failed: %s", ep, nevent,
strerror(errno));
return -1;
}
...
}
the end
从上面的代码来看, fatcache在接收到一个Client链接,会生成一个conn结构,添加到epoll里面来, 并开始监听这个连接。
epoll在fatcache里面的实现比较简单,自己看代码应该问题不大。
接下来看一下,fatcache启动流程
fatcache启动流程
到这里我们对fatcache的基础内容,主要是slab, 索引, 网络IO有一个大致的了解。
这一节来看看,fatcache是如何启动的,我们很自然的找到了fc.c里面的main函数。
我们先来看看里面主要做了哪些事情,然后再一一解释:
int
main(int argc, char **argv)
{
rstatus_t status;
struct context ctx;
/* 设置默认参数 */
fc_set_default_options();
/* 从启动命令行里面获取参数,并设置到settings对应的参数 */
status = fc_get_options(argc, argv);
...
/* 后台运行模式 */
if (settings.daemonize) {
status = fc_daemonize(false);
if (status != FC_OK) {
exit(1);
}
}
status = fc_set_profile();
if (status != FC_OK) {
exit(1);
}
/*
* 这里面会初始化一些公用的数据结构, 如mbuf, meesage, conn等队列。
* 时间事件和slab的初始化也是在这个函数。
*/
status = core_init();
if (status != FC_OK) {
exit(1);
}
fc_print();
/* 初始化epoll, 并把server的监听事件添加到epoll中 */
status = core_start(&ctx);
if (status != FC_OK) {
exit(1);
}
for (;;) {
/* 开始处理网络事件,我们上面core_start已经把监听fd,添加到Epoll, 所以到这里会开始监听。 */
status = core_loop(&ctx);
if (status != FC_OK) {
break;
}
}
/* 什么也没做 */
core_stop(&ctx);
return 0;
}
从上面的代码里面我们可以看到,main主要的三个事情:
1. 默认配置参数设置和启动参数解析。
2. 初始化数据结构,包括slab和时间
3. 初始化epoll,并开始监听。
fatcache的main函数跟其它的nosql也差不多,根据用户配置参数,初始化,并开始监听用户请求,太不高贵冷艳了..
配置参数
有哪些参数,可以回去看一下 配置参数. 相关代码实现很简单,不细说。
初始化
core_init里面调用slab_init做的几个主要的事情:
1. slab_init_ctable, 初始化slabcalss table.
2. 根据配置的最大内存slab大小以及磁盘分区大小,将两块分割成slab, 并放到各自的空闲队列。
3. slab_init_stable, 创建并生成slab对应的Slab info table。
记得吧? 前面已经说过了,我们是用slab来管理数据,这里初始化slab。
启动监听
我们先来看看Server如何启动监听:
首先在 main 函数里面调用了core_start
rstatus_t
core_start(struct context *ctx)
{
rstatus_t status;
/* 创建ctx */
ctx->ep = -1;
ctx->nevent = 1024;
ctx->max_timeout = -1;
ctx->timeout = ctx->max_timeout;
ctx->event = NULL;
/* 创建epoll, 并放到ctx全局变量 */
status = event_init(ctx, 1024);
if (status != FC_OK) {
return status;
}
/* server_listen开始把监听fd添加到epoll, 然后开始监听连接事件 */
status = server_listen(ctx);
if (status != FC_OK) {
return status;
}
return FC_OK;
}
接下来看看server_listen, 我们只看一下,如何把server fd添加到epoll。
rstatus_t
server_listen(struct context *ctx)
{
...
struct conn *s;
...
/* 我们可以看到server的fd会被封装成一个connection, 专门做监听的connection */
s = conn_get(sd, false);
...
/* 这里就是把监听的connection的fd添加到epoll */
status = event_add_conn(ctx->ep, s);
/* 删除发送事件监听 */
status = event_del_out(ctx->ep, s);
}
我们可以看到监听的server fd先是被包成fd, 然后再通过event_add_conn添加到epoll, 后面还有一个event_del_out,
因为在event_add_conn里面设置了in和out监听事件, 但是作为专门接收的fd, 不会有out事件,所以这里关闭。
我们可以继续看看conn_get的实现:
struct conn *
conn_get(int sd, bool client)
{
struct conn *c;
/* 创建connection结构体 */
c = _conn_get();
if (c == NULL) {
return NULL;
}
c->sd = sd;
c->client = client ? 1 : 0;
if (client) {
/* client */
c->recv = msg_recv;
c->send = msg_send;
c->close = client_close;
c->active = client_active;
} else {
/* server accept */
c->recv = server_recv;
c->send = NULL;
c->close = NULL;
c->active = NULL;
}
log_debug(LOG_VVERB, "get conn %p c %d", c, c->sd);
return c;
}
上面函数我们看到conn_get是通过第二个参数bool client来决定回调函数,我们这里说的是server监听连接,
所以应该是false, 然后server_recv作为回调函数。
接下去应该是无限循环调用core_loop, epoll的监听事件真正开始,我们来看一下里面的实现:
rstatus_t
core_loop(struct context *ctx)
{
int i, nsd;
/* 等待网络事件触发或者无网络事件就会超时,超时时间为ctx->timeout */
nsd = event_wait(ctx->ep, ctx->event, ctx->nevent, ctx->timeout);
if (nsd < 0) {
return nsd;
}
/* 有事件到来, 则调用core_core执行相应的回调 */
for (i = 0; i < nsd; i++) {
struct epoll_event *ev = &ctx->event[i];
/* core_start 初始化ev->data.ptr 为con */
core_core(ctx, ev->data.ptr, ev->events);
}
return FC_OK;
}
core_core里面实现比较简单,自己去看即可,他会根据到来的事件类型是in还是out, 还决定回调函数,
这个回调函数就是我们上面conn_get里面设置的回调。
由于我们这里是conn是server监听的fd, 不是client, 所以回调函数应该是server_recv, server_recv通过不断调用server_accept,
来接收client发送数据。
for (;;) {
sd = accept(s->sd, NULL, NULL);
if (sd < 0) {
...
}
break;
}
...
/* 为到来的请求,创建一个connection */
c = conn_get(sd, true);
...
/* 开始监听这个连接 */
status = event_add_conn(ctx->ep, c);
...
return FC_OK;
我们上面可以看到, server正确接收到一个用户请求后,会调用conn_get来创建一个连接,
然后通过event_add_conn添加到Epoll监听。
the end
我们这一节说了fatcache启动的时候做了哪些事情,然后对如何启动监听做了比较详细的讲解。
最后讲到了server开始监听,接受client的连接,并加入到epoll的监听列表,接下去,client就可以和 server进行通讯了。
我们下一节来说一下, 用户数据接收和解析
用户数据接收和解析
我们在上一节fatcache启动流程, 可以看到,fatcache开始监听之后,如果有新client到来,就会通过event_add_conn,
把一个连接添加到epoll的监听列表,开始监听client发送过来的请求数据, 并设置接收和发送回调函数分别为msg_recv和msg_send。
接收到和要发送的数据都会放到一个叫struct msg的结构中。
Msg
fatcache所有接收数据或者发送数据都会放在strcut msg的mbuf链表中,一个msg代表一个request或者response。
下面是fc_message.h中 struct msg的主要成员:
struct msg {
TAILQ_ENTRY(msg) c_tqe; /* 指向下一个处理完的请求 */
TAILQ_ENTRY(msg) m_tqe; /* 指向下一个发送的msg */
uint64_t id; /* 当前msg 对应的id */
struct msg *peer; /* 对应的msg, 如果是当前msg是request,peer指向即为response */
struct conn *owner;/* msg所属的connection, 每一个connection可能会处理多个request */
struct mhdr mhdr; /* 接收或者发送数据存放的链表 */
uint32_t mlen; /* 接收或者发送数据的长度 */
int state; /* 当前解析到的状态 */
uint8_t *pos; /* 当前解析到的buf位置 */
uint8_t *token; /* 存放当前解析的token */
msg_parse_t parser; /* 解析msg的函数,在_msg_get函数里面设置 */
msg_parse_result_t result; /* 解析的结果 */
msg_type_t type; /* 解析到的命令类型,get/gets/del.. */
uint8_t *key_start; /* key存放的开始地址 */
uint8_t *key_end; /* key存放的结束地址 */
uint32_t hash; /* key的hash值 */
uint8_t md[20]; /* key进行sha1加密的结果 */
/* 协议数据 */
uint32_t flags; /* flags */
uint32_t expiry; /* expiry */
uint32_t vlen; /* value length */
uint32_t rvlen; /* running vlen used by parsing fsa */
uint8_t *value; /* value marker */
uint64_t cas; /* cas */
uint64_t num; /* number */
/* 如果协议切分成多个fragments是用到,如get/gets多个key */
struct msg *frag_owner; /* owner of fragment message */
uint32_t nfrag; /* # fragment */
uint64_t frag_id; /* id of fragmented message */
err_t err; /* 遇到错误? */
unsigned error:1; /* error? */
unsigned request:1; /* request? or response? */
unsigned quit:1; /* 是否为quit命令 */
unsigned noreply:1; /* 是否需要把结果返回给客户端 */
unsigned done:1; /* 处理是否结束? */
unsigned first_fragment:1;/* 第一个处理的片段? 比如get/gets需要在开始输出VALUE常量,需要用这个标志 */
unsigned last_fragment:1; /* 最后一个处理的片段? 返回结束时,需要用到这个标志 */
unsigned swallow:1; /* swallow response? */
}
1) 如果msg->request == 1,表示这个msg是request, 对应这个mbuf链表存放就是接收的数据.
2) 如果msg->requeset == 0, 表示这个msg是response, 对应mbuf链表存放的是发送数据。
request和response如何对应?
struct msg中有个peer字段, request msg 的peer就是response msg, 相反response msg的peer为 request msg.
每个msg一次只能存储一个key, 如果是 get|gets key1, key2, ..., keyn 就会被切分成多个msg.
这些请求处理后会放到输出队列,触发写事件,开始调用写回调数据来返回数据到客户端.
接收client数据
我们来看一下,fc_message.c里面msg_recv的实现:
rstatus_t
msg_recv(struct context *ctx, struct conn *conn)
{
...
conn->recv_ready = 1;
do {
// 创建一个msg
msg = req_recv_next(ctx, conn, true);
if (msg == NULL) {
return FC_OK;
}
// 接收并开始处理请求数据
status = msg_recv_chain(ctx, conn, msg);
if (status != FC_OK) {
return status;
}
} while (conn->recv_ready);
return FC_OK;
}
上面代码, req_recv_next 创建一个request msg, 进入msg_recv_chain开始接收数据并处理请求。
下面看一下msg_recv_chain的详细实现.
1) 接收数据
// 判断最后mbuf是否还有剩余空间, 如果没有创建一个新的buf,放到队列
mbuf = STAILQ_LAST(&msg->mhdr, mbuf, next);
if (mbuf == NULL || mbuf_full(mbuf)) {
mbuf = mbuf_get();
if (mbuf == NULL) {
return FC_ENOMEM;
}
mbuf_insert(&msg->mhdr, mbuf);
msg->pos = mbuf->pos;
}
ASSERT(mbuf->end - mbuf->last > 0);
msize = mbuf_size(mbuf);
// 开始接收数据
n = conn_recv(conn, mbuf->last, msize);
2) 处理请求数据
接收完数据之后,进入msg_parse 开始处理请求数据:
static rstatus_t
msg_parse(struct context *ctx, struct conn *conn, struct msg *msg)
{
rstatus_t status;
if (msg_empty(msg)) {
/* no data to parse */
req_recv_done(ctx, conn, msg, NULL);
return FC_OK;
}
//调用fc_memcache.c里面的memcache_parse_req函数开始根据协议处理数据
msg->parser(msg);
// 协议解析结果
switch (msg->result) {
// 解析到完整的命令,开始处理
case MSG_PARSE_OK:
status = msg_parsed(ctx, conn, msg);
break;
// 需要解析成多个fragment, 如get/gets多个key,需要被分成多个msg来处理
case MSG_PARSE_FRAGMENT:
status = msg_fragment(ctx, conn, msg);
break;
// 不完整的字段,需要把一部分接收数据放到下一个mbuf的开始,重新解析
case MSG_PARSE_REPAIR:
status = msg_repair(ctx, conn, msg);
break;
// 数据不完整,需要重新接收数据
case MSG_PARSE_AGAIN:
status = FC_OK;
break;
default:
status = FC_ERROR;
conn->err = errno;
break;
}
return conn->err != 0 ? FC_ERROR : status;
}
我们看到协议解析会有下面几种状态:
1)
MSG_PARSE_OK: 根据协议解析到一条完整的请求,接下去可以处理请求。
2)
MSG_PARSE_FRAGMENT: 需要分成多个碎片处理, 我们前面说到,每个request msg只能存储一个key, 所以像get/gets带有多个key的协议, 需要被切分成多个msg, 这时候状态就是fragment.
3)
MSG_PARSE_REPAIR: 除了VALUE之外的其他字段,比如exprietime是123456,现在接收到123, 456在下一个mbuf, 就需要通过repair, 把123移动到下一个mbuf, 并重新解析, value是允许跨mbuf, 只会返回again状态,不是repair状态。
4)
MSG_PARSE_AGAIN: 当协议数据不完整,返回again状态.
5)
default: 不是上面四种解析状态,就是出错,直接关闭连接,因为mc协议是通过空格来切分数据,前面数据出错,后续数据会受影响,直接关闭连接。
上面已经介绍了,接收和解析完数据之后,开始处理请求。
msg_parsed会调用req_recv_done, 接着req_recv_done 调用req_process 开始处理请求,并返回数据。
具体每种类型命令如何处理,我们在下一节命令处理 详细介绍。
命令处理
我们前面已经说到,当fatcache接收到一次完整请求之后,就会到fc_request.c里面的req_process函数,开始处理请求。
我们开始讲解一些各个命令的在fatcache的处理:
1) GET/GETS
GET/GETS 都是由req_process_get同一处理,只是返回的时候,GETS会多返回cas字段。
static void
req_process_get(struct context *ctx, struct conn *conn, struct msg *msg)
{
struct itemx *itx;
struct item *it;
/* 根据md获取索引 */
itx = itemx_getx(msg->hash, msg->md);
/* 索引为空,说明这个key不存在 */
if (itx == NULL) {
msg_type_t type;
/*
* get/gets多个key, frag_id不为空。
* 如果是单个key或者是多个key的最后一个key, 直接返回 "END\r\n"
* 如果是多个key, 返回EMPTY.
*/
if (msg->frag_id == 0 || msg->last_fragment) {
type = MSG_RSP_END;
} else {
type = MSG_EMPTY;
}
/* 返回 */
rsp_send_status(ctx, conn, msg, type);
return;
}
/* 从memory或者disk读取value */
it = slab_read_item(itx->sid, itx->offset);
if (it == NULL) {
rsp_send_error(ctx, conn, msg, MSG_RSP_SERVER_ERROR, errno);
return;
}
/* item是否过期? */
if (item_expired(it)) {
rsp_send_status(ctx, conn, msg, MSG_RSP_NOT_FOUND);
return;
}
/* 发送value */
rsp_send_value(ctx, conn, msg, it, itx->cas);
}
-
获取索引是通过key得到一个20bit的sha1值,放在md[]里面,在根据这个值,计算hash,找到它在hashtable里面的bucket。
-
如果有索引,根据索引得到数据所在位置,然后通过
slab_read_item读取item。 -
接着通过
item_expired判断是否过期. -
最后通过
rsp_send_value根据协议拼装发送回client.
Note: slab_read_item 通过索引里面的mem判断数据在内存还是在磁盘,如果在内存,直接拷贝,如果在磁盘,需要读磁盘,由于读磁盘是direct io, 所以需要对读地址进行对齐。
下面是GET/GETS的示意图
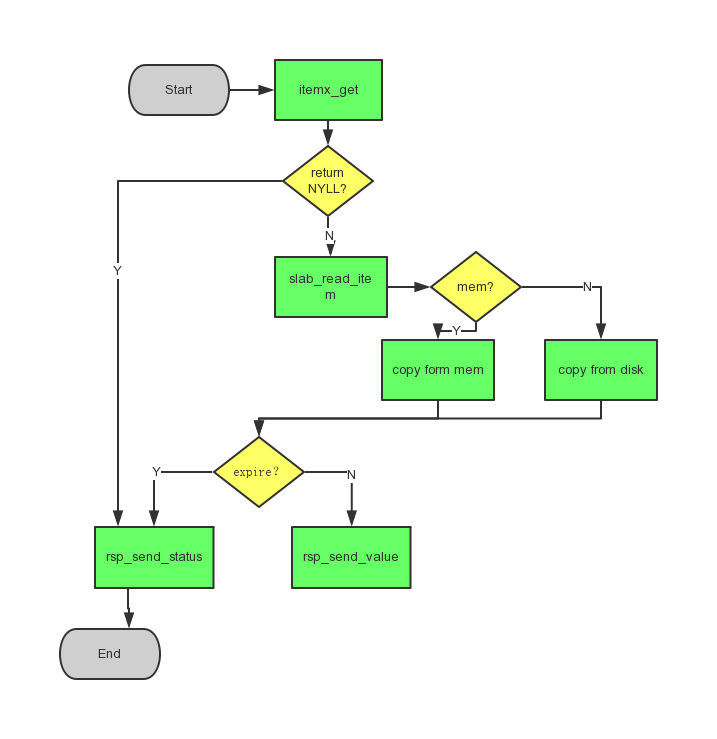
2) DELETE
fatcache的删除非常简单,直接把索引删除即可,没有索引就找不到数据,不用真正去擦除内存或者磁盘里面的数据,而这些空间会在内存或者磁盘不够的时候,重新被写。这个设计很巧妙,不用擦除,下次直接覆盖。下面是delete的实现:
static void
req_process_delete(struct context *ctx, struct conn *conn, struct msg *msg)
{
bool found;
// 删除索引
found = itemx_removex(msg->hash, msg->md);
if (!found) {
rsp_send_status(ctx, conn, msg, MSG_RSP_NOT_FOUND);
return;
}
rsp_send_status(ctx, conn, msg, MSG_RSP_DELETED);
}
我们看到,只有简单通过itemx_removex 从索引表里面删除索引,直接返回。
3) SET
添加数据的时候比较特殊, 我们之前说过(Ps: 之前说了那么多,鬼记得你说什么),写入数据时,一定是写在内存。 所以我们写一段时间后,会发现内存slab耗尽,这时候会把最老的slab交换到磁盘,空出一个内存slab, 让新数据写入。
所以添加新数据可能会经历下面几步。
1) 如果之前key已经存在? 删除索引
2) 是否还有索引可用? 有, 直接返回。否则,通过slab_evict将磁盘最老的slab剔除,回收索引。
3)是否还有内存slab item可用? 有,返回item。 否则, 通过slab_drain把最老的内存slab交换到磁盘.
4) 交换磁盘过程中,如果没有空闲的磁盘slab, 同样通过slab_evict, 把最老的磁盘slab的数据剔除。
由于这块代码比较多,这里就不列出代码,把大概流程画出来,有兴趣自己去看代码。
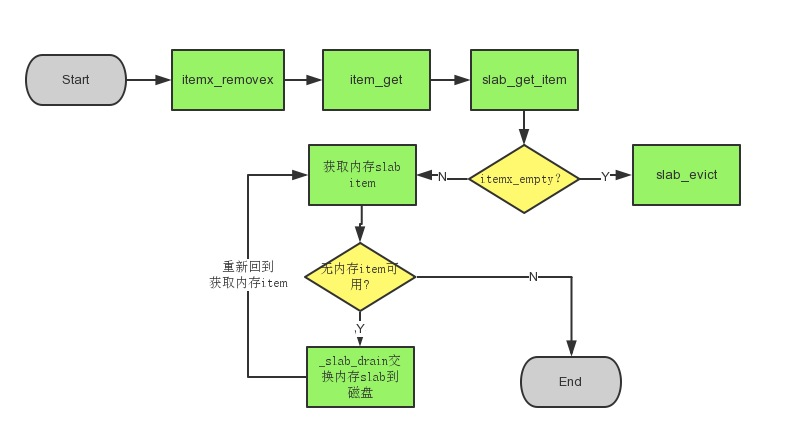
还有其他一些如: Add, Replace, Append..等等命令,比较简单,大家看懂上面的处理,再去看其他命令处理都不是问题。 这里为了限制篇幅,我们也不完全解释所有命令。
The End
这一节主要说了get、set、delete的具体处理方式。我们前面已经讲了, slab, 索引(itemx), 网络, 数据接收以及协议解析, (除了具体解析之外,由于主要根据mc协议格式,逐个解析字段,没什么好说), 我们这里说了具体的处理,整个完整的fatcache也就这么多内容了。
下一节 结束篇
结束篇
最后对fatcache的特点做一下总结:
1) 单线程, 实现更加简单,但性能没多线程的好.
2) 无随机写,通过slab管理,转化为顺序写,减少小块IO写,无写放大
3) 随机读, 读性能没有写性能好
4) 索引管理, 快速判断数据是否存在,同时可以快速定位数据的位置,最多只有一次IO
5) slab分为内存和磁盘两种, 读写磁盘是direct io,不会使用pagecache, 内存slab更多是写缓冲的角色。
fatcache很适合用在那些对于数据响应时间并不是要求太高,最好是介于全内存和DB之间,同时数据量比较大的场景。
该笔记中还有很多没有提到的内容,如果有兴趣,欢迎一起讨论。
Contact
Sina Weibo: @改名hulk
Gmail: hulk.website@gmail.com
Blog: www.hulkdev.com