Disaggregated Memory is currently a hot topic in systems research, and distributed large-capacity memory clearly requires system-level reliability strategies. While replication has always been a default choice, with many related works, including recent ones like SWARM@SOSP'24, erasure coding is also an option. This article lists existing EC+DM works.
IPDPS '21 F-Write: Fast RDMA-supported Writes in Erasure-coded In-memory Clusters
Previous works like octopus@ATC'17 have reconstructed network I/O (like RPC) using one-sided verbs.
This paper focuses on the scenario of RDMA+EC, where updates are slow due to I/O amplification.
- Implements a 2PC scheme for EC using one-sided writes.
- Essentially, it's octopus's one-sided RPC.
- Then, it builds on top of this with speculative updates, implementing flying data merging (to merge multiple submissions) for EC.
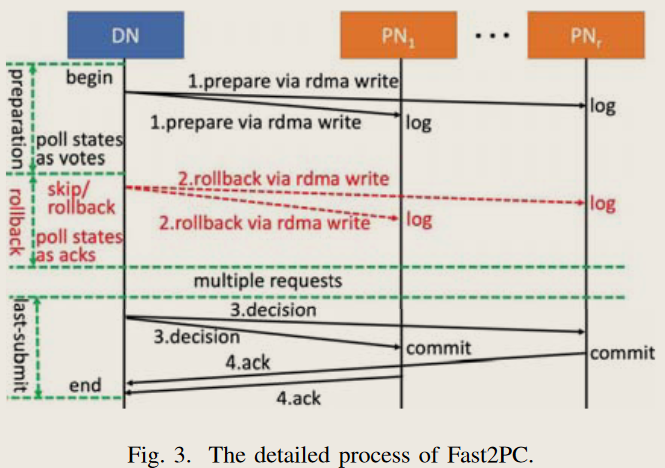
No NIC info provided.
FAST '22 Hydra: Resilient and Highly Available Remote Memory
SymbioticLab, available on arXiv since 2019.
Problems:
- High Latency: EC-based remote memory solutions cannot meet microsecond-level latency requirements due to encoding overhead, straggler issues, interrupt overhead, and data replication overhead.
- Low Availability: Existing fault tolerance mechanisms based on replication and erasure coding can easily lead to data loss in the event of correlated failures due to the random placement of coding groups.
Challenges:
- Encoding overhead
- Splitting amplifies tail latency.
- Context switching overhead
- Copy overhead
- Placement strategy is not good for simultaneous errors.
Design:
- Asynchronous encoded writes and delayed binding reads to hide latency.
- Asynchronously Encoded Write: Fragments are not queued; similar to late binding for writes, only confirming after the first $k$ requests return.
- Late Binding: Basically, multi-fragment reads in an EC cache.
- In-Place Coding minimizes data copying. Unregisters after receiving k splits to prevent overwriting by subsequent splits. [Will there be no registration performance issues?].
- Run-to-Completion avoids context switching because the latency is very low.
- The CodingSets algorithm improves availability by carefully designing the placement strategy of coding groups, reducing the probability of data loss under correlated failures. [A classic EC problem, from CopySet].
Open Source: https://github.com/SymbioticLab/hydra
Is it really a good idea to use late binding so extensively?
- Increased number of network packets (could RDMA verb scalability be limited?).
- Higher computational pressure (mainly due to increased latency, but throughput is still line rate (can it be pipelined?).
OSDI '22 Carbink: Fault-tolerant far memory
Follow-up work to Hydra@FAST'22. The problem is that due to self-coding partitioning for a single object,
- Multiple network I/O operations are required to reconstruct a page.
- But late binding can be used, so it's okay. It seems like just a granularity trick.
- Computation is centralized and cannot be offloaded to remote nodes.
- But for DM, this is a false need. However, what about potential RNIC offload?
Design:
- Therefore, it abstracts the concept of a span, where each span consists of multiple pages with similar object sizes. Then, cold/hot determination, grouping (clock algorithm), and eviction are performed asynchronously and transparently. [Like slab]. Note that the unit of processing here is clearly different from Hydra.
- There are some system designs, but a lot of related work exists, especially in slab-related clustering.
- And from an EC perspective, one is self-coding and the other is cross-coding, making direct comparison difficult.
- Asynchronous GC compaction (EC stripes).
- Hydra does not have this issue because a set of stripes forms an object, so their lifecycles are tied together.
- Triggered by swap-out, and consistent completion needs to be ensured. 2PC is a naive approach.
- EC-batch local
- EC-batch remote (offload parity calculation to remote nodes)
"To reconstruct a span, a compute node only needs to contact a single memory node storing that span."
TPDS '23 Enabling Efficient Erasure Coding in Disaggregated Memory Systems
USTC ADSL
This work begins to focus on the problem from a DM perspective (i.e., purely memory nodes).
As one-sided RDMA latency drops to the microsecond level, encoding overhead degrades the performance of DM with EC. To enable efficient EC in DM, we thoroughly analyzed the coding stack from the perspectives of cache efficiency and RDMA transfer.
DM is a subset of RDMA, where local memory is more limited or only acts as a cache. A natural approach is to use pipelining, but the challenges are:
- Sub-stripe segmentation affects cache efficiency.
- Dedicated kernel coding reduces cache pollution.
- How object size impacts pipeline scheduling issues.
MicroEC significantly reduces latency variation by reusing auxiliary encoding data. For example, it reduces the P99 latency of writing a 1 KB object by 27.81%. It optimizes the coding workflow and coordinates encoding and RDMA transfer through an exponential pipeline while carefully adjusting coding and transmission threads to minimize latency.
Note that this work only focuses on objects larger than 64KB.
Design:
- Reuse auxiliary data.
- Propose efficient data structures to support the design.
- A non-blocking pipeline, and carefully adjust the coding and transmission threads.
The sub-stripe size is a trade-off: larger sizes lead to poor performance (head-tail latency amplification degradation), while smaller sizes increase network latency (but isn't it possible to overlap?).
This work has a more EC-centric flavor. It focuses on reusing auxiliary encoded data, using an exponential pipeline, and carefully adjusting coding and transmission threads.
Open Source: https://github.com/ADSL-EC/MicroEC
I don't understand why they chose to use Java's Crail-1.3 for the system. It's surprising to use a system with a built-in GC for something so sensitive. No wonder it can only handle large objects.
SOSP '24 Aceso: Achieving Efficient Fault Tolerance in Memory-Disaggregated Key-Value Stores
Pengfei Zuo, DM KVS + EC
Checkpoint for index, EC for KV pair
Differential checkpointing scheme, version recovery method, space reclamation mechanism based on differences, and hierarchical recovery scheme.
Challenges:
- Checkpoint network overhead, rollback leads to loss of recently submitted KV pairs.
- EC introduces GC and recomputation.
- Memory node recovery is slow due to computation (pure decoding recovery issue?).
- Checkpoint transfer can interfere with performance.
Solution:
- Differential Checkpointing for Index: RNIC IOPS are limited. By reducing the bandwidth consumed by checkpoint transfers, Aceso reduces the performance interference of the checkpoint mechanism.
- Calculate the index delta -> LZ4 -> write to MN -> adjacent MN decompresses and then XOR updates. (The atomicity guarantee here comes from the fact that the index being written will not be included in this checkpoint).
- After rolling back the checkpoint, you need to scan to match KV pairs. Some RDMA CAS tricks are used to apply versions to slots.
- Version-based recovery method:
- Index Slot Versioning: The slot is extended to ensure the latest version. By reading the latest checkpoint and reprocessing recent KV pairs, Aceso ensures that the index can recover to the latest and consistent state after fault recovery using RDMA CAS.
- Index Versioning implements further strategies to accelerate recovery (narrowing the scan range, etc.).
- Offline Erasure Coding for KV Pairs: Offline EC, leveraging the linear properties of X-code erasure codes, Aceso implements an efficient space reclamation mechanism for old KV pairs with almost no overhead.
- Offline mainly means that the MN performs the operation in the background. First, write everything to the MN, then the MN's CPU performs encoding in the background.
- Metadata records the role, validity, bitmap, etc., similar to previous DM hash work. Then, it uses a slab-like management.

- Hierarchical Recovery Scheme: By prioritizing the recovery of critical data (such as the index), Aceso ensures fast recovery of KV storage functionality, minimizing user disruption.
- Metadata is directly replicated, the index is recovered to a previous version using checkpoints, and then KV pair versions are scanned.
- Block regions are recovered using EC, while parity is recovered in the background (delta merging occurs here).
- By default, it optimizes pipelining of RDMA reads and decoding, as well as doorbell batching.
CX3 cluster of CloudLab
Aceso achieves significant throughput improvements in write requests (INSERT, UPDATE, DELETE). Among them, the improvement in DELETE requests is the most significant, reaching 2.67 times.
The baseline is the replicated FUSEE@FAST'23, but many improvements come from the significantly reduced overhead of the index after checkpointing.
Random thoughts:
- …