About offloading memory data movement to DMA or DSA engines.
What is DMA: https://jianyue.tech/posts/dma/
Pros:
- offloading for async ops
- less cache polution
- less CPU cycles (less mem io stalls)
Cons:
- higher latency
- resource management (addr translation, …)
- bandwidth limited
note: partially translated by ChatGPT
IPDPS '07 Designing Efficient Asynchronous Memory Operations Using Hardware Copy Engine: A Case Study wi
OSU's work, K. Vaidyanathan W.Huang L. Chai D. K. Panda
DMA copy offload:
- Reduction in CPU Resources and Better Performance
- Computation-Memory Copy Overlap
- Avoiding Cache Pollution Effects
But concern about:
- a single transfer cannot span discontinuous physical pages
- source and dest overlap
- Bus CC
They developed a DMA engine in the kernel for copying, which can also be extended for IPC. They also considered issues such as alignment, locking buffer, and multiple DMA channels.
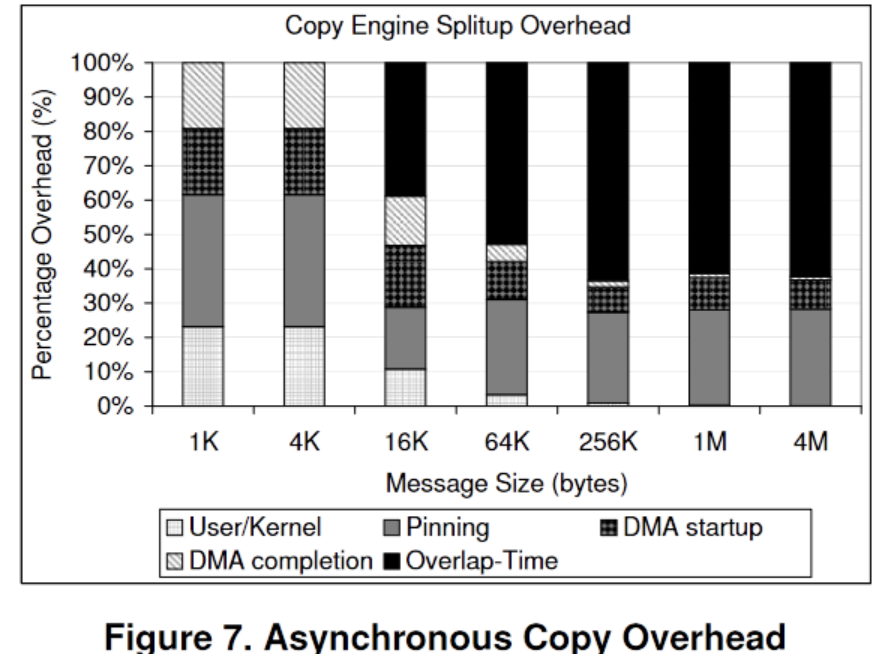
Some experimental results:
- Setup: Intel 3.46 GHz processors and 2MB L2 cache system with SuperMicro X7DB8+ motherboards that include 64-bit 133 MHz PCI-X interfaces. The machine is connected with an Intel PRO1000Mbit adapter. We used the Linux RedHat AS 4 operating system and kernel version 2.6.9-30. It doesn't mention memory, but it seems relevant.
- Regarding data in the hot cache, CPU memcpy completely dominates.
- On the contrary, for 16KB, 4-channel DMA is better than the CPU.
- Beyond 2MB, the CPU lags behind DMA in terms of bandwidth.
- The effect of overlap testing is more evident above KB, around 0.3-0.4 at 1KB. When the size is too small, there is no effect due to the overhead of DMA itself.
- On pure read workloads, CPU memcpy is affected by cache pollution, resulting in a 30% drop.
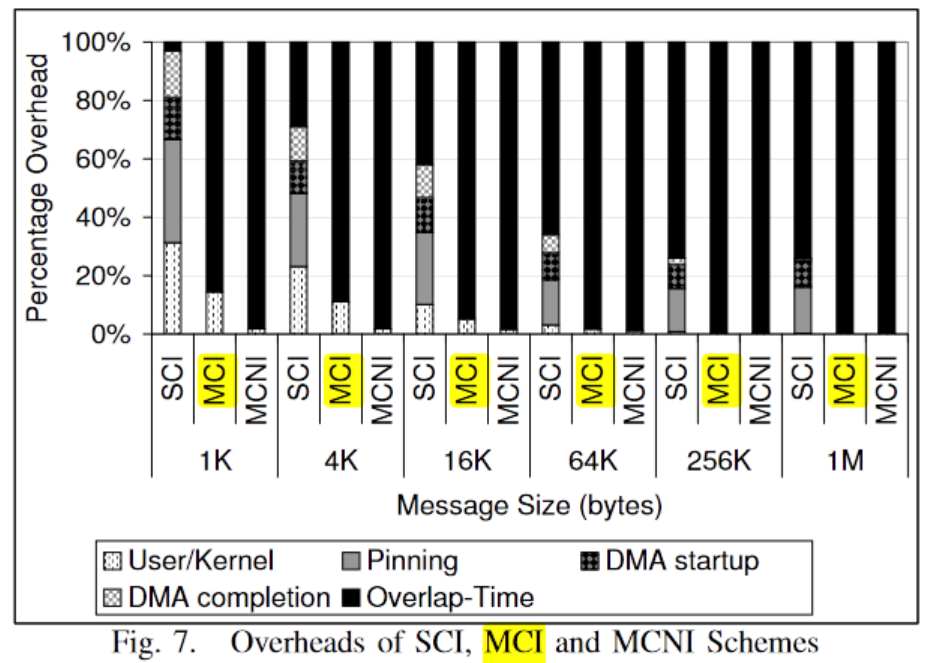
CLUSTER '07 Efficient Asynchronous Memory Copy Operations on Multi-Core Systems and I/OA
OSU's work in the same group, K. Vaidyanathan, L. Chai, W.Huang, D. K. Panda
The previous work seemed more focused on performance, while this work provides a hidden solution for multi-core system design. The overhead of initiating DMA can be assigned to a dedicated core, enabling better overlap of memory access and computation, up to 100%. Multi-cores can also facilitate copying to a dedicated core. [ More memory bandwidth or more cores? ] The "protect" strategy is used to achieve application transparency.
Intel SPDK + DMA
a simple callback interface from userspace
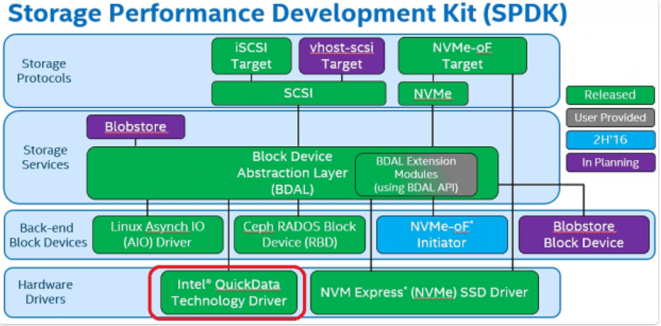
| Function | Description |
|---|---|
| spdk_ioat_probe() | Enumerate the I/OAT devices attached to the system and attach the userspace I/OAT driver to them if desired. |
| spdk_ioat_get_dma_capabilities() | Get the DMA engine capabilities. |
| spdk_ioat_submit_copy() | Build and submit a DMA engine memory copy request. |
| spdk_ioat_submit_fill() | Build and submit a DMA engine memory fill request. |
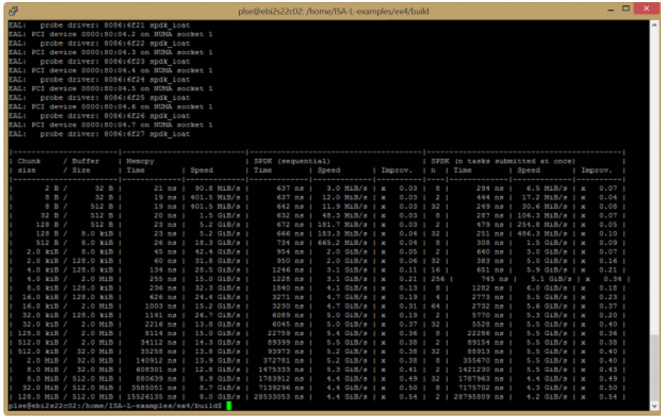
https://www.intel.com/content/www/us/en/developer/articles/technical/fast-memcpy-using-spdk-and-ioat-dma-engine.html
FAST '23 Revitalizing the Forgotten On-Chip DMA to Expedite Data Movement in NVM-based Storage Systems
USTC's research focuses on synchronous data movement between NVM and DRAM.
Large size asynchronous movements on NVM are often considered a mere trick (e.g., HeMem@SOSP'21). But if we divide requests internally, does it also weaken the concepts of sync and async? In essence, everything discussed earlier is also synchronous.
First, DMA on NVM was profiled, evaluating parallel copies for inter and intra requests, among other aspects. Some notable differences include:
- Intra: Multi-channel DMA for PM writes is not very effective, while reads are feasible (limited by write bandwidth).
- Inter: DMA greater than 4 easily gets saturated.
- NVM management in kernel space differs from DRAM as the space is contiguous, allowing for simpler management.
- …
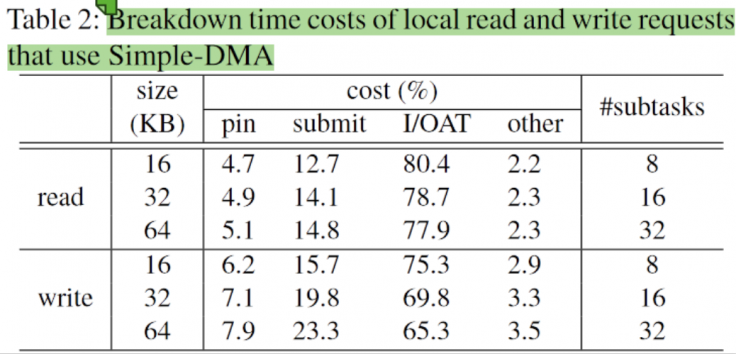
A breakdown of read and write, starting directly from 16KB
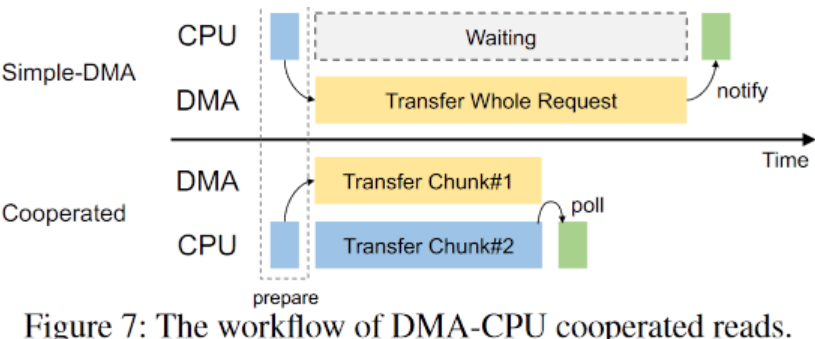
Then, they proposed a fastmove library:
- Batching (pin, submit, etc.), alignment, pre-allocation…
- DMA-CPU cooperation.
- Implementation involved modifying the DMA kernel module to better serve NVM-DRAM DMA copying, with additions to kernel file systems like Nova.
- Further, they developed a scheduler to manage DMA-CPU cooperation based on IO size, among other factors.
It's worth noting that this work is 15 years newer than the previous one, so it leverages many new features in the kernel to further enhance DMA performance.
I wanted to see the difference in microbenchmarking between CPU and modified DMA for small sizes (1K? 4K?), but they didn't provide it. Many experiments focused on end-to-end latency in the file system. Only support
fm_copy_to_user()andfm_copy_from_user(). The claim of the new hardware being compatible with general CXL seems a bit forced. It seems more dependent on the documentation than actual implementation.
arXiv '23 ASPLOS '24 A Quantitative Analysis and Guideline of Data Streaming Accelerator in Intel® 4th Gen Xeon® Scalable Processors
What is DSA?
DSA can offload operations including memcpy and even perform streaming CRC. A significant portion of the discussion is dedicated to the specification of DSA itself.
The key point is that DSA enables the calling end to operate with minimal latency:
- Specialized hardware is used for IOMMU, allowing DSA to directly access SVM, thus eliminating the need for pinning as discussed earlier and avoiding most of the startup overhead.
- Meanwhile, the address translations for the completion record, source, and destination buffers are performed by interacting with the on-device address translation cache (ATC) that interacts with the IOMMU on the SoC — a key difference from previous generations. This enables support of coherent shared memory between DSA and cores — they can access shared data in CPU virtual address space and thereby eliminate the need for applications to pin memory.
- New instructions like
MOVDIR64Bbypass the cache to submit a 64B descriptor. - On-chip features include QoS and similar mechanisms.
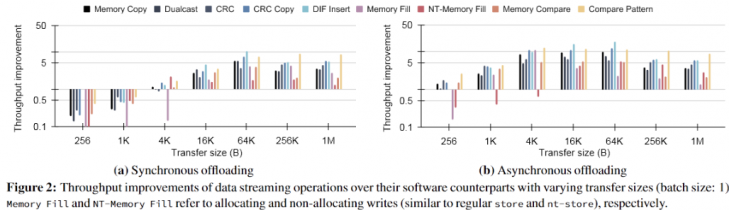
Many of the data presented are quite intriguing:
Most notably, DSA directly bypasses many of the issues previously discussed regarding DMA from the hardware level, resulting in faster performance even for small sizes, such as 256B.
Async batching

Breakdown after batching
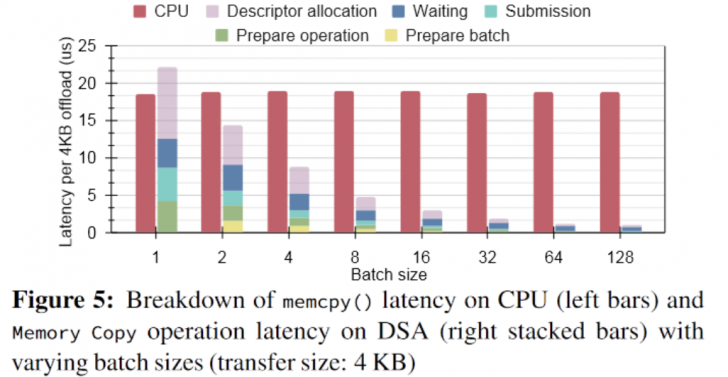
Saving CPU cycles
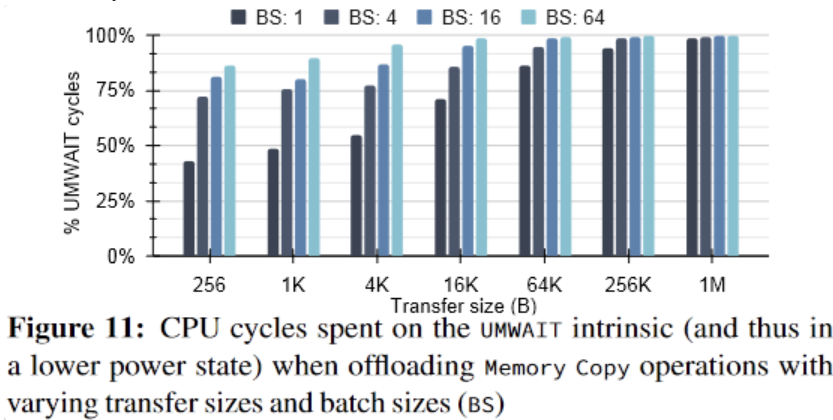
Finally, numerous guidelines are provided on maximizing throughput, interactions with the cache/memory hierarchy, and the configuration of DSA hardware resources.
DSA + memory-intensive systems? and nontrivial
DSA + EC?