In this article, we will list several papers on local NVM/PM fault tolerance.
note:
- the fault tolerance in some paper may indicate crash consistency, but here we mainly focus on device failures.
- fault tolerance across networks is not in the scope here. Related works mostly use replications, from Mojim (ASPLOS '15) to Rowan-KV (OSDI '23)
changelog:
- 2/17 add Kamino-Tx
- 2/24 add TENET
- 4/10 add Pavise
problems
Define data reliability problems on PM:
- media errors
- cell wear out
- bit flip
- …
- software scribbles
- bugs in firmware level
- exposed addresses
- crash inconsistency
- …
ECC is only useful for small-scale media errors.
existing works
System
seems like lots of works focus on transactional persistent memory, but lib details won't be mentioned below. check papers to know more
Replication Style
- libpmemobj-R
- replication across different PM devices (pm pools)
- more details
- Kamino-Tx (EuroSys '17)
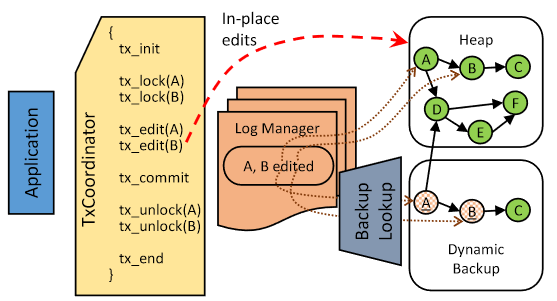
- Async backup to prevent additional data copy in the critical path of atomic ops.
- only for write-intensive hot data to save some PM space
- extend to chain replication (fault tolerance)
- backup for crash consistency + replication for fault tolerance: merge them, and only keep backup for the head of the chain
- to ensure the characteristic of chain replication, space cost is $(f+1+1+α)*datasize$ (note: backup and the head are in the same node)
- 1 for recovering non-head node
- α for backup
- Romulus (SPAA '18)
- async 2 reps for txn by only 4 fences (just like Kamino-Tx)
- TENET (FAST '23)
- TimeStone (ASPLOS '20)
- MVCC (logging) to scale performance. timestamp version control, non-blocking read and etc…
- version chain in DRAM (TLog), a compressed checkpoint version (group commit) in PM (CLog), Obj in PM (maybe stale).
- So that recovery can use small op log (params to replay txn) to replay txn
- [more details from GHC 6023]: "TimeStone is essentially redo-log + DRAM Buffer + group commit + operation logging."
- MVCC (logging) to scale performance. timestamp version control, non-blocking read and etc…
- TENET builds on TimeStone to create protections for spatial safety & temporal safety of memory access
- use local SSD replication:
- sync replications: Clog and op log
- async replications: data obj
- TimeStone (ASPLOS '20)
Coding Style
- NOVA-Fortis (SOSP '17) from NVSL
- "TickTock for NVMM data structures that combines atomic update with error detection and recovery" (just like Kamino-Tx rep style)
- CRC32 checksums to detect errors (including silent errors unlike TENET)
- replicated checksums of data
- RAID-4 style parity to hide parity bits from application's address space
- as NOVA is based on CoW, UPDATE is "allocates new pages, populates them with the written data, computes the checksums and parity, and finally commits the write with an atomic log appending operation"
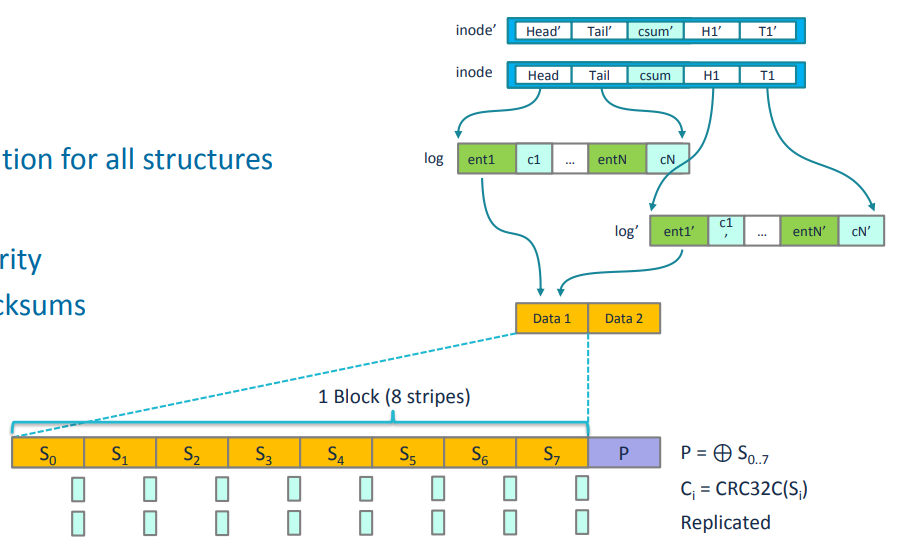
- eval on PMEP: 1) the cost of checking and maintaining checksums and parity for file data incurs a steep cost for both reads and writes. 2) …
- more details
- source codes
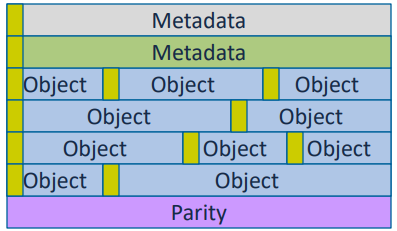
- Pangolin (ATC '19) from NVSL
- replicated metadata
- 1% XOR parities for 99% objects (with checksums)
- in-place delta update data with replicated redo logging in PM
- So Cocytus (FAST '16)…
why replicated redo? the only additional protection from replicated redo that I can think of is if data and parity are both crash-inconsistent and errors are found on a redo log entry.
- So Cocytus (FAST '16)…
- Adler32 for incremental checksums
- build a lib like libpmemobj on Opatne PM
- Concurrent updating of data is not supported, but concurrent updating of parity is supported (data in the same stripe but not in the same text)
- atomic XOR is a simple solution but cannot be vectorized, on the other hand, vectorized XOR needs range locks => hybrid approach on an 8KB threshold
but page size is 4KB?
- atomic XOR is a simple solution but cannot be vectorized, on the other hand, vectorized XOR needs range locks => hybrid approach on an 8KB threshold
- more details
- Vilamb (arXiv '20) from Rajat Kateja, Andy Pavlo. (also named ANON I guess)
- Palingon sync-update parities -> expensive -> how to loosen guarantee?
- two background threads for async: one for check parities, and one for update. pros:
- checksums are in page granularity -> read amplification. async process can merge several ops to save BW.
- utilize wasted "dirty" bits in the page table
finding the gap from old redundant design is cool, it reminds me of DaxVM@MICRO'22
- rich experiments but on emulated NVM
- some metadata is still volatile -> needs batteries
- more details
- Pavise@PACT'22
- Pangolin's following work
- one redo log
- a lib with less intrusive changes to the application
- PMDK access tracking
- source codes
- …
Architecture
Arch papers on PM fault tolerance are usually about hacking ECC modules…
- TVARAK (ISCA '20) from Rajat Kateja
- calculating parities like Pangolin is too slow (may lead to 50% drops)
- add a new HW controller beside LLC to offload computation (maintain parities)
- simulation on zsim
- Polymorphic Compressed Replication (SYSTOR '20)
- for columnar storage models on hybrid memory
- use compression to reduce writes to NVM as replications
- ECP (ISCA '10)
- Error-Correcting Pointers (ECP) to remap locations instead of ECC, for the ECC blocks wearing out problem
- and so many works on this approach, like zombie memory, chipkill, etc. more
- WoLFRaM (ICCD '20)
- wear-leveling + fault tolerance with programming address decoder (PRAD)
design space
- LB + fault tolerance
- fault domains level
- 6~8 DIMMS but with 1% parity?
the difference of error granularity
- 6~8 DIMMS but with 1% parity?
- real error patterns of persistent memory
- not very erasure-coding style?
- not very optane style?
- only txn make sense?
- workloads related
- …