QoS (LB) on persistent memory systems to avoid interference.
Problem
QoS is to control the priority among different applications, like latency-critical tasks against throughput tasks. Normally the source of those tasks fights for is bandwidth, which is a simple metric and easy to monitor. So best effort tasks won't affect latency-critical tasks. Some QoS works focused on DRAM[7].
Similarly, a hybrid access pattern on persistent memory incurs a dramatic performance drop. But it's tricky. Some other variables will also affect the overall performance.
interference
[1] found some simple cache eviction strategies (like FIFO) without too much data migration can beat complex ones.
[2] found:
- The interference between a process accessing DRAM and one performing random reads to PM is small.
- When a process accessing DRAM is concurrently executed with one performing frequent writes to PM, the performance of the former is significantly degraded but that of the latter is not.
multi-fold interference source:
- iMC WPQ size is designed for fast DRAM access, so too many slow writes to PM will easily fill it up and block DRAM writes
- DDR bus
- PM write amplification
- …
A couple of recent works focus on this QoS problem, including NVMSA '20, APSys '21, FAST '22 (2) [3-6]. QoS is all about monitoring and control, so let's discuss them separately.
Monitor
QoS systems should firstly know when an interference shows up and who it is.
FairHym[3] set up a couple of thresholds:
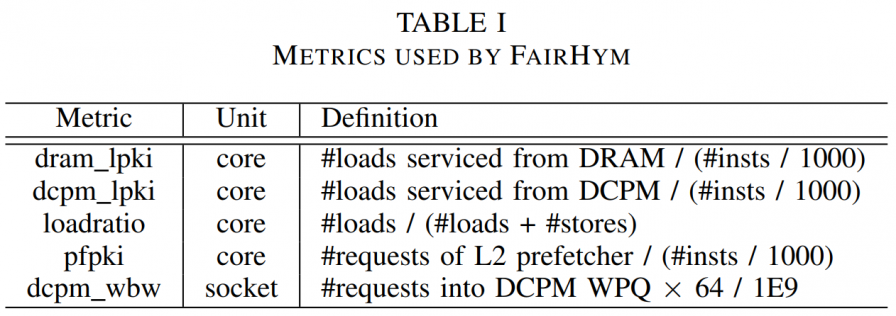
And the exact values of them come from experiments, so it's coupled with workloads and HW settings.
Dicio[4] only consider one best-effort task and one latency-critical task situation.
Similarly, Dicio has some rules from "priori knowledge".
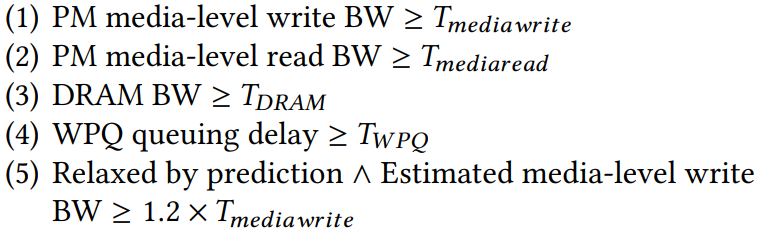
$T_{DRAM}$ here is dynamic (5-30 GB/s) and depends on the access pattern on PM.
estimated media-level write BW (μs level) = request-level BW * recent WA ratio(ms level)
note: different cases need different strengths on control?
MT^2[5] is in kernel space, using Intel Memory Bandwidth Monitoring (MBM) and some toolkits to collect data (Dicio[4] claims that MBM has some severe bugs for now). So they can get the bandwidth of DRAM and PM (a lot of effort here to implement, check paper details).
Get read latency from $RPQ_O/RPQ_I$, write latency from periodical writes. And latency is used to detect interference. The latency threshold is different depending on the access type (random/seq + read/write).
note: the correlation between latency and bandwidth is basically linear. So the detection here is equal to BW?
in NyxCache, "if the maximum IOPS of pattern A is MaxIOPSA, then the cost of each operation of pattern A is 1/MaxIOPSA."
note: the implicit assumption here is that the cost is linear and ignoring cache effects. emmmmmmmm
In contrast to the above, NyxCache[6] find the victim application that can bring the biggest performance gain with the same suppression.
Like the fig below, we want to choose one app to throttle between B and C to ensure A's perf.
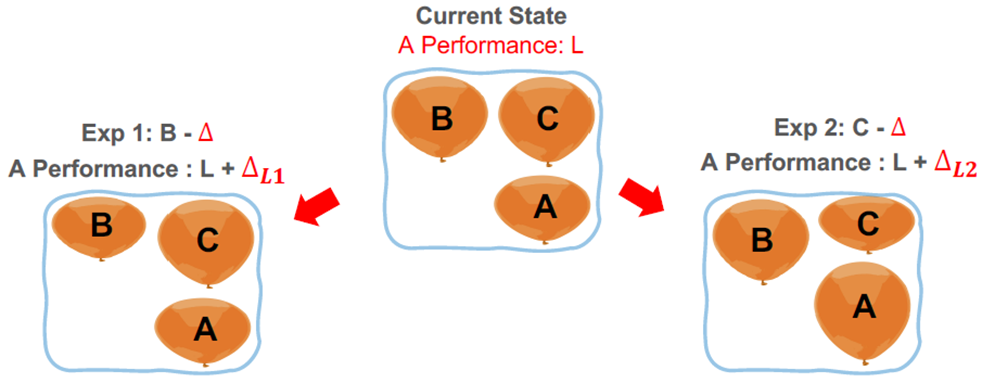
note: you will get it after you find the author is Kan Wu, who is the author of The Storage Hierarchy is Not a Hierarchy.
Control
After finding out which process should be throttled, QoS systems need to control it efficiently.
FairHym[3] assumes in VMs applications, every core is in exclusive use, so throttling the frequency of the target cores can reduce the BW on PM.
note: weak assumption and waste computing source
Dicio[4] tests some methods including MBA (Intel Memory Bandwidth Allocation, basically it's delay injection in memory requests) and limit frequency:
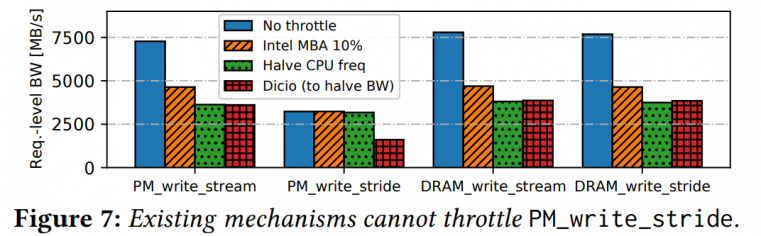
*_stride means write 64B but at each 256B aligned addr to amplify writes. they claim that the old method can't handle PM_write_stride.
note: maybe just not inject enough delays? like 1%.
Dicio controls the number of cores to manage best-effort tasks' BW. And down to zero for BW tasks a single core (duty cycle).
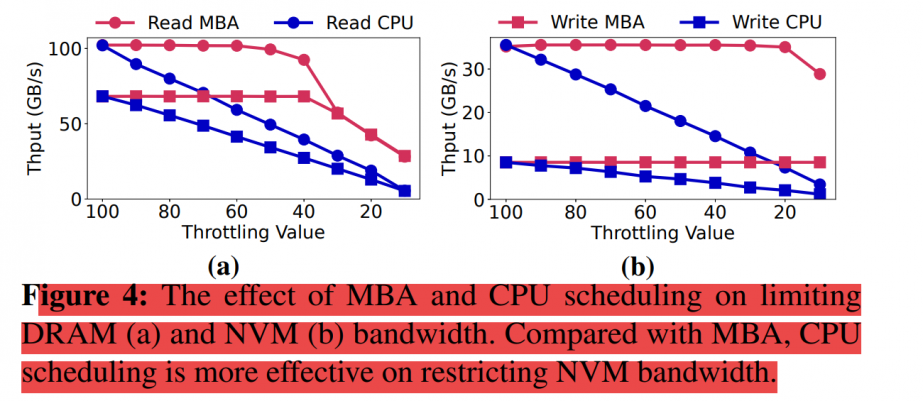
MT^2[5] tries to combine MBA and CPU resources limitations. MBA only controls the ratio of delay injection, so the same throttling value may differ on different memory access pattersn. While throttling CPU resources can almost linearly reduce BW. What's worse, MBA doesn't work on PM.
Instead of changing frequency or the number of cores, MT^2 changes the CPU quota of a thread by LINUX cgroup control, which is finer-grained.
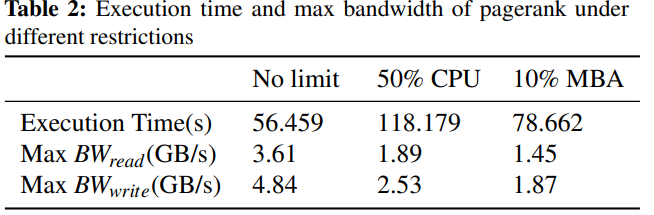
Table 2: pagerank under 10% MBA is faster than 50% CPU with lower BW.
The reason is simple: 50% CPU slows every instruction instead of only memory access.
note: but sorting, coding is computing-intensive…
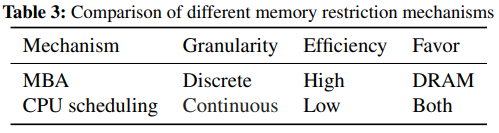
so they use MBA to throttle DRAM access and CPU scheduling for NVM.
same question here, maybe just because MBA is designed for fast DRAM access, and the ratio of injected delays are not big enough (throttling value < 10 in fig.4)
NyxCache[6]
quote "To mimic the behavior of Intel MBA, Nyx implements simple throttling by delaying PM accesses at user-level."
"Our current implementation adds delays in units of 10ns with a simple computation-based busy loop. In some cases PM operations may need to be delayed indefinitely (e.g., when a resource limit is reached); in this case, PM operations are stalled until the Nyx controller sets the delay to a finite value"
Application access PM through NyxCache interface, so NyxCache can utilize a user-level MBA with a fixed ratio. And it worked, so delay injection is not the problem.
experiments
…
random thoughts
- QoS from applications instead of system-level to bypass some limits brought from the bottom-view.
- Will injected delay waste CPU resource? context switching cost and CPU resource maybe trade-off here..
- Many networking QoS papers utilize or even create more "sensors" than all above. Can we mimic them without HW support?
- …
ref
- Kassa, Hiwot Tadese, et al. "Improving Performance of Flash Based {Key-Value} Stores Using Storage Class Memory as a Volatile Memory Extension." 2021 USENIX Annual Technical Conference (USENIX ATC 21). 2021.
- Imamura, Satoshi, and Eiji Yoshida. "The analysis of inter-process interference on a hybrid memory system." Proceedings of the International Conference on High Performance Computing in Asia-Pacific Region Workshops. 2020.
- Imamura, Satoshi, and Eiji Yoshida. "FairHym: Improving Inter-Process Fairness on Hybrid Memory Systems." 2020 9th Non-Volatile Memory Systems and Applications Symposium (NVMSA). IEEE, 2020.
- Oh, Jinyoung, and Youngjin Kwon. "Persistent memory aware performance isolation with dicio." Proceedings of the 12th ACM SIGOPS Asia-Pacific Workshop on Systems. 2021.
- Yi, Jifei, et al. "MT2: Memory Bandwidth Regulation on Hybrid NVM/DRAM Platforms." 20th USENIX Conference on File and Storage Technologies (FAST 22), Santa Clara, CA. 2022.
- Wu, Kan, et al. "NyxCache: Flexible and Efficient Multi-tenant Persistent Memory Caching." 20th USENIX Conference on File and Storage Technologies (FAST 22), Santa Clara, CA. 2022.
- Fried, Joshua, et al. "Caladan: Mitigating interference at microsecond timescales." 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). 2020.