learned index + PM. APEX: A High-Performance Learned Index on Persistent Memory[1]
Baotong Lu is the author of Dash[2], and Jialin Ding is the author of ALEX[3]. Both works have a big impact. So here is APEX combining PM indexing and learned index (ALEX).
in case you don't know what is ALEX, check here
This pre-print work is open-sourced, APEX on Github.
challenges
some challenges of linear combination:
- Extra writes from some designs of ALEX
- insert data
- need to update neighbor with gaps
- shifting data to keep ordered
- updating metadata
- SMO ( Structural Modification Operations, like node spliting) is expensive
- insert data
- logging for persistence on PM is expensive
intutive thoughts:
pros: latency on PM is higher, so more time for models
cons: the cost of maintaining a sorted (or nearly sorted) array in PM
archi
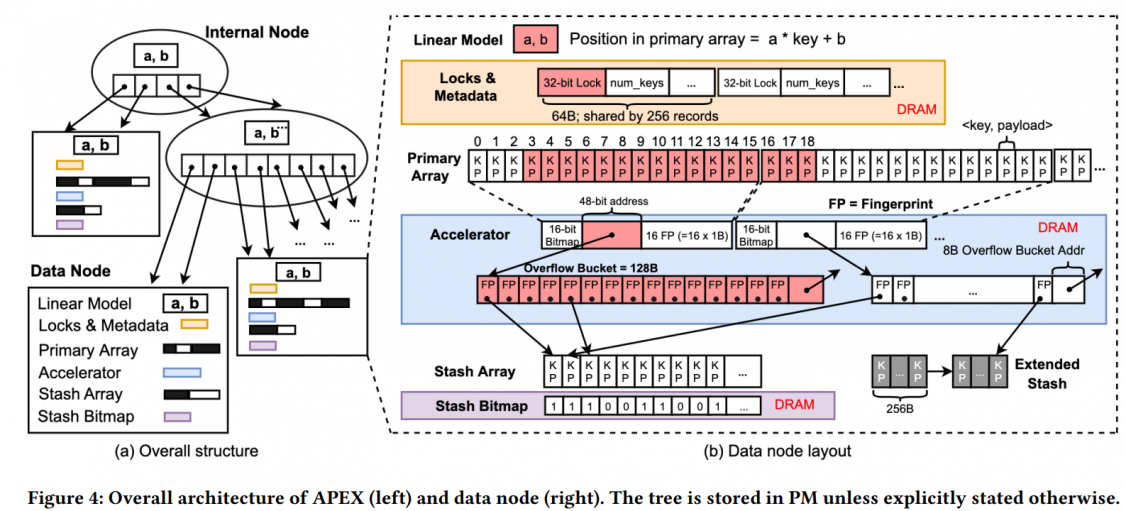
Keep metadata, locks, bitmaps and fingerprints (accelerators in paper) in DRAM, because they can be rebuilt. (bitmap: invalid a key by setting it out of legal range, so data in PM contains enough information)
like ALEX, APEX will insert a key to predicted position, and limit the probing distance to 16 (512B in total). And use a linked-list Stash Array to handle contentions (blue part in fig 4).
every 16 slots (key and payload) will be mapping to one accelerator.
Op
lookup
probe-and-stash: predict a position by layered-RMI models and search the corresponding space. If not found, check the stash array.
Range query: i~j => search f(i)~f(j+15) and related Stash Array.
the cost of search unsorted array?
insert
just similar with lookup. note that keys out of ranges are flags that indicate their slots are empty.
update: in-place update
write payload firstly, and write key secondly. data written in the same cacheline won't be re-ordered.[4]
?!
delete
key invalidation, and set bitmaps in DRAM
SMO
Like ALEX, use cost model (the average number of cache misses during probe-and-stash) to choose node expandsion and node split.
hybrid logging in node expansion
multi-step expandsion process:
- allocate a expanded node
- retrain or rescale models, insert from A to B
- attach B, detach A
They found that step 2 is relatively long running. So instead of use redo-logging for the whole process, they use undo-logging before step3 and redo-logging after step 2.
Bulk loading
concurrency control - Lock Granularity
optimistic locking: node-level locks +
allocate one lock per 256 records, as shown in Figure 4(b). Each lock in data nodes is a 32-bit integer where one bit is used to represent the lock’s current status (locked or unlocked); the remaining 31 bits represent a version number
recovery
lazy-recovery:
we adopt a lazy recovery approach [17, 33] in which we recover a data node only when an index operation accesses it
experiments
check paper… APEX loses only when workload is too complicated to fit (like FB of SOSD). The perf gap in range scan is smaller.
refer
- Lu, Baotong, et al. "APEX: A High-Performance Learned Index on Persistent Memory." arXiv preprint arXiv:2105.00683 (2021).
- Lu, Baotong, et al. "Dash: Scalable hashing on persistent memory." arXiv preprint arXiv:2003.07302 (2020).
- Ding, Jialin, et al. "ALEX: an updatable adaptive learned index." Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2020.
- Andy Rudoff, PIRL 2019: Protecting SW From Itself: Powerfail Atomicity for Block Writes, https://www.youtube.com/watch?v=kJ1qewIgGeQ&t=1283s