An experiment-driven work from SJTU-IPADS shows some methods to achieve better performance in NVM+RDMA systems.
note: text in markdown quote style is some trivial thoughts.

all three execution flows above are possible, but persistency is ensured only in the second one.
note: case 1 is also persistent on eADR mode. And with DDIO enabled, NICs can access LLC?![2]
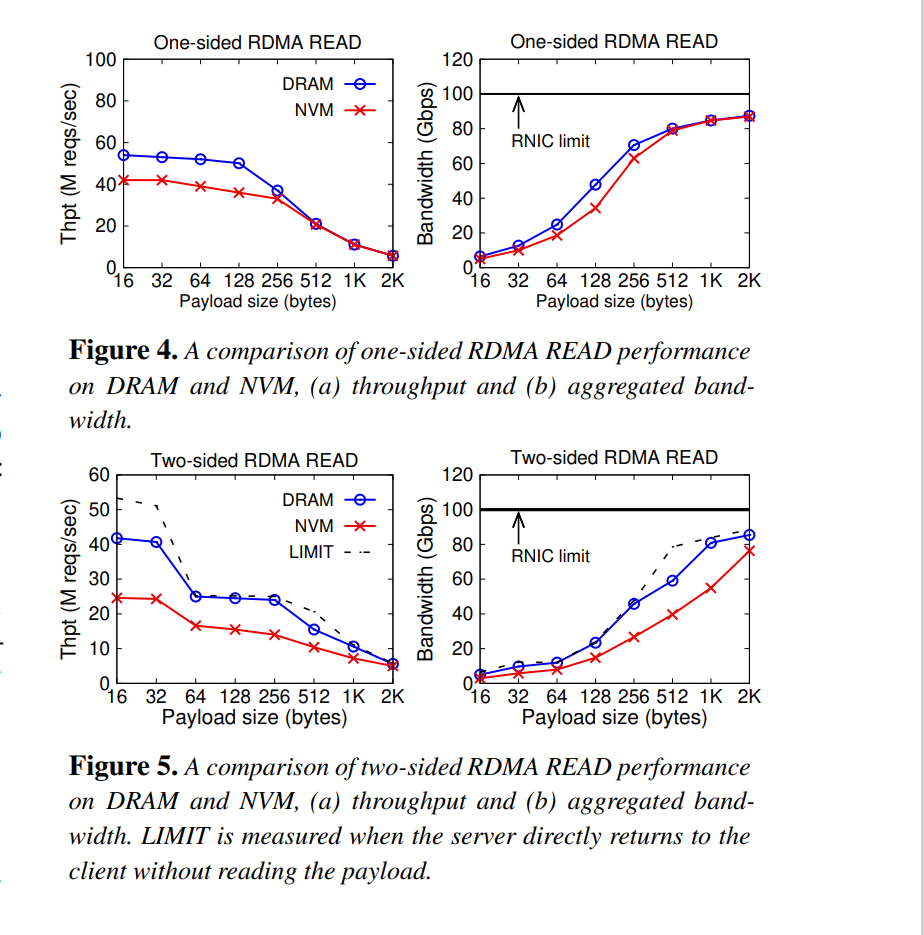
remote read operations are close to performance upper bound, so this paper mainly focused on remote write.
for large read payloads, NVM is very close to DRAM. so in this scene, the network is the bottleneck.
For small 2-sided reads(16B), high latency of NVM causes degradation. in contrast, for 1-sided reads PCIe latency dominants.
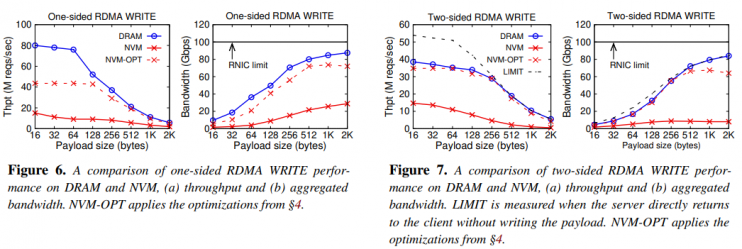
write performance drops a lot. In the worst case, the system only achieves only 12% of the NVM peak write bandwidth.
A summary of design advice:
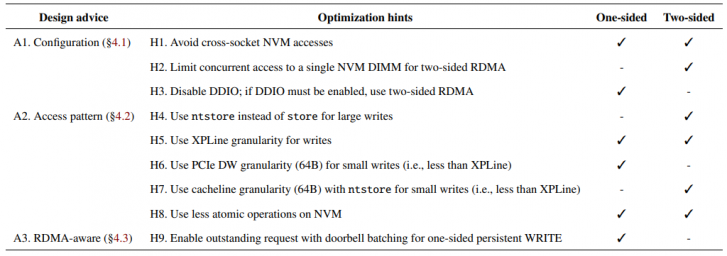
note: H1,H2,H4,H5 is mentioned before on [3]. But because local-NVM and RDMA+NVM are different, and one-sided & two-sided ops are two scenarios.
Let me list some interesting (or counter-intuitive) results:
- one-side writes scales well on a single NVM DIMM. 2-sided writes and local writes can't scale well because of the latency brought from NVM accessing directly from CPU. The contention in memory controller is a disaster.
question: what's about the contention in XPBuffer? they didn't mention this. And [4] claims that "AIT Buffer and the LSQ exacerbates this scaling issue", which is also in one-side read's critical paths!!
- DDIO's impact
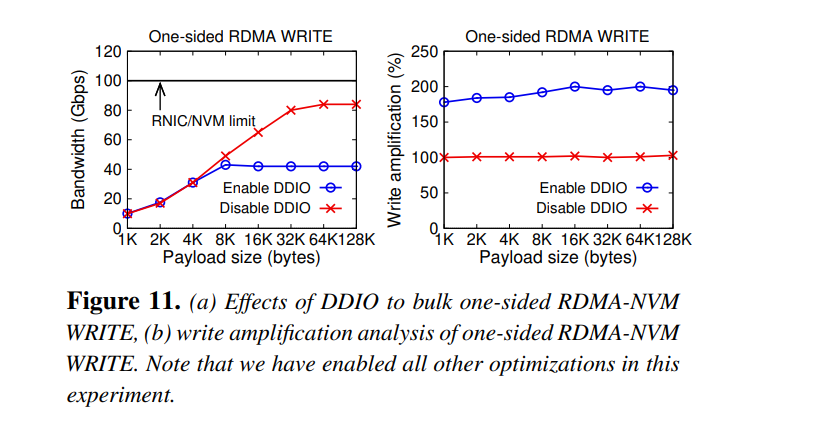
The reason why throughput drops is that sequential writes to LLC will become random writes to NVM, and random writes cause write-amplification. But DDIO can double perf of 2-side ops. - For small writes, 64B is the best access granularity for RDMA+NVM. For local-NVM access, 256B (XPLine size) can fully utilize Optane. But 256B will incur huge network amplification. Some extra reads generated by CPU or RNIC to NVM will lead to further contention if the granularity is 256B.
padding to 64B may waste storage space..
- use less atomic operations on NVM. Read-modify-write access pattern of atomic operations is not friendly for NVM. Worse, the granularity of atomic ops is not 64B. As a result, they suggest "moving the data for atomic operations (e.g., spinlock) from NVM to DRAM whenever possible."
- Enable outstanding request with doorbell batching to prevent the additional read request to ensure persistency. So we no longer need to wait for the first WRITE to complete. (latency: 4μs -> 3μs)
refer
- Wei, Xingda, et al. "Characterizing and Optimizing Remote Persistent Memory with {RDMA} and {NVM}." 2021 {USENIX} Annual Technical Conference ({USENIX}{ATC} 21). 2021.
- Kurth, Michael, et al. "NetCAT: Practical cache attacks from the network." 2020 IEEE Symposium on Security and Privacy (SP). IEEE, 2020.
- Yang, Jian, et al. "An empirical guide to the behavior and use of scalable persistent memory." 18th {USENIX} Conference on File and Storage Technologies ({FAST} 20). 2020.
- Wang, Zixuan, et al. "Characterizing and modeling non-volatile memory systems." 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2020.