Some eADR related works

Optane Persistent Memory is an NVM product. Normally, we treat PCM media as a fast-read and slow-write type. But on Optane, things changed.
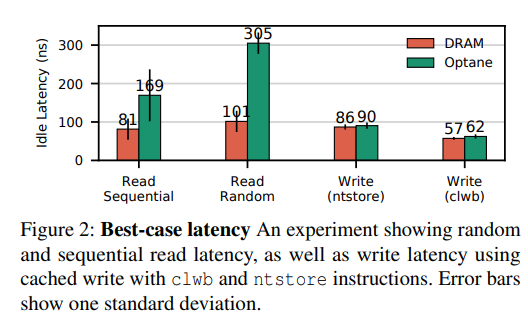
The reason is Optane is not a device with exposed media. Instead, lots of buffer layers are set between cachelines and PCM media. Consequently, write ops don't have to touch PCM media like read ops.
In the domain of Asynchronous DRAM Refresh (ADR), all data is persistent. Some extra power supply can ensure data outside media will be finally flushed to media.
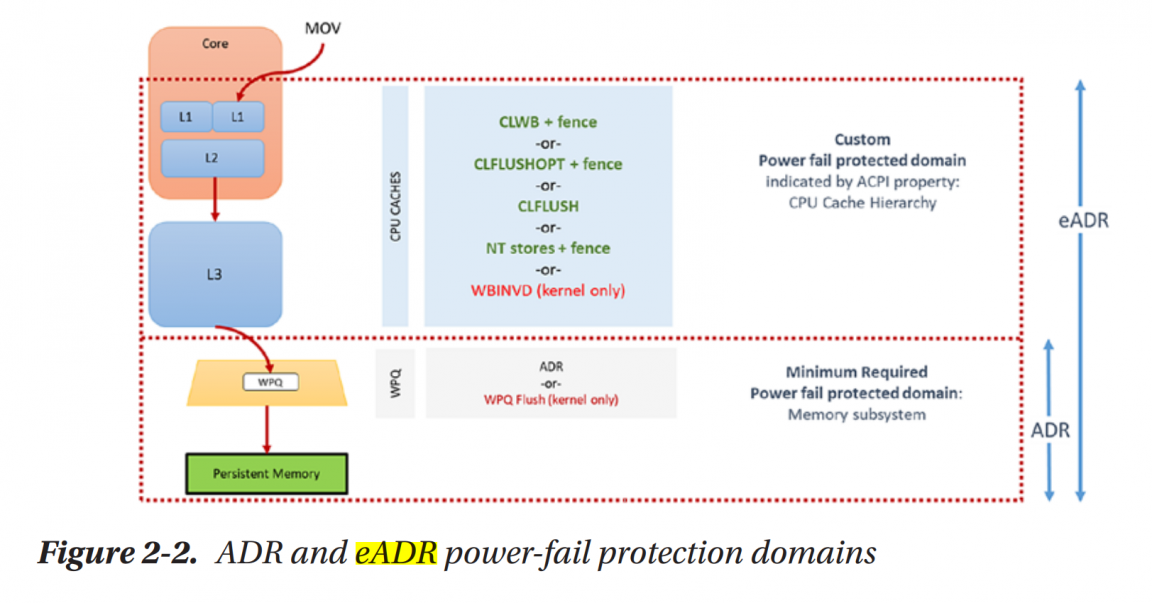
Extended asynchronous DRAM Refresh (eADR) is a new feature supported by Intel Optane PM 200 Series and 3rd Scalable Xeon processors. The main difference between eADR and ADR is the non-volatile regions expand to cache with battery-backed (note: [2] said the eADR domain excludes L1 cache, I can't find any support materials, and I found contradictions in their slides).
Normally when we try to program on old Optane PM, we need to focus on crash consistency problems from volatile caches in CPUs and orders of instructions after re-ordering operations of Optane controllers. As a result, we have to use clwb and mfence to protect crash consistency and correct orders. But on PMs supporting eADR, we don't have to flush cachelines manually.
(SIGMOD Record '21) some researchers claim that [1]
skip cacheline flushes on existing Cascade Lake CPUs showed eADR’s potential impact is very small for hash tables … the reason to hash table’s inherently random access patterns
What I bought from this work is that WPQ and other short queues are still the bottlenecks.
note: but if we don't have to wait for the data flushed to the Optane media, the latency that applications feel will be apparently smaller.
(HPCA '21) [3] uses an extra Battery-Backed Buffer next to the L1 data cache to provide persistency without powering the whole CPU cache hierarchy. And under this circumstance, there is no need for barriers and flushes in codes.
note: "stores may also write to the cache out of program order" so eADR still needs
fence()to ensure order.
(VLDB '21) [4] use some design cases of lock-free data structures for eADR and ADR systems to indicate the diff of them.
- Better persistency of eADR can avoid perf cost of transactions (especially on write-heavy workloads).
- Can't directly use ADR-systems on eADR. Sequential data in persistent-LLC will be randomly flushed to PM media.
- So use persitent storage instructions for non-critical data in eADR mode.
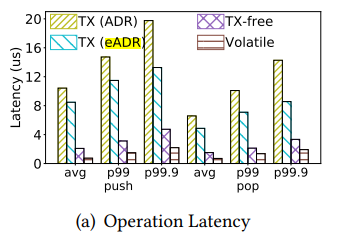
To attain optimal performance, algorithms should be specifically designed for the eADR mode by taking advantage of the immediate persistence of any visible operation. Our results show that this is more applicable for update-heavy workloads
refer
- Lu, Baotong, et al. "Scaling Dynamic Hash Tables on Real Persistent Memory." ACM SIGMOD Record 50.1 (2021): 87-94.
- Zardoshti, Pantea, et al. "Understanding and Improving Persistent Transactions on Optane™ DC Memory." 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2020.
- Alshboul, Mohammad, et al. "BBB: Simplifying Persistent Programming using Battery-Backed Buffers." 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2021.
- Gugnani, Shashank, Arjun Kashyap, and Xiaoyi Lu. "Understanding the idiosyncrasies of real persistent memory." In Proceedings of the VLDB Endowment, the 47th International Conference on Very Large Data Bases (VLDB) 2021