How to predict future hotness of a new request in photo cache systems?
Some works about filesystem and cacheline use rich features to predict hotness of objects in the near future. This work did quite similar but on a social photo dataset of Tencent.
This predictor will be an additional module with cache replacement methods.
feature selection
This dataset contains lots of feature-dims. And their feature extraction is a straightforward sampling.
Initially, all n features form a full set,{a1,a2,…,an}, and we use the information gain (the greater the information gain, the more helpful to classification) to quantify the quality of each feature, and then we choose the optimal feature, ai, which has the biggest information gain, to construct the goal set, {ai}, and remove {ai} from the original full set. Again, the information gain of each feature in a full set is judged and the optimal feature, aj, is determined and transferred from the full set to the goal set—that is,{ai,aj}. If the goal set{ai,aj} is superior to the previous{ai}, which means that the effect of the new classification is better, then the process will be repeated accordingly. Otherwise, the process stops.
can be improved a lot, even by autofeat? How to connect feature selection with systems? by using RL?
results:

access counters matter!
model selection
iterate some models..
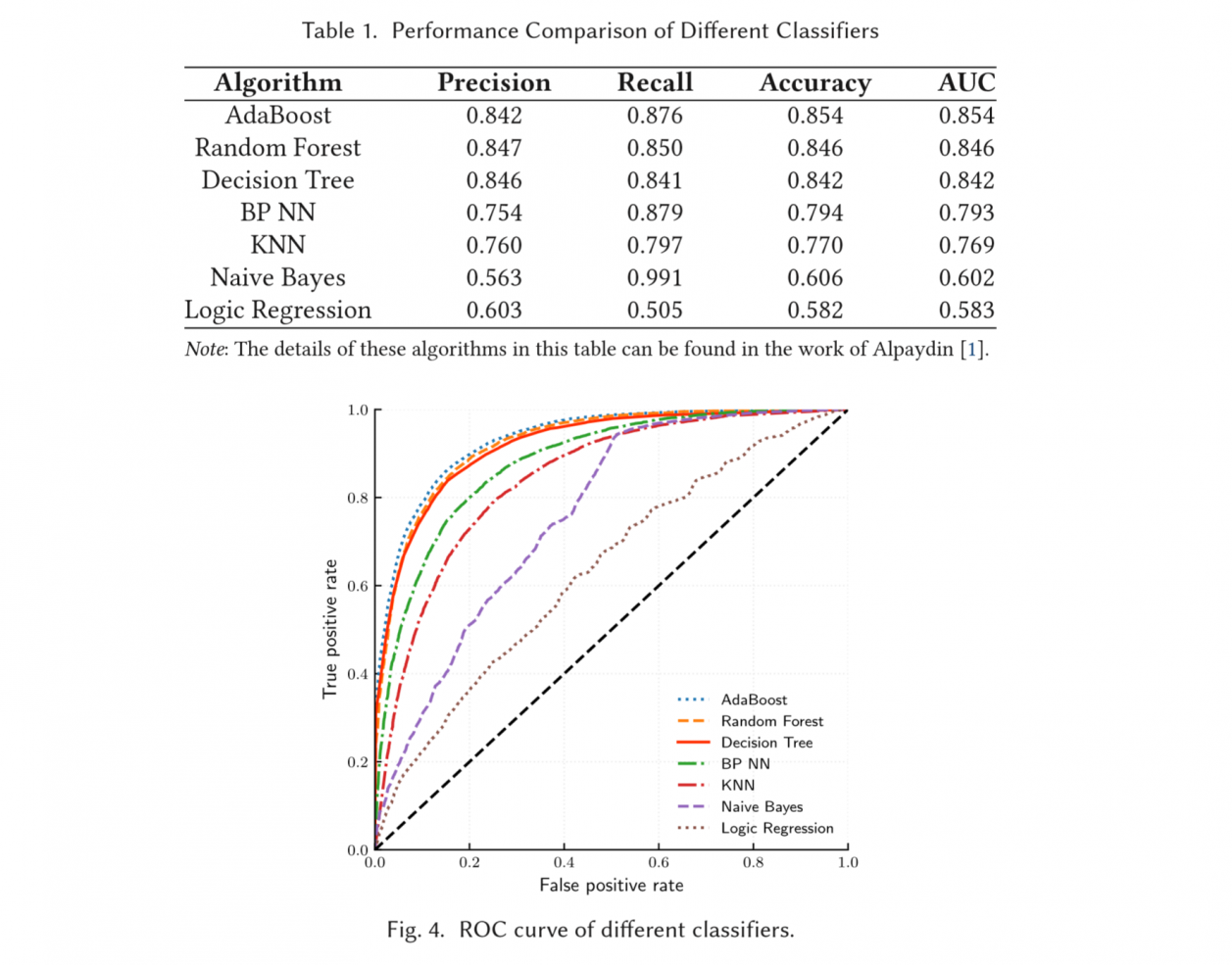
they choose decision tree as a trade-off option.
Some problems here: 1. they claim that they used CART as basic tree models, but CART is not split by information entropy. It seems like they know nothing behind ID3, C4.5 and CART… 2. RF can predict parallelly, so the prediction cost won't increase linearly.
prediction may be wrong in some cases. To prevent further demage to the cache system, they use a history table to store "reuse distance". This table is only for check existence, so it's quiet small, < 1 MB.
Also on training, they illustrate the effect of cost matrix in decistion tree. This matrix is closely related to the archi of systems. If the cache space is small, then we will redirect more requests to slower devices, so we should award high recall and the model can output more 1.
In other words, if this system is not build upon this smart cache, all new requests will be cheated as non-one-time-access objects, so we can say the prediction outputs of the default "model" (although there is not a model in default) is all 0.
the size of cache space is relevent to the workdloads. Like if the space usage is high, and even close to 99%, we can say the cache space is small. So it fully depends on workloads and should be dynamic, but they did it in a stable workload and chose some magic numbers instead…
To cover the problem of performance drops over time, they just daily update models.
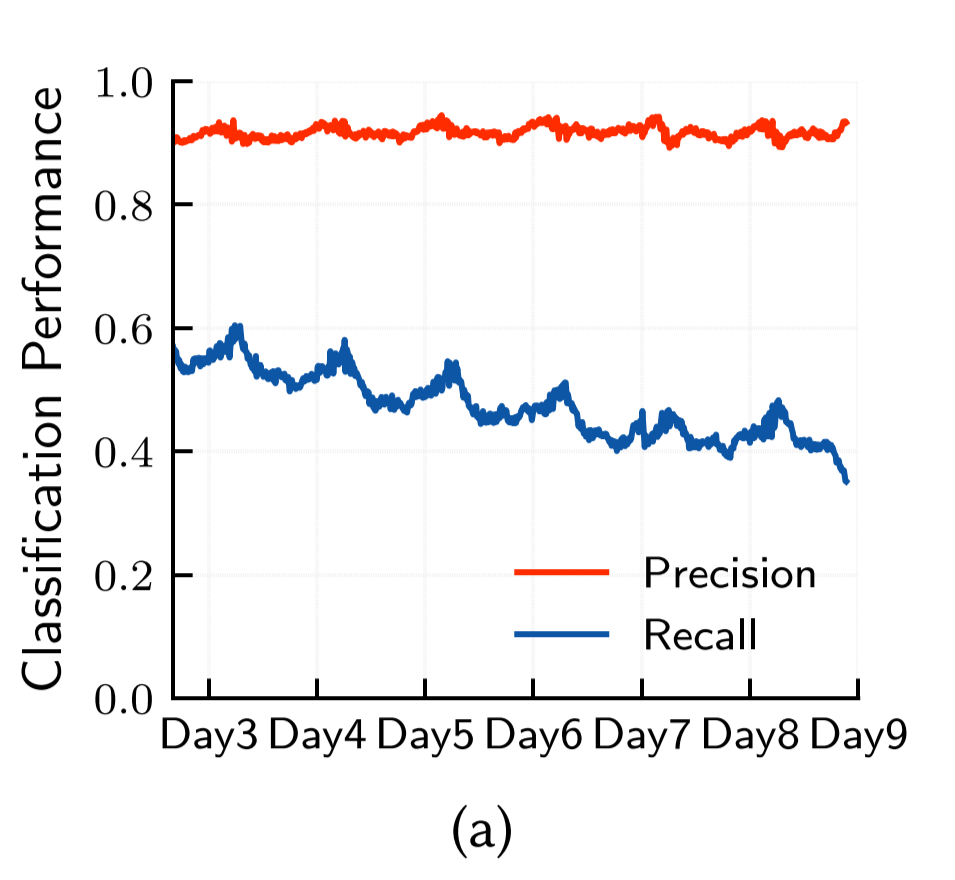
experiments
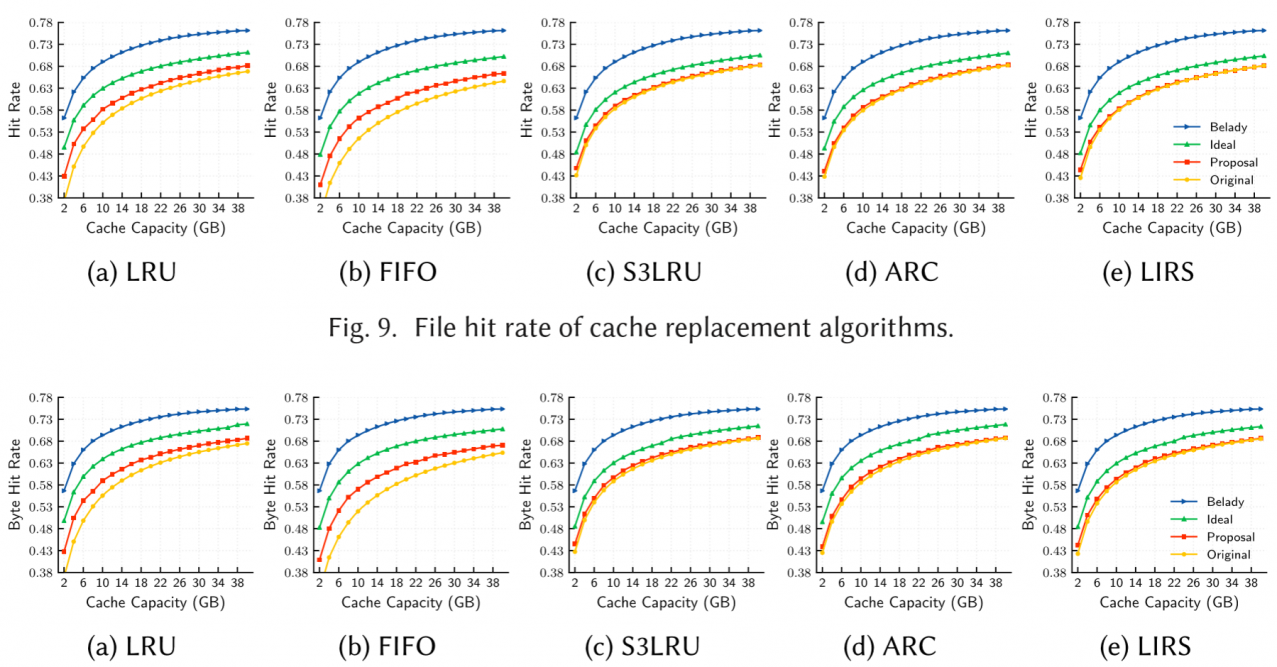
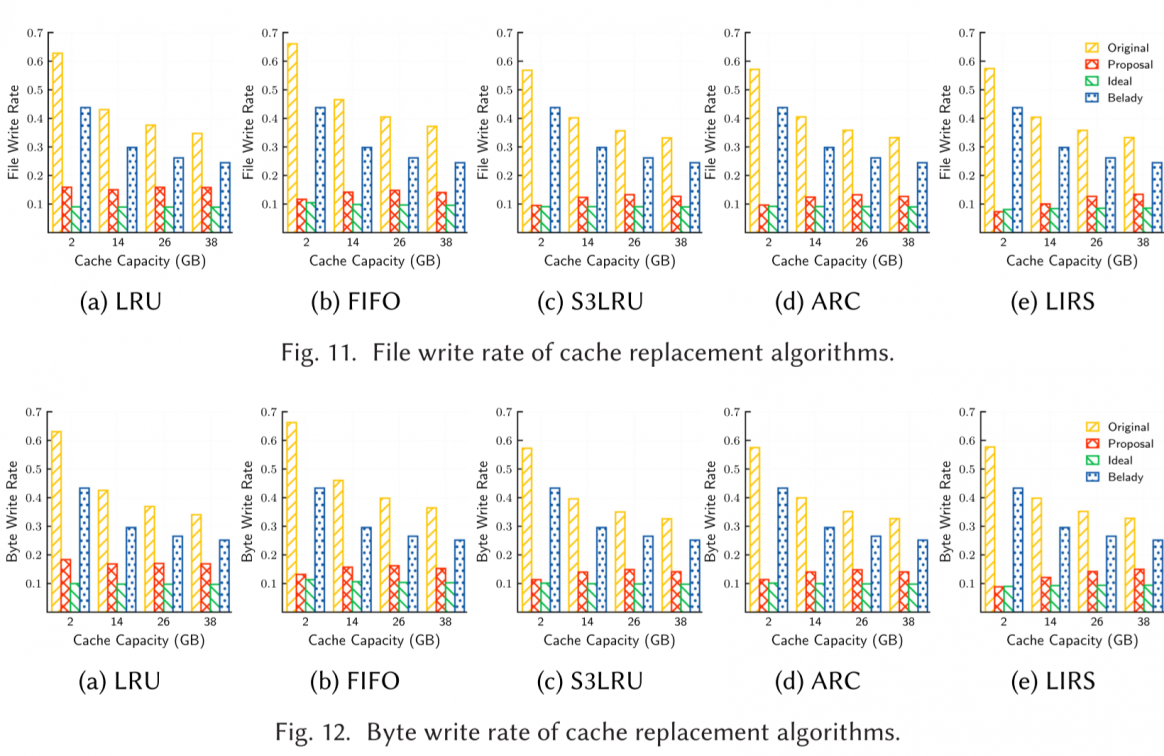
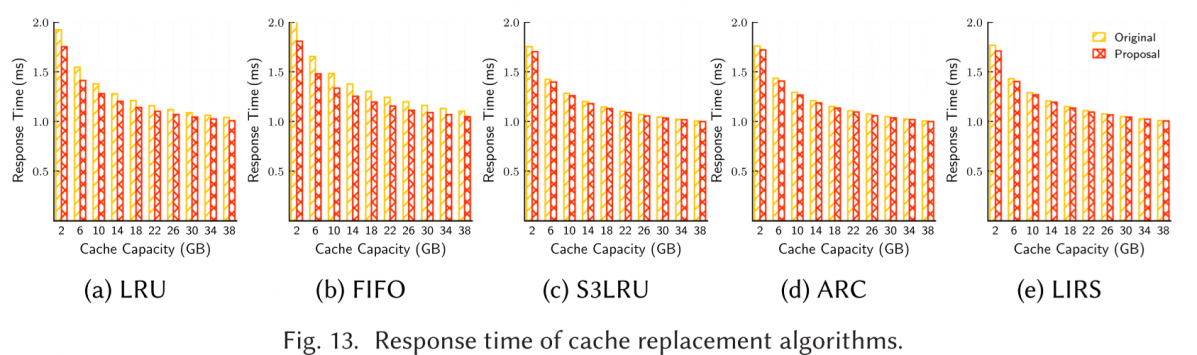
the improvement of response latency is not obvious, and will decrease more if cache is bigger.
go to check the transaction version paper
related works
- flashield uses SVM as a binary classifier to predict the future writes of some objects. (the threshold is also hand-written)
- ML-WP uses naive bayes to predict future writes of cloud block systems. (A+B?)
- Orthus-KV dynamically redirects some requests to slower devices randomly.
refer
- Wang, Hua, et al. "Cache What You Need to Cache: Reducing Write Traffic in Cloud Cache via “One-Time-Access-Exclusion” Policy." ACM Transactions on Storage (TOS) 16.3 (2020): 1-24.
- Eisenman, Assaf, et al. "Flashield: a hybrid key-value cache that controls flash write amplification." 16th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 19). 2019.
- Zhang, Yu, et al. "A machine learning based write policy for SSD cache in cloud block storage." 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 2020.