Paper notes about Assise, a distributed FS on NVM. Assise keeps data & metadata in clients (opposite to disaggregation) to enble fast recovery and high perf.
Backgroud
Challenges in disaggregation systems:
- Network & kernel latency is dominated. network ~8000ns, kenel syscall ~1000ns, while write data only ~100ns.
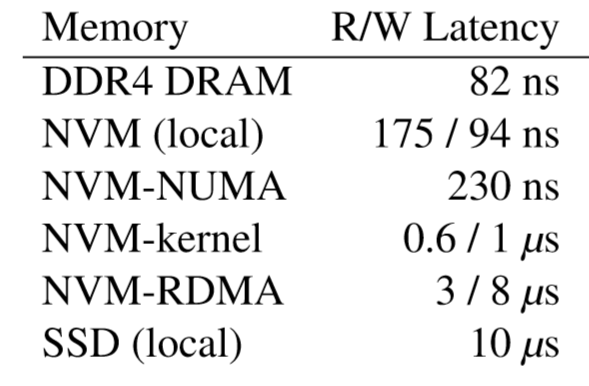
- small io amplification: granularity difference between buffer cache and block would amplify access size, which exacerbates network & storage latencies
- client failure cause client's cache rebuilding, which is time consuming
Assise
key idea: maximize efficiency of client-local NVM
- low latency: process-local & client-local access
- linearizability and data crash consistency: *CC-NVM *distributed client-side NVM coherence protocol**
- high availability
- fail-over to cache-hot client replicas
- for fast recovery, Assise reovers client NVM caches locally -> network utilization↓
Components:

architecture:
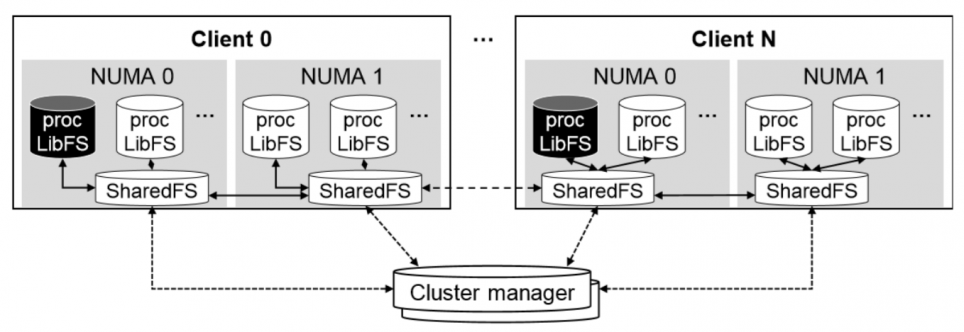
- SharedFS: store data & metadata in client-local NVM
- LibFS: excutes POSIX op in user space -> kernel crossing overheads↓
log writes at operation granularity
LibFS is process-private, and SharedFS is node-level. Process-private space is not ensured valid or integrity, which is SharedFS's jobs.
because remote NVM is faster than local SSD, set a warm replica as the 3rd storage level (local DRAM, local NVM, …) for reducing read latency.
I/O Path
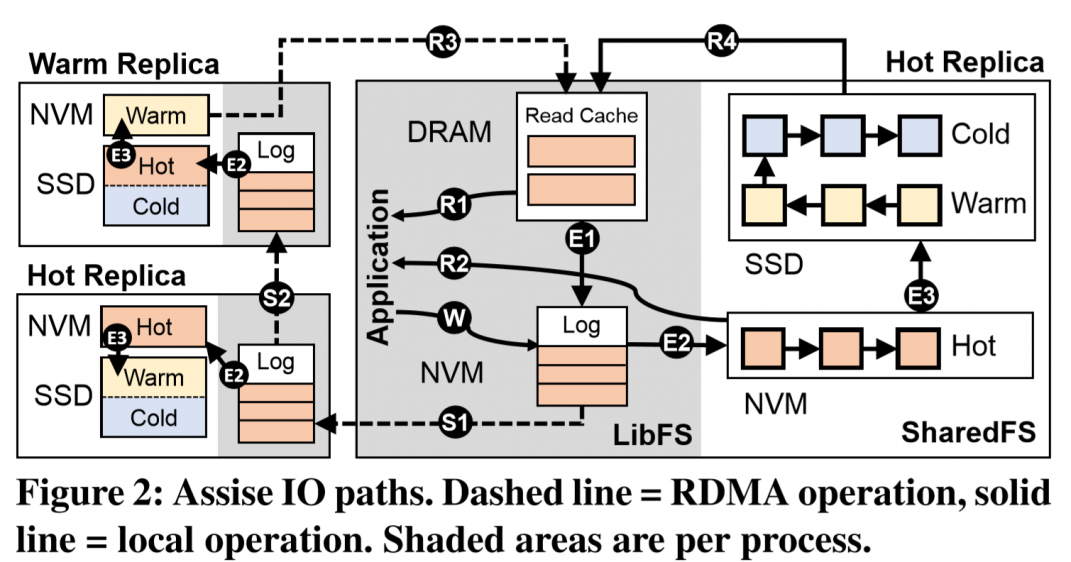
Write:
- Write to local NVM, as an update log rather than a block cache. (W)
- Chain-replication by RDMA (S1, S2). The last replication sends back ack (R3).
Two ways here, one is pessimistic for fsync. One is optimistic by delaying replication to *coalesce tmp writes*.
- When update logs fill beyond a threshold, evict them to SharedFS on NVM
two stage eviction (E2, E3) to multi-level storage (hot: NVM, warm, cold: SSD, NoF…) by LRU. And replicas parallelly evict to keep the same state for fast fail-over.
Read:
- Check local Read Cache on DRAM (R1)
- if not hit, check local sharedFS by extent tree index[3] (R2)
- if not hit, check sharedFS on warm replication for existence (R3). If yes, then check cold storage (R4)
- read cache: recently read data is cached in DRAM, except if it was read from local NVM. And data in read cache would be evict to update log (E1)
CC-NVM
CC-NVM provides Cache Coherence with linearizability (crash consistency with prefix semantics, “线性一致性”).
lease for 1 writer, N readers access
- Use lease to grant shared read or exclusive write
- LibFS get lease from Shared FS via syscall
- SharedFS enforces the process’s private update log and cache entries are clean and replicated before lease transfer.
- The lease transfer are also logged and replicated in NVM.
cluster manager (e.g Zookeeper) to keep information of location, lease , etc.
managers would be a bottleneck?
hierarchical lease delegation, which is done on client's sharedFS (on private directory)
- LibFS -> SharedFS -> cluster manager
- If lease is held by another SharedFS, wait.
Fail-Over & Recovery
LibFS recovery:
- SharedFS evicts dead logs (recover completed writes), expire lease and restart the process
- LibFS rebuilts DRAM cache
SharedFS recovery:
- store a freshly booted OS checkpoint on NVM to accelerate reboot
Note: like Windows' hibernate mode, but on NVM.
- initiate recovery for LibFSes by SharedFS log
Cache replica fail-over:
- not waiting for node recovery, just fail-over to a hot replica
- The replica's SharedFS will take over lease management
- The writes during failover will invalidate cached data of the failed node. And for tracking writes, all SharedFSes share a incremental-epoch bitmap.
Node recovery:
- cluster manager expire the node's leases
- sharedFS invalidates every written block since its crash
Use Strata's FS design and augment it with CC-NVM.
All RDMA connections are RC.
Eval
Dual Sockets CPU + DRAM + Optane PMM + NVMe SSD + CX3 IB
latency & throughput
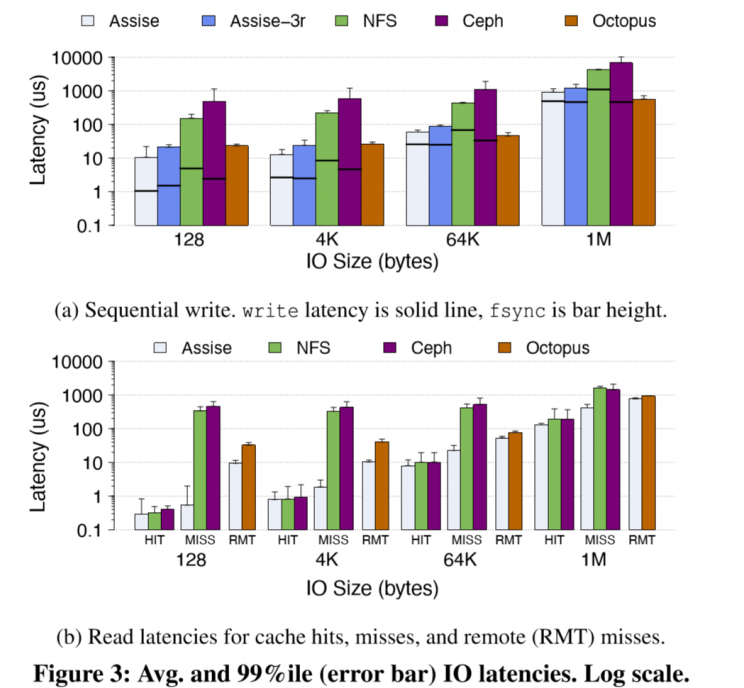
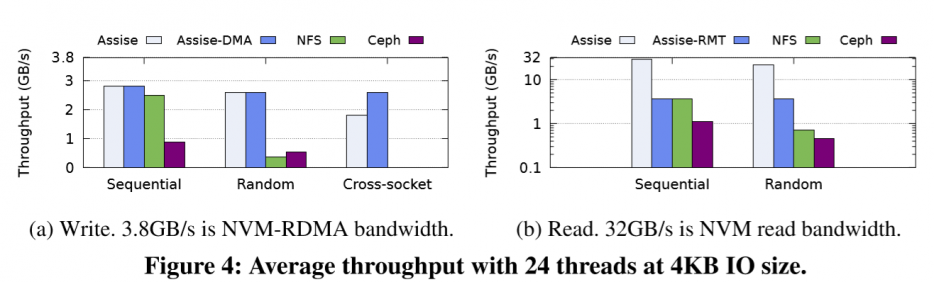
note: check application benchmarks(filebench, LevelDB…) in the paper
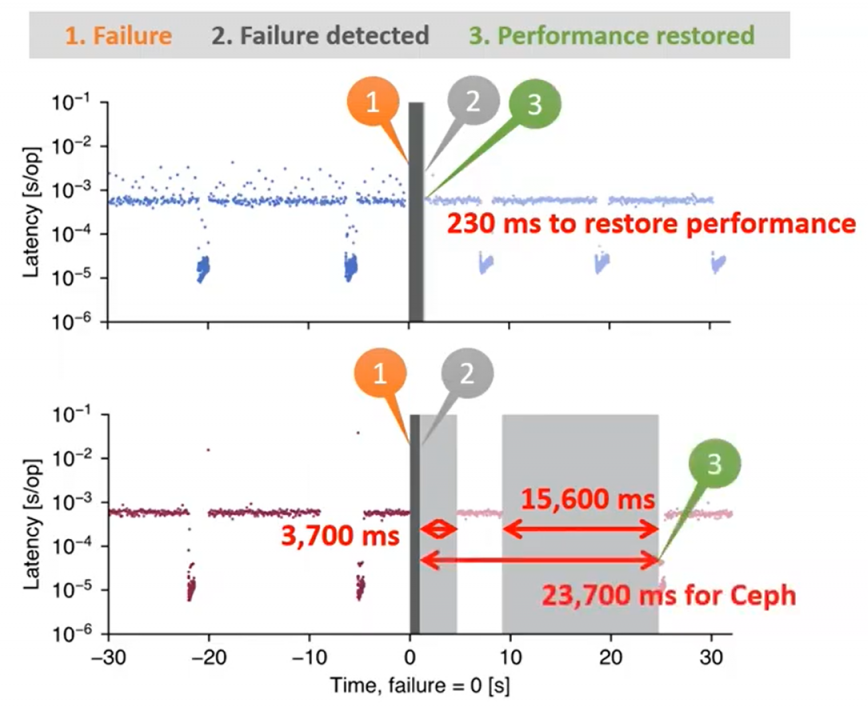
fail over
Test on LevelDB, Assise use only 230ms to restore perfmance, while 23.7s on Ceph
scalability
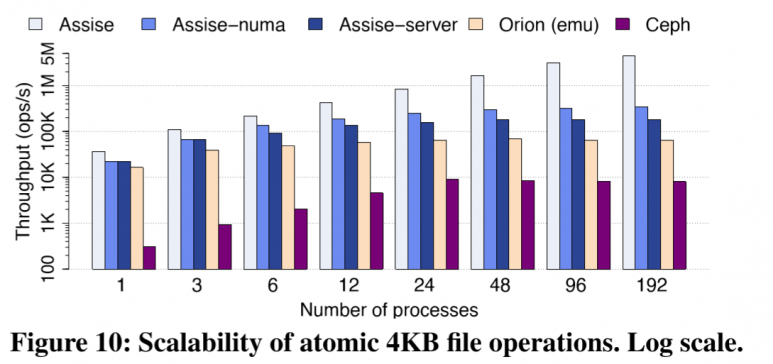
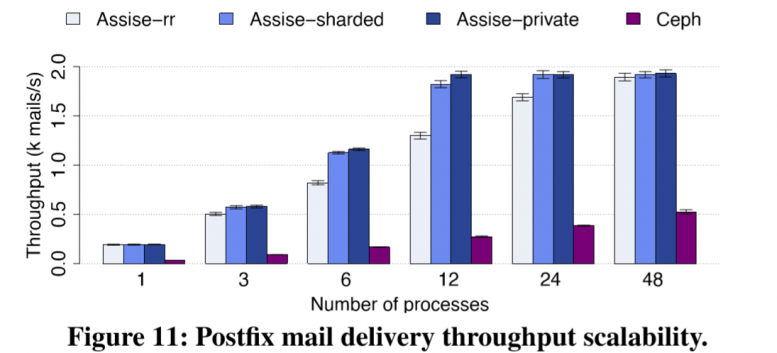
Assise's perf linearly scales, while Ceph is limited by MDS bottleneck. Assise outperforms Orion (emulation) by 69x and Ceph by 554x at scale.
rr (round-robin), sharded (recipents), private (directory) are different load balancers.
hierarchial coherence do have benefits.
refer
- Anderson, Thomas E., et al. "Assise: Performance and Availability via NVM Colocation in a Distributed File System." 14th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 20). 2020.
- [OSDI'20] Assise: Distributed FS w/ NVM Colocation - 冰语 on zhihu
- Extent_tree - Trees - btrfs wiki