本文简单列一些RDMA做分布式KVS的工作。这些工作在RDMA的特性基础上针对RPC、事务等方面做出了针对性优化来提升指标。
Palif ATC '13
Palif[1]在索引上用cuckoo hashing,读取时通过多次的RDMA read来获取数据,减少服务端的CPU开销。更新的时候还是通过send/recv来做。
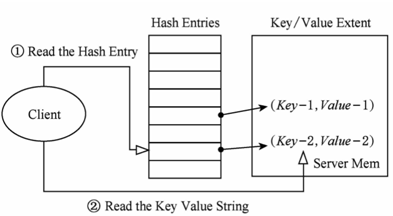
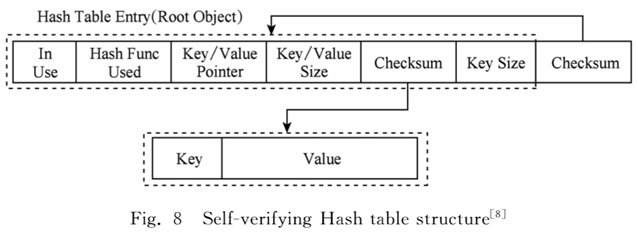
在cuckoo hashing上解决竞争写问题比较复杂,Palif只使用了校验的方法来防止脏读。在每个键值数据里维护了两个checksum,读取时做校验保证正确性。
因为是个早期工作,对比的对象都是以太网和IPoIB的。
HERD SIGCOMM '14
HERD[2]通过实验发现RDMA写的延迟比读更低,同时RC Read在并发场景下扩展性差,inbound操作在100个以上客户端下就出现明显性能下滑。而UD send和RC write就没有这个问题。outbound操作除了UD Send都会出现明显因竞争的下滑。
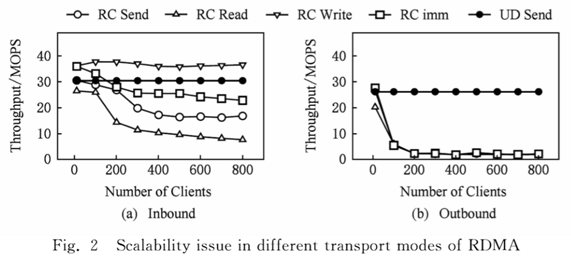
HERD基于这个发现,重新设计了RPC。在请求时,通过UC write来写入数据到服务器端的某一个区域上。服务器端通过Scan来发现新的数据,然后通过UD来返回RPC的请求结果。
FaRM NSDI '14
因为注册多了后,页表过大,导致cache命中率降低。FaRM[3]设计了2GB大页(MTU)来降低页表大小。
因为在RDMA NIC上维护过多QP同样会降低cache命中率,FaRM就设计了共享QP。
在索引结构上,设计了一个链式跳房子哈希(Chained associative hopscotch hashing )。
- hopscotch hashing是通过在item后增加标志位来减少线性探测的开销
- chained指的是无法通过标志位判断后面顺序的位置时,就转成拉链法。)
- associative指的是希望在hash过程中保持一定的关联性。
- 把一个bucket切分成$H/2$个slot来存数据。
- 大值跨slot存放
- 单次读取时读两个buckets
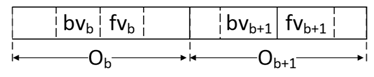
- 维护前后版本号来保持跨bucket的数据一致性
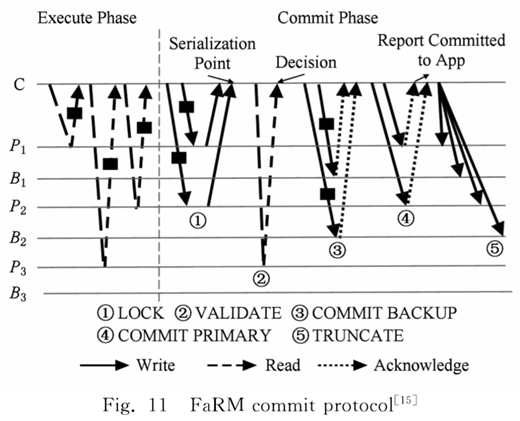 事务管理上,通过one-side verb来操作,OCC来做2PC。流程如图所示。
事务管理上,通过one-side verb来操作,OCC来做2PC。流程如图所示。
FaSST OSDI '16
FaSST[4]通过实验发现RDMA的UD连接模式也很可靠(50PB传输里没有出现丢包的情况)。另外QP的长度受硬件限制,竞争多了就性能下滑。
用UD,可以减少QP的数量,但UD不支持单向操作,且MTU只有4K大小,会限制事务的记录大小。UD有一个特性,Doorbell Batching,在信息到达后,可以批量地通知CPU,减少CPU消耗。
FaSST还用coroutine(master+worker)来隐藏网络延迟(?)
事务上和FaRM类似,OCC+2PC。
FaSST相对FaRM在只有一半硬件资源的情况下,可以达到两倍FaRM的性能。
DrTM SOSP '15
传统的分布式事务流程通过如两阶段的锁访问来实现,开销大。
DrTM[6]使用了HTM和2PL结合的方法来做分布式事务。HTM是基于硬件的事务内存。
Nessie TPDS '17
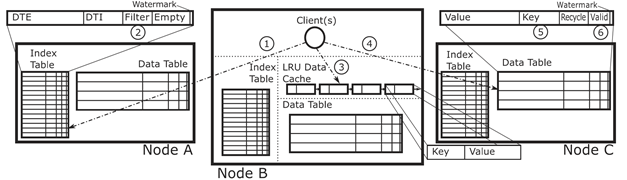
Nessie[7]设计了一个完全解耦的结构,让客户端作为访问中的主导,避免服务端CPU在关键路径上。然后设计了一些本地缓存的管理策略
索引上用N-way cuckoo hashing。
KV-Direct SOSP '17
KV-Direct[9]通过可编程RNIC,扩展网卡的能力,把原来需要CPU处理的功能下放到网卡,从而可以通过增加PCI上的网卡数量来快速扩展(线性扩展能力)。性能非常高,IOPS 1.2 billion。
文章设计了针对隐藏PCI设备发起访问的延迟的优化策略(因为PCI发起DMA延迟很高,也就是outbound操作)。另外拓展了一些访问的接口。
类似的思路,有一些在后端上用ARM、FPGA来代替CPU的工作。
ref
- Mitchell, Christopher, Yifeng Geng, and Jinyang Li. "Using One-Sided RDMA Reads to Build a Fast, CPU-Efficient Key-Value Store." 2013 USENIX Annual Technical Conference (USENIX ATC 13). 2013.
- Kalia, Anuj, Michael Kaminsky, and David G. Andersen. "Using RDMA efficiently for key-value services." Proceedings of the 2014 ACM conference on SIGCOMM. 2014.
- Dragojević, Aleksandar, et al. "FaRM: Fast remote memory." 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14). 2014.
- Kalia, Anuj, Michael Kaminsky, and David G. Andersen. "FaSST: Fast, Scalable and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs." 12th {USENIX} Symposium on Operating Systems Design and Implementation (OSDI 16). 2016.
- FaSST – Fast, Scalable and Simple Distributed Transactions · Columba M71's Blog
- Wei, Xingda, et al. "Fast in-memory transaction processing using RDMA and HTM." Proceedings of the 25th Symposium on Operating Systems Principles. 2015.
- Cassell, Benjamin, et al. "Nessie: A decoupled, client-driven key-value store using RDMA." IEEE Transactions on Parallel and Distributed Systems 28.12 (2017): 3537-3552.
- Su, Maomeng, et al. "Rfp: When rpc is faster than server-bypass with rdma." Proceedings of the Twelfth European Conference on Computer Systems. 2017.
- Li, Bojie, et al. "Kv-direct: High-performance in-memory key-value store with programmable nic." Proceedings of the 26th Symposium on Operating Systems Principles. 2017.
- Several Papers about RDMA KVS · Columba M71's Blog