Ceph /ˈsɛf/ 是一个新兴的开源分布式存储系统,现在支持块存储、文件存储、对象存储。本文尝试从high level总结它的一些设计特性。只是初学者,描述可能有很多地方错误、不完善,欢迎指出。
部件
Ceph有几个基础的部件:
- Object Storage Device (OSD): OSD指的就是存储设备,负责数据存储。不同于传统的块存储设备,OSD是以对象为单位(更高层)的存储设备。一个OSD有自己的CPU, NIC, disk, cache。后面也会提及如何使用OSD的计算能力。OSD以集群的形式存在。
- Metadata Server (MDS): MDS负责元数据的存储。不同于GFS、HDFS的元数据管理,因为管理的是对象数据,MDS只管理命名空间,不管理allocation list。数据的访问靠计算来获得位置。另外MDS也以集群的形式存在,没有单点故障问题。MDS集群上都是无缓存的同步操作。
- Monitor: Moniter是一个轻量的集群,用来对OSD的状态进行监控和管理。
- Clients: 就是Ceph的实例,访问的发起者。然后向外提供一个类POSIX接口。
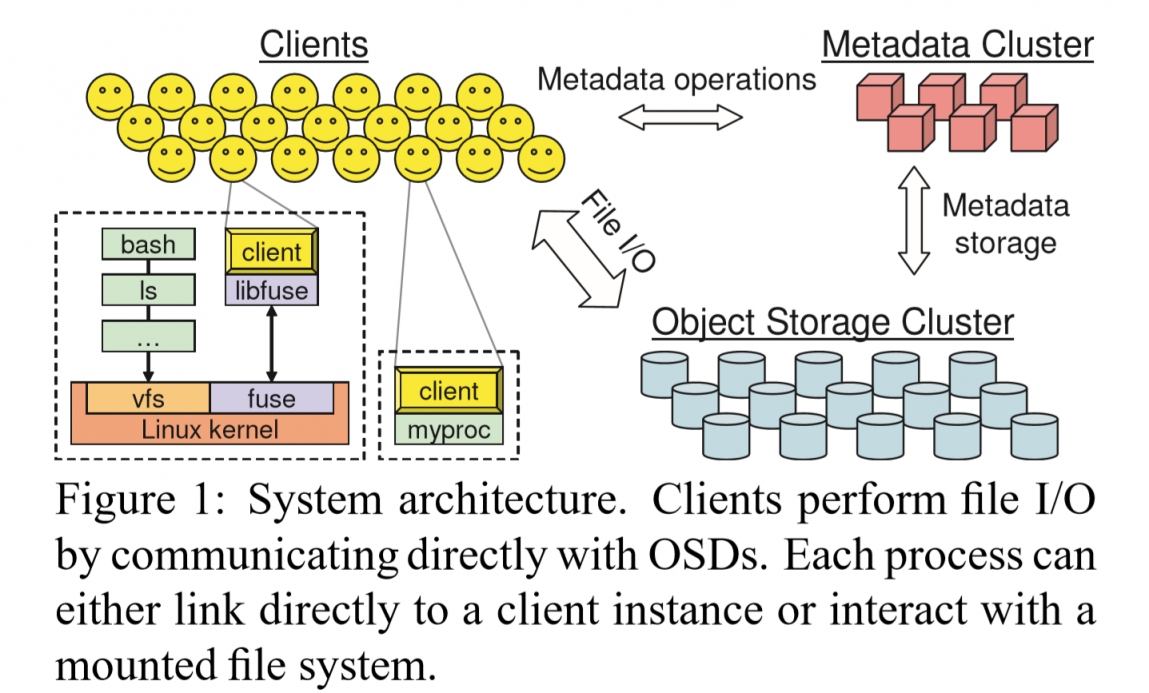
Decoupled Data and Metadata 数据与元数据解耦
 如上图所示,Ceph通过图中所示的访问方式来组织数据。每个文件被切分成小对象,每个对象通过简单的哈希来对应到一个PG (placement groups)上,每个PG通过CRUSH操作来映射到具体的OSDs上。
如上图所示,Ceph通过图中所示的访问方式来组织数据。每个文件被切分成小对象,每个对象通过简单的哈希来对应到一个PG (placement groups)上,每个PG通过CRUSH操作来映射到具体的OSDs上。
这部分核心的就是CRUSH[5],Controlled, scalable, decentralized placement of replicated data。CRUSH本质上就是一个伪随机的哈希函数,可以把PG对应到OSD上。这样就可以通过计算来获得数据的位置。CRUSH除了一些placement rules以外,通过只输入PG和OSD cluster map就可以输出OSD。通过rules可以指定选择OSD的一些策略,如副本数量、放置位置、特定OSD的权重等。
OSD cluster map指的是OSD在物理上的结构分层,如机柜列、rack、服务器、OSD,需要手动设定。比如新加入一个OSD,那么map就会迎来一次更新。
Dynamic Distributed Metadata Management 动态分布式元数据管理
Ceph的MDS只管理目录项和inode,负载相对传统的元数据管理要轻很多。传统系统上元数据访问负载超过50%。
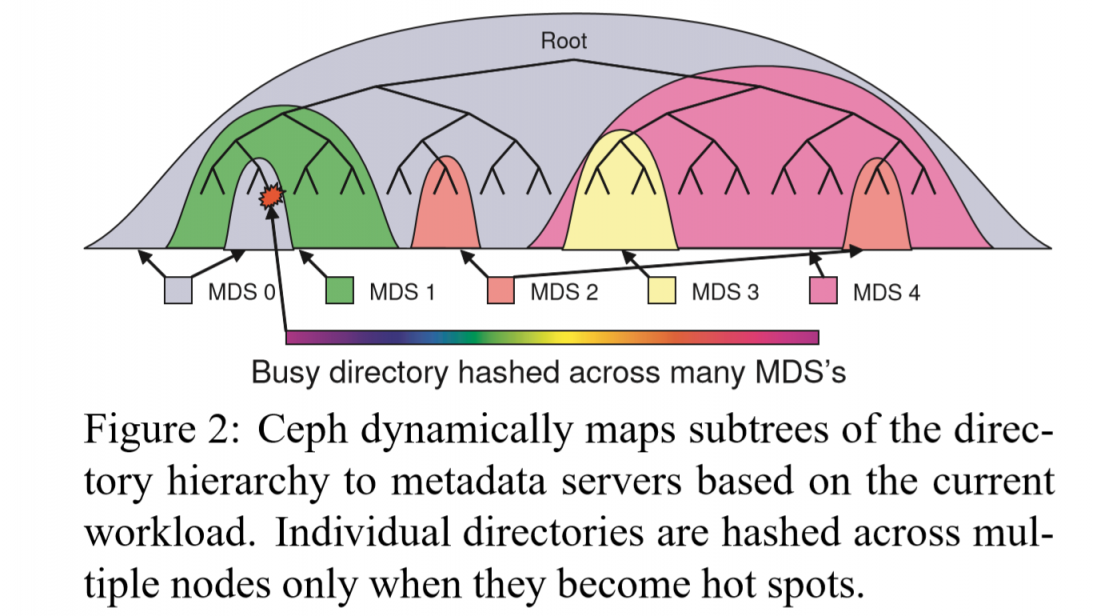 元数据管理的核心部分是Dynamic Subtree Partitioning[6],MDS集群基于此进行组织,能在节点之间自适应地按层级,来组织目录层级的元数据。
元数据管理的核心部分是Dynamic Subtree Partitioning[6],MDS集群基于此进行组织,能在节点之间自适应地按层级,来组织目录层级的元数据。
每个MDS,维护一个指数衰退的计数器,当被访问时,自己包括对应的所有上级结点进行自增。这计数值就代表了MDS的热度权重。
热点的元数据会被分割到不同的MDS上,突发读访问的数据会被复制多份,从而实现负载均衡(牺牲了locality)。
另外有一些有关safety的细节,不赘述了。
Reliable Autonomic Distributed Object Storage 可靠自治的分布式对象存储
RADOS即OSDs与Monitor组成的系统。OSD自己负责对数据进行复制、迁移、错误探测和故障恢复等的工作。
Ceph是一个强一致性的系统,在每次写入来临时,向CRUSH映射得到的OSDs中的Primary进行写入,Primary向Replicas转发数据。Primary获得replicas的落盘ack后,再返回ack。落盘的commit也等待replicas后,primary自己落盘,再向client返回。
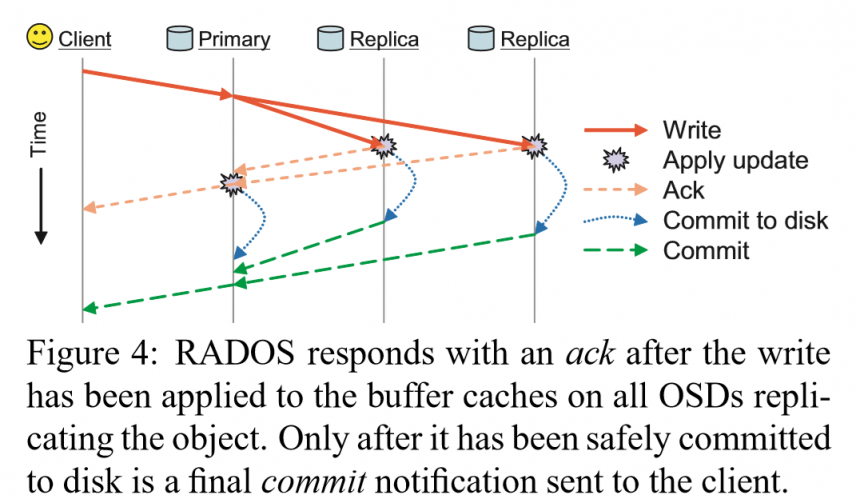 为保证一致性,每个读请求则落在primary上。
为保证一致性,每个读请求则落在primary上。
每个OSD通过维护一个版本号和对于每一个PG的最近操作的日志(更新或删除的对象的名与版本)。
primary OSD如果不响应,会先被置为down状态,请求全部转到第二个OSD上。如果还不恢复,就说明原来的primary挂了,一个新的OSD将替换加入到这个PG对应的OSDs中。受到影响的OSD,将更新自己的map,并分发map给其他OSD。【中间等待的方法可以过滤掉一些短时的问题,避免老是转移数据】
当某一个OSD收到一个新的OSD cluster map时,说明有新OSD加入或退出了。它会迭代每一个PG,再通过CRUSH算法计算出自己在这PG对应的OSDs中是不是primary。如果是,则开始接管primary的工作,收集副本的信息,进行更新。等到primary确定了正确状态,才开始响应请求。并行恢复,提高效率。
类似Raft的appendEnrties,OSDs利用心跳包互相检测如掉电等无法自检测的错误。Monitor集群用来统一提交错误信息。
OSD backend
前文提到,Ceph把存储抽象到对象层面。在对象背后,也就是OSD的存储后端上,这几年有很大的变化。
一开始用的是EBOFS[1]等文件系统,绕过了传统文件系统的一些缺点,能够直接和块设备交互。文件系统在元数据设计上和对象存储有类似的对应之处,同时也可以直接利用文件系统带来的缓存设计的便利。
但直接使用文件系统作为对象存储后端,也存在了很多缺点。如缺乏事务、check sum等能力,元数据的管理效率低。为了实现事务等支持,需要在用户态上实现WAL,进而又会引发读后写、写放大等问题。类似的,后来也使用了BTRFS、XFS等文件系统,但仍然受到文件系统这些弊端带来的影响。同时单一的文件系统也无法很好的兼容新型的存储器件。
接下来的NewStore使用了键值存储数据库(如LevelDB)来管理保存元数据。再通过多步映射的方法来找到在文件系统中保存的数据的位置。这样做减轻了元数据管理的压力,但因为保存数据的仍然是文件系统,仍然没有避免写放大等问题,然后LSM Tree的键值存储也有自己的写放大问题等。
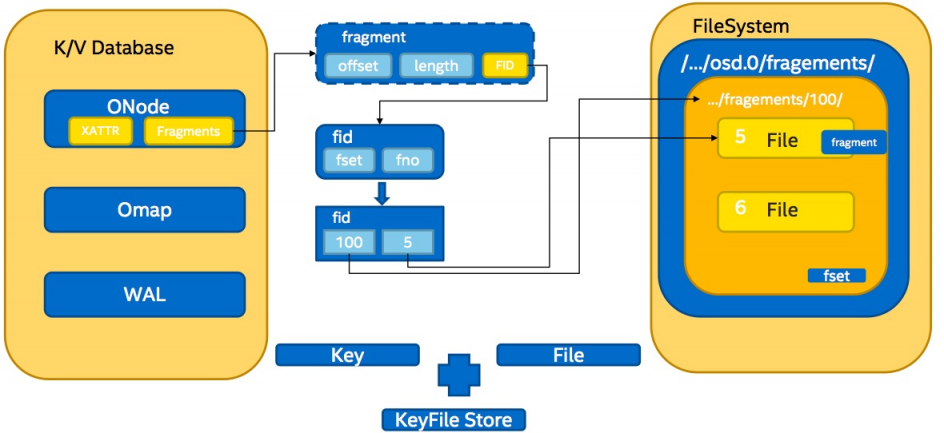
目前使用率最高的BlueStore,不再使用文件系统来保存数据,将键值数据库下面的文件系统换为自己一个轻量的BlueFS。BlueFS为键值数据库提供Env相关接口。而在数据的保存上,则直接操作裸的块设备。
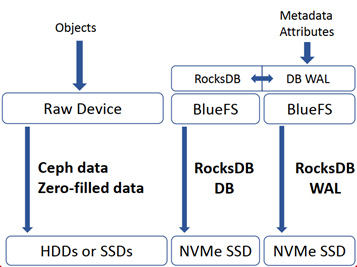
下图为BlueStore的数据流示意图。SST指LSM的SSTable。
 BlueStore并不完美,抛弃了文件系统,就抛弃了前文提到的便利的缓存系统,在用户态上构建出一个类似效果的缓存系统存在很大挑战。然后就是键值数据库自身的一些问题。
BlueStore并不完美,抛弃了文件系统,就抛弃了前文提到的便利的缓存系统,在用户态上构建出一个类似效果的缓存系统存在很大挑战。然后就是键值数据库自身的一些问题。
Reference
[1] Weil, Sage A., et al. "Ceph: A scalable, high-performance distributed file system." Proceedings of the 7th symposium on Operating systems design and implementation. 2006. (OSDI 2006)
[2] Aghayev, Abutalib, et al. "File systems unfit as distributed storage backends: lessons from 10 years of Ceph evolution." Proceedings of the 27th ACM Symposium on Operating Systems Principles. 2019. (SOSP 2019)
[3] 李翔. Ceph分布式文件系统的研究及性能测试. Diss. 西安电子科技大学.
[5] Weil, Sage A., et al. "CRUSH: Controlled, scalable, decentralized placement of replicated data." SC'06: Proceedings of the 2006 ACM/IEEE Conference on Supercomputing. IEEE, 2006. (SC 2006)
[6] Weil, Sage A., et al. "Dynamic metadata management for petabyte-scale file systems." SC'04: Proceedings of the 2004 ACM/IEEE conference on Supercomputing. IEEE, 2004.(SC 2004)
注
看完File Systems Unfit as Distributed Storage Backends: Lessons from 10 Years of Ceph Evolution再来更新。 更新完毕
最近很久没更新文章,之前一直在学习MIT 6.824……