Problem
续前文提出的问题,传统的HHD和SSD具有非常大的物理区别,HDD需要磁头的多次运动才能完成随机I/O操作,而SSD拥有较好的并行性,同时有擦写寿命问题。WiscKey就是针对SSD场景的一个优化方法。
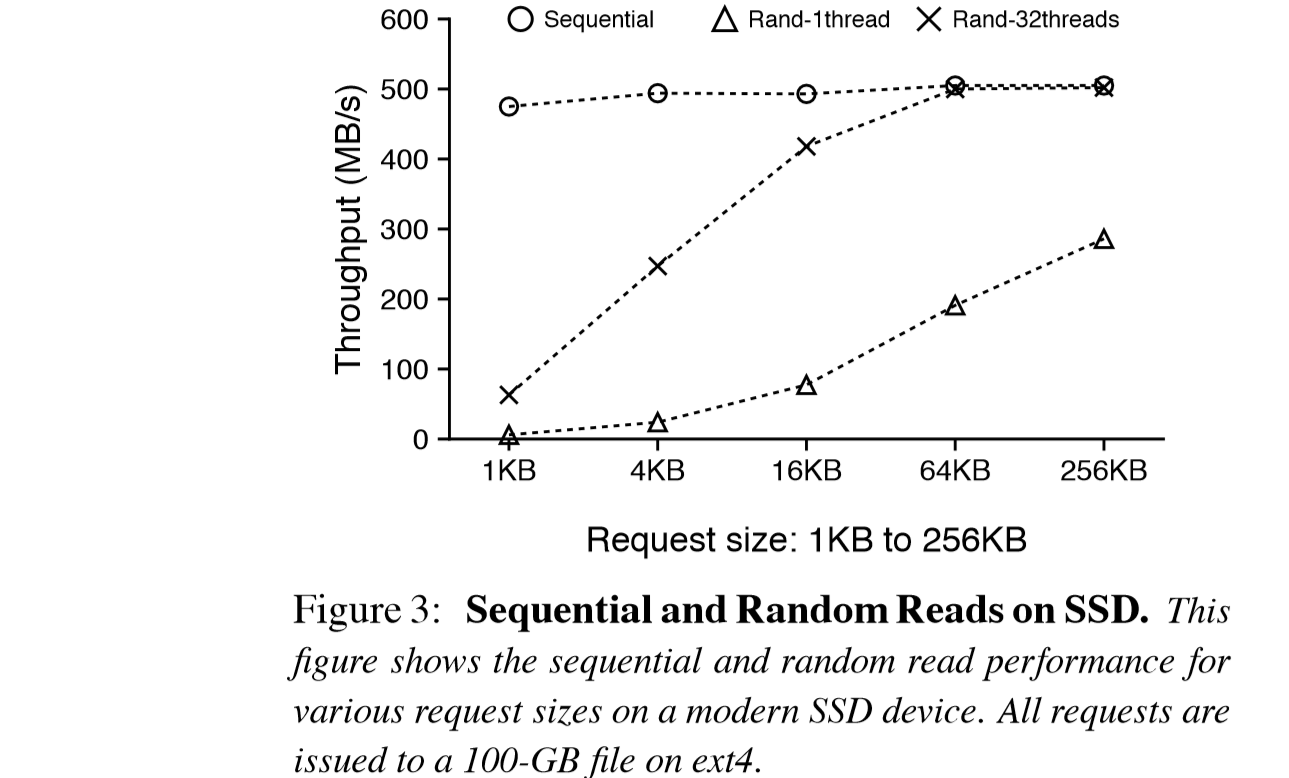
如图所示,随着request size提升和操作的线程数的增加,随机读的速度甚至可以和顺序读的速度相等,并没有像HDD那样有非常大数量级的差距。这让LSM为了减少随机I/O而付出的额外的I/O变得不再必要,也没有利用好并发性的特点。
另外,SSD的成本相对HDD要高昂很多,SSD相对HDD有更低的使用寿命,会有一个全擦写次数的寿命值。而且由于设计原理,SSD在进行写入的时候,需要进行先擦后写,被写入的page所在的block需要被全部擦除(存储单元共用一个衬底),导致对于SSD来说,写放大是一个天生存在的问题,当寿命达到极限之后,Block里的电子操作就会出现问题。
LSM一个非常明显的特性就是读写的放大:
- 在读上,查询的过程需要贯穿LSM的多层结构,直到找到为止,$L_0$中的所有数据还都需要遍历。另外类似B+ Tree的,在单文件内还需要读多次元数据块。
- 在写上,因为需要保持顺序性,首先LSM本身就维护了超出原始输入数据量的数据。另外,在做合并的时候,假如$L_{i-1}$层相比$L_{i}$层多N倍的文件数量,在最坏的情况下,一次的合并需要遍历访问N次的数据。而在更极限的情况下,某次写入引发了$L_i$到$L_{i+k}$的$k$次合并,则会有kN倍的写放大。
WiscKey
FAST 16上的WiscKey提出了一个解决读写放大的方法,基础的思想就是Key-Value Separation,将LSM Tree中的value抽离出来,存放在一个value log的地方,这样在做压缩合并的时候,操作的只有LSM上的Key数据,不需要移动value。
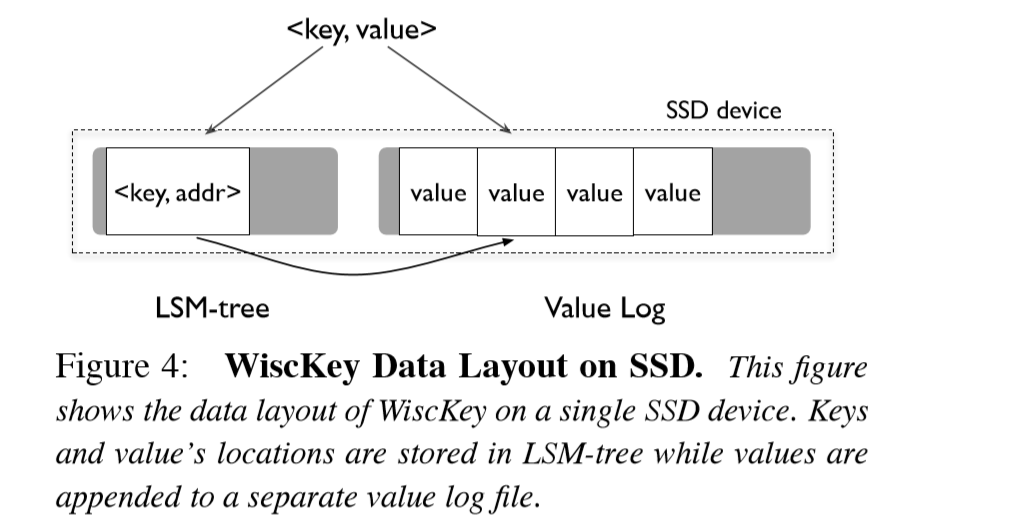
如图所示为WiscKey的思想框架图。由于在WiscKey中的LSM-Tree的大小大大降低,在合并的时候不需要再去移动value(尤其modern workload中的大 value),写放大减少明显。而针对读场景,虽然需要再去value log中读取,但是由于LSM树大小的减少,可以扩张单level内的文件数量,同时cache中存放的数目也更多,也有更好的表现。
Range Scan
Range Scan在LevelDB等中是一个常见且重要的feature,原来在LSM-Tree中调用Next(), Prev()的时候引发的都是顺序读取。而WiscKey中变成了较为低速的随机读。
为解决这个问题,WiscKey利用SSD的并行性,开了多线程来进行预读取。读key, address时,就直接取出多个,用32线程来跑满SSD的带宽。
Garbage Collection
原来的LSM在处理删除数据的时候,做完标记,再压缩合并之后,无效的value自然不会被保留,而现在需要专门去value log(注意vLog中存key也存value)里面做GC。

WiscKey给出了一个在线的轻量GC策略,如上图所示为value log中一个数据格式。每对数据的格式为:(key size, value size, key, value)。tail和head的位置都放在内存中。
每次GC时从tail开始读一堆keys&values,拿着这些key去LSM-Tree中验证是否有效,如果有效,则追加到head端,然后把tail更新。这样在tail到head里的数据就可以尽量保证都是valid data。
Crash Consistency
分离了key value后,写入也成为了非原子操作,对于异常情况的一致性,也需要额外的操作。
基于现代文件系统的追加写特性,WiscKey中,如果新插入的value x丢失了,则以后所有的value全部丢失。
- 如果key丢失了,那么显然vLog中对应的数据会被当做被删除数据,会被GC掉。
- 如果value丢失了,就通过vLog中存的key来找有没有对应的value,没有就删掉key。
因此,可以提供等同LevelDB的一致性。这里发现实际上vLog可以代替LSM-Tree中提前写入的 Write-ahead logging(WAL)。
Experiments
WiscKey在读、写、GC速度上全面好于LevelDB,尤其在value size大的场景上。具体数据请看原文或参考资料中的其他blog。
Space Amplification
因为SSD比较贵,所以探讨了下空间放大的问题,因为WiscKey相当于又加了一层索引到vLog,是有额外的空间放大。(笔者觉得这倒算不上trade-off,优化的一些元数据存储小代价而已)
CPU Usage
因为经常32线程做预读并发操作,在读的时候WiscKey会有很多CPU的开销。
在顺序写入的场景中,LevelDB的开销更大,因为WiscKey不用写WAL了。
Thinking
WiscKey感觉是一个非常通用的解决方案,我看到一些论坛上看到这个工作的时候,都说其实他们本身的部署设计就是这样的,没想到16年才发了这篇文章。
BlobDB、Titan、阿里云等都有类似的尝试。
有个问题,每次做GC实际上都要移动所有数据,也会有类似压缩合并的移动数据造成的写放大呀,不知道原文为什么不探讨一下。
参考资料
- Lu, Lanyue, et al. "Wisckey: Separating keys from values in ssd-conscious storage." ACM Transactions on Storage (TOS) 13.1 (2017): 1-28.
- xiehui.me
- WiscKey: Separating Keys from Values in SSD-Conscious Storage [读后整理]-cnblogs