介绍
在上篇的两个顶会的虚拟试衣的文章都是来自于大山中学的工作,在这个系列后,他们又做了一个可变pose任务的,结合了对抗训练的工作,暂时按下不表。回顾一下,VITON和CP-VTON两个模型都在变形衣服的Stage 1上花了比较多的功夫。一个用了Non-param TPS,一个用GMM网络来做变换,同时都需要对图像进行human parse和pose estimate步骤,开销较大。尤其是CP-VTON,在笔者的实验中,由于LIP数据集本身不够干净,GMM的训练效果就不是很理想,对于遮挡等情况非常不鲁棒。
一篇是End-to-End Learning of Geometric Deformations of Feature Maps for Virtual Try-On,另一篇是Unsupervised shape transformer for image translation and cross-domain retrieval。
End-to-End Learning of Geometric Deformations of Feature Maps for Virtual Try-On
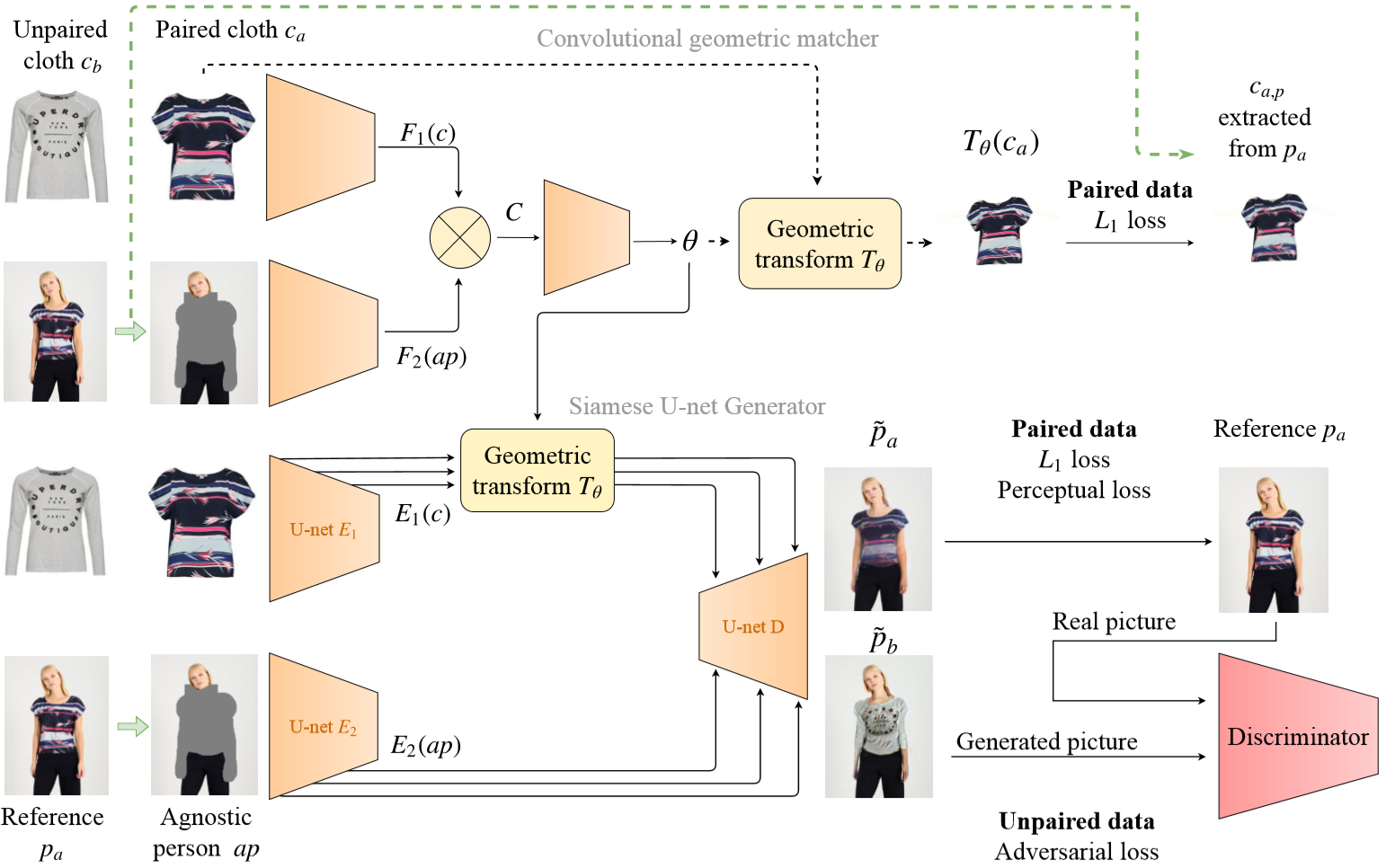
网络框架如上图所示,Agnostic person $ap$指的是类似以前使用human parser和pose estimator的人体特征,用于保留identity和去强监督,之前的CP-VTON需要抠出人体的mask和pose,本文只需要人体上半部分的mask。
 可以看到其结构和CP-VTON非常相似,上半部分的网络使用两个卷积网络分别提取$c$, $ap$的特征后,过Correlation Layer,继续做卷积获得一组进行几何变换的参数,用这组参数用来进行标准衣服图片的变换。在CP-VTON中这就是Stage 1的网络,需要使用L1 Loss单独训练。
可以看到其结构和CP-VTON非常相似,上半部分的网络使用两个卷积网络分别提取$c$, $ap$的特征后,过Correlation Layer,继续做卷积获得一组进行几何变换的参数,用这组参数用来进行标准衣服图片的变换。在CP-VTON中这就是Stage 1的网络,需要使用L1 Loss单独训练。
本文提出的端到端方法则是使用这套参数对U-Net的Encoder的skip connection的每个scale的feature map做几何变换,这一步是为了能够在下半部分的网络中可以直接输入一个标准衣服图片,同时避免不对齐的问题。在CP-VTON中,则是使用了Stage 1输出的对齐好的衣服图片作为输入的方法进行规避,所以只能分阶段训练。
下半部分的U-Net中,输入的两张图片分别用不同的Encoder,变换后concat喂给Decoder。需要注意的是,如果是要计算unpaired adversarial loss的话,标准衣服图片需要输入两张,输出两张合成图片,paired用来获得L1和VGG Loss,unpaired用来对抗训练。用的WGAN-GP做基础,Adam优化一共四个Loss。
\[L = \lambda_w L_{warp} + \lambda_p L_{perceptual} + \lambda_{L_1} L_1 + \lambda_{adv} L_{adv}\]本文用的是LPIPS(linear perceptual image patch similarity )作为评价指标,用paired adversarial loss的模型在数据上效果最好。LPIPS是一个类似perceptual loss的设计,用AlexNet做提取。
感觉是仍然想用perceptual的方式,但怕变成直接优化指标?
最后,没给超参设置,源码在未来放出。
思考
关于在人体特征ap上的修改,其实在训练的时候也发现到,用一些SOTA的pose estimator对于模型提升没有什么效果,但换成CE2P这种SOTA的human parser后,则有比较明显的提升。
实验里提到,在inference的时候,mask抠的不好也不太影响图片质量,这个结论挺有趣的,说不定可以降低前向预处理的开销,但现在来看,为了保持identity,对头发还是得抠准的,所以还是得用SOTA的parser。

把前文一直沿用的compose mask做refine的方法换成了端到端一次性的生成过程,就方便引入对抗训练来提高图片质量,用组合mask的方式过于依赖coarse result的质量了,很容易出现尺寸不匹配的时候,手臂衣服边缘不匹配的问题。对feature map做变换的思路,在STN一文中也曾提到过。
没有源码,没复现出来
Unsupervised shape transformer for image translation and cross-domain retrieval
本文给出了一个Unsupervised Shape Transformer (UST),可以在真unpaired的情况上训练(前文的都是通过unparied造paired的方法),在应用上可以完成穿衣服和脱衣服两个任务的模型。

Reference
End-to-End Learning of Geometric Deformations of Feature Maps for Virtual Try-On, Thibaut Issenhuth, Jérémie Mary, Clément Calauzènes
Unsupervised shape transformer for image translation and cross-domain retrieval, Kaili Wang, Liqian Ma, Jose Oramas, Luc Van Gool, Tinne Tuytelaars
Toward Characteristic-Preserving Image-based Virtual Try-On Networks, Bochao Wang, Huabin Zheng, Xiaodan Liang, Yimin Chen, Liang Lin, Meng Yang
VITON: An Image-based Virtual Try-on Network,Xintong Han, Zuxuan Wu, Zhe Wu, Ruichi Yu, Larry S. Davis.