介绍
本文主要讲在2D虚拟试衣这个任务上两个效果比较好的工作。主要是两篇文章,一篇是VITON: An Image-based Virtual Try-on Network发于CVPR 2018,另一篇是Toward Characteristic-Preserving Image-based Virtual Try-On Networks发于ECCV 2018。

任务
现状与挑战
虚拟试衣(Virtual Try-On)的相关工作有很多。市面上的商用产品基本是生成一个人体的3D model,在这个model上进行衣服的试穿,优点就是算法很稳定,但画面的真实性就得不到保障(不够sharp),而且扫描3D等操作开销也大(或者只能手动输入大概数据)。2D上做转换的传统网络在衣服有较大形变的情况下效果都很糟糕,限制了pose。
在训练的数据集上,获得paired数据的挑战也很大,需要模特同样姿态穿两件衣服。
这系列的方法优点
总的来说,目标是希望能够输入一个任意姿态任意衣服的人$I_i$,一个衣服图片$c_i$,最后能输出一个穿着这件衣服的人。同时衣服上的细节,人体不被覆盖的细节都能够被保存下来。这系列方法的时间开销相对较大,步骤也麻烦,但生成效果较好较稳定,使用的Refine Network等手段来约束衣服的细节保留。
VITON
因为前文阐述的数据集过于难造,本文则还是希望通过已有的模特图片来进行训练,但这样潜在的问题是输入的图片有过强的监督造成过拟合。所以在输入上先进行一个Stage 0的数据准备工作。

如上图所示,通过输入的$I_i$检测出其Body shape(单通道),pose map(18个pose,18个通道),抠图得到的人的识别图(三通道RGB,这里使用了人脸和头发,事实上也可以包括其裤子等不希望被改变的部分)。通过这样的操作来减少输入图片的参考力度。每个输入map的大小均为256*192
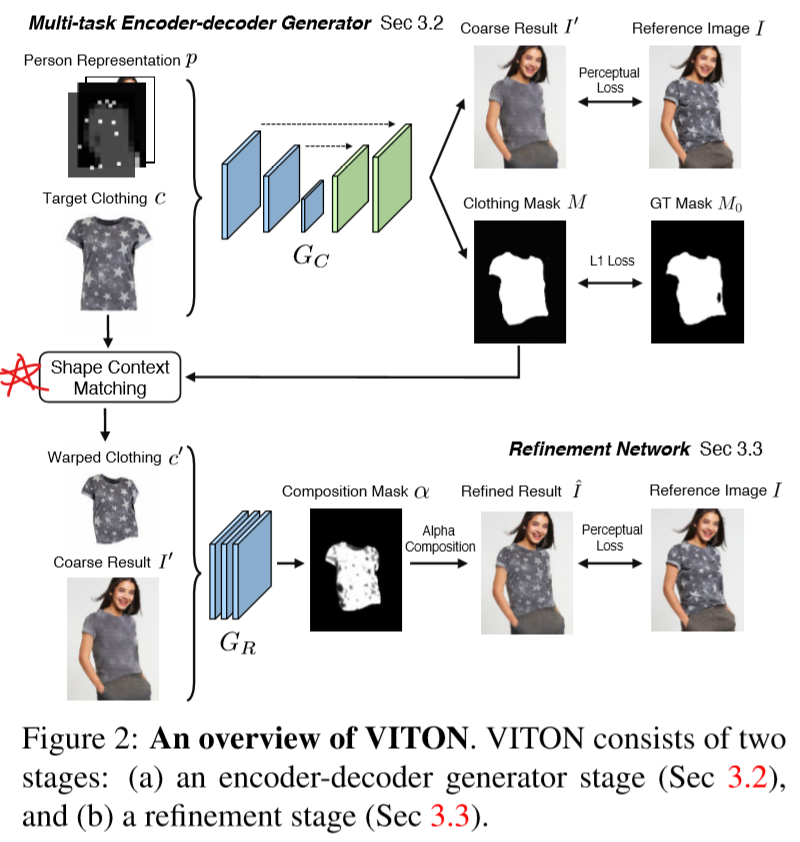
如图所示,VITON网络主要分为两个部分。第一个部分输入的是标准的待穿衣服图片$c_i$,和人体如上切分得到的22个通道的特征信息$p$,输入一个类U-Net的Encoder-Decoder模型,输出一个合成的穿指定衣服的人图$I^{'}$和衣服的Mask,$M$代表的是变形之后的衣服图片。
在这个Stage中,需要计算的Loss为$I'$和$I$的Perceptual Loss,生成Mask$M$和真实Mask$M_o$的L1 Loss。$I$是本来就有的数据集,$M_o$则来自于数据集上的抠图处理。
最后的Loss为:$L_{G_c}=\sum_{i=0}^{5} \lambda_{i} \lVert \rVert_1 + \lVert M-M_o \rVert_1$
在这个Stage 1生成的图片常常难保证待穿衣服的细节信息,则进入Stage 2。
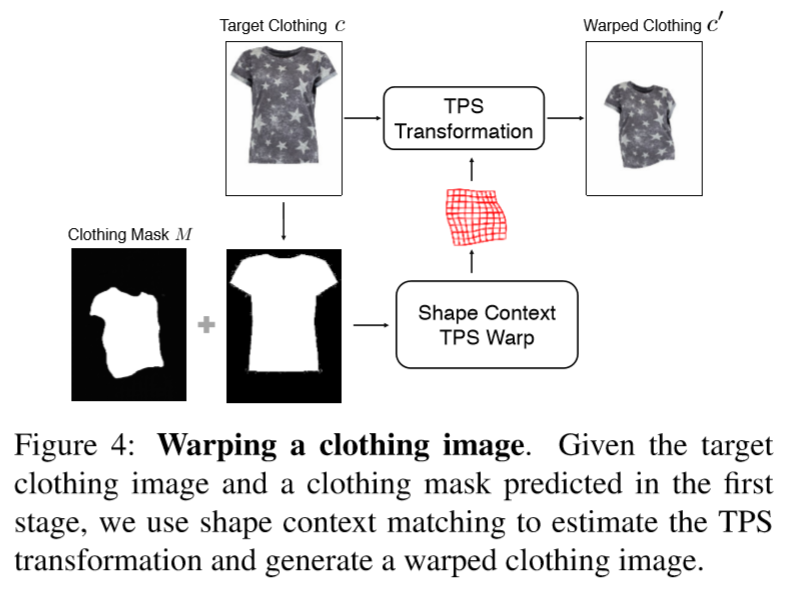
如图所示,通过Stage 1生成的$M$和原始标准衣服图片的Mask来计算TPS变换的参数,将这套参数使用到标准图片上,生成一个变形衣服图$c'$。对Stage 2的网络$G_R$输入变形衣服图片和Stage 1生成的初步结果$I'$,输出一个组合mask$\alpha$,来组合两张图片生成refined result $\hat{I}$,即$\hat{I}=\alpha \bigodot c' +(1-\alpha)\bigodot I'$。
利用Perceptual Loss来优化$G_R$,除此之外,对组合mask施加一个L1 loss和Total Variation Norm,使得最后Stage 2的优化目标为:
$L_{G_{R}}=L_{prec}(\hat{I},I)-\lambda \lVert \alpha \rVert_1 + \lambda_{TV} \lVert \nabla \alpha \rVert_1$
具体实现细节与量化结果不表,但由于整个网络是2 Stage的(事实上算上切分人脸,是三个步骤),又使用了TPS等算法,整体的时间开销比较大,一张图在K40上约需要0.6秒。
CP-VTON
CP-VTON基于前面这个工作,增加了一个“GMM模块”减少了计算量,使用一个网络来模拟TPS变换过程,同时改善了衣服细节的保留效果,修复了coarse-to-fine strategy对misalignment不够鲁棒的问题。
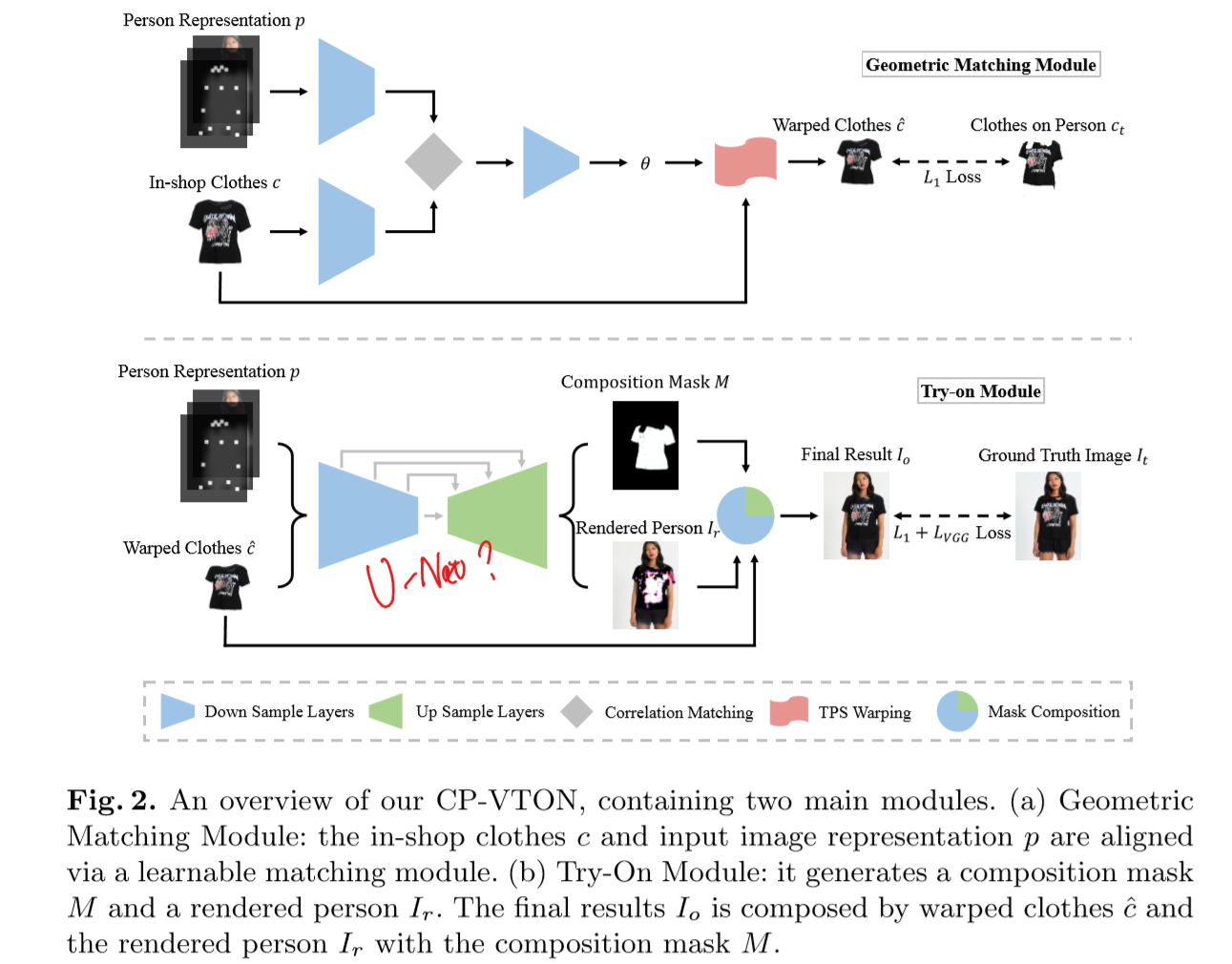
如图所示,为CP-VTON的网络架构。数据准备的过程是和前文类似的,但网络不再是一个输出mask和初步结果的多任务网络。在Stage 1中,先对输入的两个map进行卷积提取高维特征,然后通过一个correlation layer综合后继续卷积输出,输出一套变换参数$\theta$,使用这套参数对衣服图片$c$进行TPS变换。
优化的loss为变换后的衣服图片$\hat{c}$和抠下来的衣服图片$c_t$的L1 loss。即$L_{GMM}(\theta) = \lVert T_\theta(c) - c_t \rVert_1$
在Stage 2中用类U-Net网络,输入人的特征$p$(与前文的22通道一样)和变形后的衣服图片,输出一个组合mask和初步图片$I_r$。再使用组合mask对$I_r$和变形衣服图$\hat{c}$进行组合。使用L1 Loss和Perceptual Loss
则Stage 2的Try on Module的Loss为:
$L_{TOM} = \lambda_{L1} \lVert I_o - I_t \rVert_{1} + \lambda_{vgg} L_{VGG}(\hat{I},I)+\lambda_{mask}\lVert 1-M \rVert_1$
具体网络架构不表。
在Loss的设计上取消了前面工作使用的TV平滑,反而用其作为一个检测标准,感觉有点怪怪的,看github上的issue确实加了TV loss后马上崩坏。。效果有比较明显的提升,但对于有肢体遮挡到衣服的图片表现并不好,应该是使用mask的拼接方法对于这种情况不够鲁棒。本文没有给出完整的速度测试,笔者的模型仍在训练中。
Adversarial Training?
一般来说,在这种image translation的任务中加对抗loss都能有效提升图像的真实度(以及生成图像的不稳定性)。在本文的实验部分说明对抗训练起到的效果并不明显。
人都直接说,压根没把Adversarial加进去,装作insightful,,和 SeqGAN一比高下立判。
To Conclude
虽然方法是多步,而且几个加约束的方法(抠pose抠shape)都显得挺暴力的,但效果确实棒,计算过程虽然现在看起来麻烦,但说不定以后就有更好的近似算法来进行优化…第二篇文章实验部分阐述很足。
注
Thin Plate Spline
TPS变换是一种插值方法。传统的插值方法如双线性插值,仅仅能够保证映射前后的图片有四个基准点被准确映射。TPS则通过扭曲图片来保证有多个点能够同时被映射,同时最小化弯曲能量。
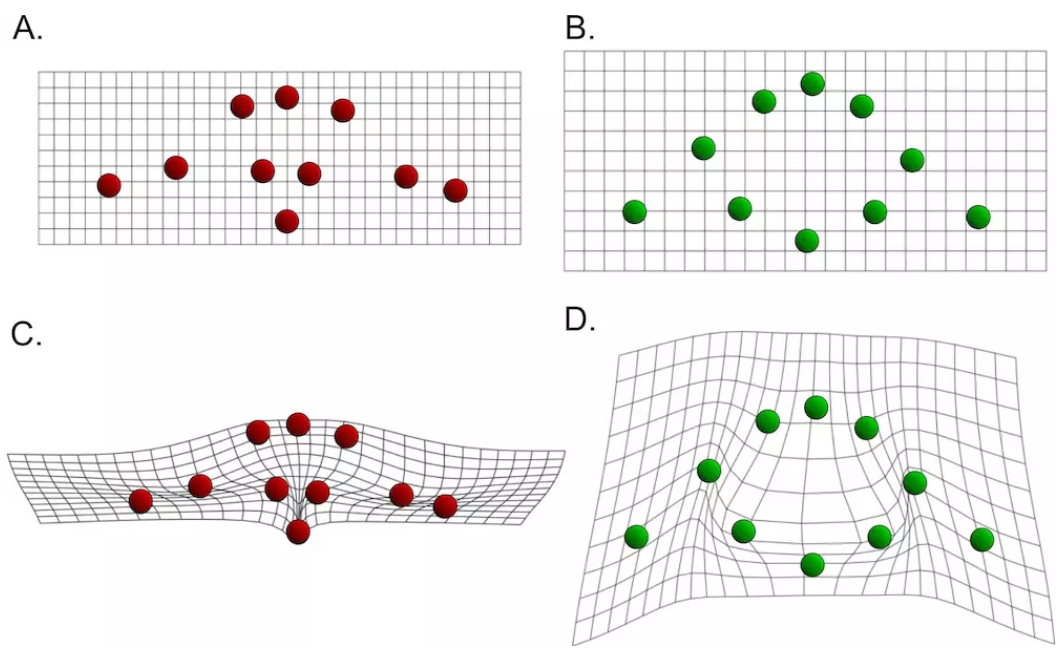
具体算法内容参考:Thin Plate Spline – 简书:今天又忘记密码
Perceptual Loss
Perceptual Loss是使用pre-trained VGG来对图片提取特征,使用多个浅层的输出激活值来计算MSE。来自于Style Transfer
Correlation Layer
出自FlowNet,主要就是计算两个feature map的correlation,具体的计算过程类似于conv,遍历f1上的patch对f2上每个可能位置同样大小的patch做匹配(即卷积计算),实际实现时会对匹配范围和stride进行限制。
Reference
VITON: An Image-based Virtual Try-on Network,Xintong Han, Zuxuan Wu, Zhe Wu, Ruichi Yu, Larry S. Davis.
Toward Characteristic-Preserving Image-based Virtual Try-On Networks, Bochao Wang, Huabin Zheng, Xiaodan Liang, Yimin Chen, Liang Lin, Meng Yang
文章内均有其代码开源地址。