序
最近在准备算法岗的面试, 就到处翻翻各种ML, DL相关的笔面试题, 看到这个深度学习一百问, 权作复习和分享使用了, 但是因为原作的知识点过于简单冗余, 就把其他准备的ML相关的知识整合写作一百个tips了。DL在前,ML在后
正文
DL
-
梯度下降算法的正确步骤是什么?
初始化参数->输入数据->计算loss->BP调节权重->重复迭代。
在以上的过程中, 其中初始化参数的trick包括Xavier, He(注1)等。Loss的设计是网络的核心, 经典的如MSE, cross-entropy, hinge loss。BP是通过Gradient Decent计算得到,主要关系到Batch GD, SGD, Momentum, Adagrad, RMSProp, Adam等方法(见注6)。 -
训练CNN时, 可以对输入进行旋转、平移、缩放等预处理提高模型泛化能力。
对输入样本的进行的操作其实就是数据增强的一个方法, 来提升网络拟合的数据空间大小。与之相同的还有裁剪, 色彩抖动, 对比度变化, 当然使用GAN的好生成样本可能也有一些帮助。 -
Bagging能实现跟神经网络中Dropout的类似效果。
Dropout在相同的数据集上训练时, 每次抑制不同的部分, 就相当于有了多个弱学习器, 并且学习器之间share weights。 -
CNN的卷积过程。普通卷积的过程其实就是带权求和, 在图像上一般就是做二维的卷积, 在文本上做一维的卷积。卷积的核心参数就是卷积核大小、步进大小。特殊卷积有Deconvolution(also named by transposed convolutions or fractionally convolution, 见注2), 1x1卷积(见注3)等。
-
Pool。池化的意义在于减少计算的参数量, 获得平移不变形与增大感受野, 主要的手段是Max和Mean, 前向通道的过程顾名思义, 反向做BP的时候, max pool的梯度传输到最大的一个neuron中, mean pool把梯度均匀分到pool的区域里。
-
GAN: 生成器和判别器的对抗博弈。生成式对抗网络(GAN)相关模型学习整理(一),基于生成器和判别器的对抗训练来获得负样本的监督信息。
-
Style Transfer:利用Gram矩阵(特殊的低运算开销的协方差矩阵)来量化风格。风格迁移(Style Transfer)论文阅读整理(一)。加正则项的优化工作多。
-
Tensorflow的Compute Graph。Compute Graph是一个工程化的BP过程中求梯度的方法, 可以在设定完前向通道, 构建完计算图后, 获得每一处BP梯度的值或Placehoder。
-
Activation。对于激活函数的要求, 首先是要非线性函数才能提升网络的拟合能力(or 简化解空间), 其次需要梯度易于求解, 方便计算过程(and 几乎处处可微), 还要单调。Sigmoid(Softmax为多分类扩展), tanh, ReLU系列都是比较经典的激活函数。
Sigmoid的优点在于输出的是0-1的值, 适合用来做如二分类、掩码(门控信号)等输出, 缺点就是两侧梯度过平, 训练效率低下。
tanh相对Sigmoid来说, 均值在0处, 有更好的性能(不用计算bias), 但是依然有Sigmoid难以训练的缺点。
ReLU的优点在于计算简单, 不用再像上面两位去计算指数梯度, 不会有梯度消失的问题, 缺点就是负半轴斜率0导致的失活。升级版Leaky ReLU, 负半轴斜率设置为0.1, 防止失活(玄学效果)。再升级版Parametric ReLU, 把斜率的值作为可以学习(only with momentum)的参数(不加正则), 以及Randomized ReLU, 直接把斜率作为一个随机值。
新一些的还有ELU, SELU等, 使样本分布自动归一化到零均值、单位方差的分布, 从而稳定训练。 -
Batch Normalization。
BN的具体操作为把前面来的输入(单列feature)先缩放成均值为0,方差为1,然后用学习参数的仿射变换(提升网络容量,比如自动去除缩放的效果,可以有一个平移的能力)。在测试的时候,由于没有batch,把前面多个batch学到的仿射变换参数加权平均(靠后的权重更大)来使用。
BN能够起到平滑解空间的作用,训练能更稳(较大的$w$获得更小的梯度),速度更快(可以设置更大的学习率)。一开始是放在激活的前面(针对Sigmoid,tanh效果好),后来也有用在ReLU激活后的(玄学)。和参数初始化有冲突 -
Object Dectection。RCNN, Fast-RCNN和Faster-RCNN
RCNN:Selective Search+CNN+SVM(bounding box regression,见注4)
Fast-RCNN:Selective Search+CNN+ROI+Softmax+非极大抑制处理
Faster-RCNN:End2end, RPN(在最后一个卷积层后,直接学习到候选区域), 加入anchor box见注4。
RoI Pooling Layer::功能上类似SPP,但只是用了单一尺度的池化。输入是region*channel*height*width大小的map,经过7*7尺度的池化,在用max pool获得固定大小的map。升级版RoI Align Spatial pyramid pooling:可以把不同尺寸的map通过多个并行不同尺度的pool转换成相同的size,架构。
RPN网络:快速提取候选区域。架构:在CNN提取得到的feature map上做sliding window,得到定长特征(取决于特征提取器CNN),然后接一个预测回归器,一个分类预测器。
Single Shot Detection:从网络不同层抽取不同尺度的特征做预测。
Feature Pyramid Network:顶层特征通过上采样和低层特征做融合,而且每层都是独立预测(一系列anchor)。
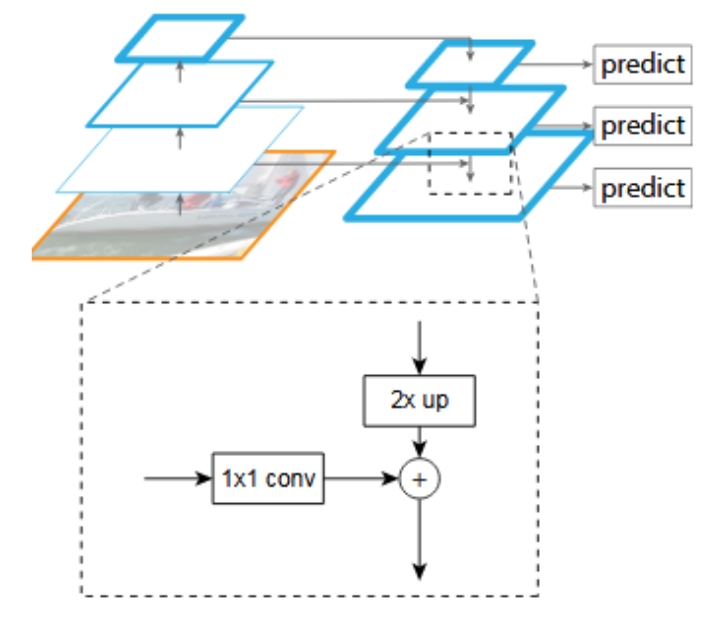
RCNN
1.在图像中确定约1000-2000个候选框 (使用选择性搜索Selective Search)
2.每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取
3.对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4.对于属于某一类别的候选框,用回归器进一步调整其位置
Fast R-CNN
1.在图像中确定约1000-2000个候选框 (使用选择性搜索)
2.对整张图片输进CNN,得到feature map,找到每个候选框在feature map上的映射patch,将此patch作为每个候选 框的卷积特征输入到SPP(Spatial Pyramid Pooling,这步基本是仿照SPP-Net) layer和之后的层。解决了feature map大小不一致的问题。
4.对候选框中提取出的特征,使用分类器判别是否属于一个特定类
5.对于属于某一类别的候选框,用边框回归器进一步调整其位置
Faster R-CNN
1.对整张图片输进CNN,得到feature map
2.卷积特征输入到RPN,得到候选框的特征信息
3.对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4.对于属于某一类别的候选框,用回归器进一步调整其位置
YOLO
端到端训练和实时检测,网格来负责检测物体
-
Mask-RCNN,DeepLab
Mask-RCNN:在Faster R-CNN的基础上,基于每个ROI,多一个生成01mask的分支。提出了RoI Align。
RoI Align: 在RoI pool的过程中,因为不一定能整除,所以切割上会有误差,双线性插值来获得边界值,反向传播时需要修改公式,根据双线性内插的系数来对池化贡献点的四个激活值做BP。 -
防止过拟合。
正则化:L1, L2, BN, IN, dropout, SN
Ensemble: Boosting, Bagging, Stacking
提前终止(early stop): learning rate decay
数据预处理:无监督方法降维,数据增强(见正文2)。
降低网络复杂度:减少层数 加入噪音:输入层可以加高斯噪音
Tricks: res block, highway, pre-train -
RNN->LSTM->GRU。具体框架看图。LSTM利用门控信号来增强网络横向长度(记忆距离),GRU通过压缩门控信号来减少计算量(具体架构见注5)。
-
计算卷积后的feature map大小。为什么要奇数。
$(输入大小 + 2*padding大小 - 卷积核大小)/步进 + 1$。奇数卷积核保证对称padding,以及对称卷积核。 -
VAE。
双encoder,一个计算均值,加上混入的高斯噪音来作为decoder的输入,一个计算方差来调节噪音强度。可以帮助无监督提取特征。 -
Attention
通过Attention Map让NN更关注于高权重的feature。可以迭代生成。 -
Group Convolution
组卷积,减少参数。输入在通道维度上分为多组,对应多个卷积核(size不变),输出concat起来。 -
Dilated Conv 空洞卷积(扩张卷积),不实用pool也能增大感受野。超参:扩张率(被求和的激活值间隔大小)
-
早期CNN架构 LeNet:第一个使用CNN,fc处才有激活函数。
AlexNet:深网络,ReLU,dropout、group conv,Local Responce Normalization。 -
MobileNet, ShuffleNet, Inception(GoogLeNet), Xception, Resnet, Densenet 一系列经典网络架构
Inception提出了一个想法,卷积的计算过程,可以在空间相关、频道相关这两个维度上进行分离(v3提出)。做的是用1×1卷积来压缩深度,然后使用不同大小的卷积核来进行卷积,用不同尺度的特征一起学习。
MobileNet, Depthwise Separable Convolution:把标准卷积分解成深度卷积(depthwise convolution,厚度为1的卷积核,且数量和输入的通道数相同,再进行pointwise convolution or 1*1 conv),用这样组合的方式来降低参数数量。宽度因子$\alpha$,用于控制输入和输出的通道数倍数(也是两种卷积最后的输出通道数)。分辨率因子$p$,控制输入和内部层表示(即输入的feature map大小,即分辨率)
ShuffleNet, 使用feature map不同channel的打乱+1*1Group Conv来代替1*1 conv,提升channel间的信息交流,因为1*1卷积的数量过多,所以节省很多。
Xception在Inception v3的基础上(depthwise separable convolution),它为每个输出通道先执行 1×1 的深度方面的卷积来获取跨通道的相关性,过ReLU再单独做空间上的逐通道卷积。效率高。【先点后棒】
Res-block里的short cut(skip connection)能够把梯度传到几层之外,而且没有Vanishing的现象(梯度经过多个block下降了很多)出现,最后起到加深了网络的作用。
DenseNet的shortcut比Resnet更加密集,跨过的距离更远,可以把梯度传递到更远处的地方,减少参数量。因为累加前面的不同大小的通道,所以需要引入transition layers(1*1 conv+2*2 pool)。还有加入减少输出通道数目的的bottleneck layer(idea from Resnet)。

-
输出值变成NaN
内部的输出值过大,可能是因为学习速率过大(且网络初始的比较差),梯度值过大(clipping),参数初始化方法不好(xavier, msra…),输入的数据有问题,尝试加BN。 -
多标签分类问题
输出层用多个sigmoid做输出(会有不平衡问题,没考虑标签间的相关性);
ML
-
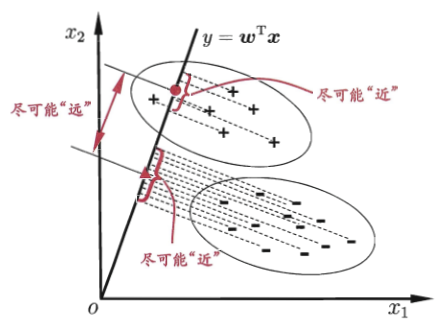
SVM,核函数,松弛变量,如何用于回归,优缺点
使用了hinge loss
线性可分SVM:hard margin hinge 线性SVM:soft margin
非线性SVM:kernel trick+soft margin
loss: hinge、指数、对率
回归:也设置margin
松弛变量:管理正则惩罚项,起到soft margin的作用。 对偶问题求解:用朗格朗日乘子法将有约束优化转化为无约束优化 拉格朗日乘子法: 多分类: 推导: -
SMO:固定除了两个需要更新的其他的变量,去更新他们,高效。
-
数据缺失。
预测填充,C4.5等决策树可以自动应对数据缺失。 -
降维算法。 PCA, LDA, t-SNE ……
PCA主成分学习: 最大化投影后方差+最小化到超平面距离。流程:计算特征间的协方差矩阵,得到其特征向量特征值,选择大的特征值来更新数据集(矩阵乘法)。PCA白化指的是一个利用PCA来完成的数据预处理操作,使得特征之间相关性较低、且方差相同(by scale)。缺点就是是一个线性的算法。
LDA线性判别器:有监督

-
信息熵。
b为常数,n为种类数,i为某个特定种类,$p(x)$为概率。根据上式,概率越极端,熵(不稳定程度)越小。熵越大信息量越大。
\(H(x) = - \sum^{n}_{i=1}p(x_i)log_{b}p(x_i)\) -
完全生长决策树。优缺点
ID3, C4.5, Cart。
ID3基于信息增益的方式来进行树的生长,缺点是纯粹的增益会导致对差异度大的feature做过多选择而忽略其他feature的贡献。
C4.5基于信息增益率的方式来进行生长,对差异度大的feature做一个惩罚防止ID3的问题,可以接受连续变量(排序找阈值转换为bool)
CART基于基尼系数进行裁剪。基尼系数反映的是从数据集重随机抽取两个样本额,类别标记不一致的概率。越小则纯度越高。目标就是划分后是的基尼指数最小。每次构建的时候都会二分划分,所以可以接受连续变量。
信息增益相关见注7。
ID3对样本特征缺失值比较敏感,而C4.5和CART可以对缺失值进行不同方式的处理;ID3和C4.5可以在每个结点上产生出多叉分支,且每个特征在层级之间不会复用,而CART每个结点只会产生两个分支,因此最后会形成一颗二叉树,且每个特征可以被重复使用;ID3和C4.5通过剪枝来权衡树的准确性与泛化能力,而CART直接利用全部数据发现所有可能的树结构进行对比。
(如何做回归?给回归定义一个损失函数,比如L2损失,可以把分叉结果量化;最终的输出值,是分支下的样本均值) -
决策树的剪枝策略。
预剪枝,后剪枝 by check验证集上的精度 -
Ensemble 集成学习方法.
Boosting,训练一个弱学习器->根据结果调整训练样本权重或采样分布->基于新训练样本训练新学习器->重复迭代直到获得一个较强的学习器。降低偏差。
AdaBoost:最小化指数损失函数 Bagging,多个弱学习器并行学习,利用控制输入样本分布、加噪音、控制选择feature数量等方式提升学习器间的差异性。降低方差
Random Forest,随机森林是通过构造多个有差异度的弱学习器(随机样本、随机feature)来并行学习,最后bagging综合多个结果。
Gradient Boosting Decision Tree。沿着梯度方向构造新的函数空间。 基于CART,用梯度提升方法来完成Boosting算法的一个模型。通过决策树预测结果的残差来修正迭代。在梯度下降中,模型是以参数化形式表示,从而模型的更新等价于参数的更新。而在梯度提升中,模型并不需要进行参数化表示,而是直接定义在函数空间中,从而大大扩展了可以使用的模型种类。构建完成后进行剪枝。测试的时候需要累加所有预测器的输出(所以测试阶段可以并行)。GBDT做分类的时候,修改目标函数即可,换成指数函数则退化为AdaBoost。
XGBoost:在使用CART作为基分类器时,XGBoost显式地加入了正则项来控制模型的复杂度,有利于防止过拟合,从而提高模型的泛化能力。对loss做了二阶展开,用了一二阶的梯度信息。根节点开始做分裂,最大化损失函数的差值。有随机采样策略。
综合多个学习器的输出的方法:投票法,stacking(训练完成的模型来综合),模型融合。 -
模型评测方法。 直接留出,自助法,交叉验证。
准确率,错误率,查准率Precision(猜的正例有多少是真的),查全率(召回率)Recall(真实正例里猜中了多少),基于P和R有F1($F_{\beta}$, macro-F1, micro-F1),再延伸有TPR(True Positive Rate 等于查全率), FPR(False Positive Rate 反例里误判的概率)计算的AUC面积。
-
Online Hard Example Mining
把难样本提取出来进行重复训练。先找一个子集(所有正样本,随机负样本)来训练模型A,再把A用到一个大模型上,把A判断的错误正样本添加到训练集中再训练。以此解决难分样本问题。 -
条件随机场CRF
-
高斯混合模型(GMM)
可能某几个feeature独立符合一个高斯模型,利用多个高斯模型来进行组合,来组合拟合结果。 -
朴素贝叶斯,贝叶斯决策
native适用于条件全部独立的情况。这个条件下哪个类的个数最多,这个情况就可能是这个类的。 -
方差偏差分解
方差就是指的测试误差相对训练误差的增量,代表泛化能力。偏差指的是模型本身输出和真实分布的差距,来自于模型本身的不合理设置等。e.g. bagging降低方差、boosting降低偏差
相关面经:
算法题
Q: 复制复杂链表,持有一个next、一个random指针。
A:在原链表上进行复制插入元素,最后拆解开。避免了找random元素时候$O(n^2)$开销。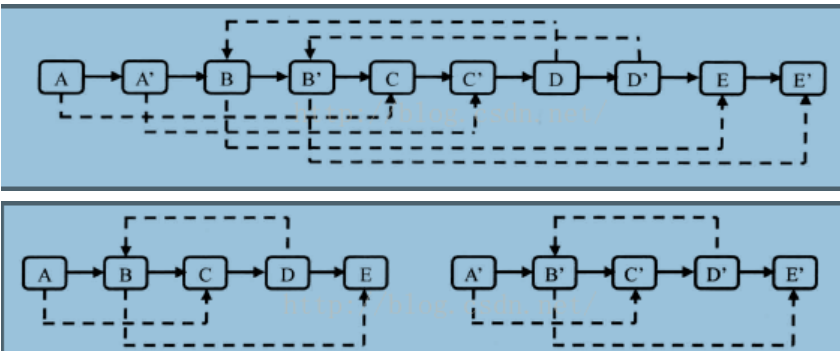
Q:找出数组中出现次数超过一半的数。
A:当我们遍历到下一个数字的时候,如果下一个数字和我们之前保存的数字相同,则次数加1;
如果下一个数字和我们之前保存的数字不同,则次数减1。
如果次数为零,我们需要保存下一个数字,并把次数设为1。
Q:计算抛骰子,抛1或者6庄家赢,2,3,4,5你赢,庄家连续赢了三次,这个概率是多大,这样能说明骰子有问题吗。如果抛了100次,庄家赢了40次,能说明有问题吗。那怎样才能证明这个骰子有没有问题
Q:randN组合
A: rand(N*(N+2)) = randN*(N+1)+randN
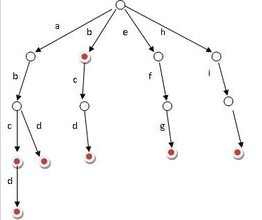
Q: 字典树(字符串词频TOPK)
Q: 背包问题
A: 二维DP
Q: 找两链表的交点 A:先判断是否相交(看遍历的终点是否相同),将长的链表移动长度差的距离,然后同时移动两个链表,找到第一个相等的节点。
Q:找单链表成环的入口节点
A:判断是否成环使用快慢针,在快慢针的基础上,判断环上节点数为n。双针除法,一个先走n步,相遇之处即为入口节点。
Q: 特征处理(预处理?)
A:特征处理:数据清洗(缺失值,异常值,样本比例),规范化(标准化)。特征选择:PCA、LDA降维,基于信息增益等的特征过滤,wrapper method(不断使用从特征空间中抽取出来的特征子集构建模型,然后选出最好的),embedded method
Q: 两个字符串进行加法反转链表实现链表加法
A:RT
Q: kmeans如何初始化
A: kmeans的起始聚类中心会很大程度上影响聚类的效果。解决方法:多组随机选择取最好;第N个中心取平均距离最远的中心;跑一个层次聚类来帮助选取初值;kmeans++,以距离为概率随机选择下一个簇中心。v
Q: 两个节点的最近公共节点
A:暴力后序遍历。
Q:OSI七层网络结构,四次挥手的等待时间,TCP和UDP的区别
Q:mysql引擎
A:InnoDB是事务类型,提供ACID、四种隔离、行级锁定、唯一支持外键约束,更新速度快。
MyIsam,不支持事务,查询速度快,全表加锁
Q:两个字符串序列的最长公共子序列
A:DP,从尾部向前寻找。

Q:TOP K
A:1. Quick Select,基于快排的方法来进行搜索。复杂度同快排。2. 维护一个大小为 K 的小顶堆。顺序遍历数组,如果数据小于堆顶元素,则不作处理继续遍历;如果数据大于堆顶元素,则删除堆顶元素并将当前数据插入到堆中。遍历完数组后,堆中数据即为前 K 大元素。$O(n)=n\log n$
Q: 跳表
A:有高层索引的链表,帮助更快进行区间查找。
Q:多个区间,有交集则合并
A:排序,再单次判断合并
Q:大数据排序
A:hash分流+堆排序(cache放的进去用快排)+归并排序(数据过大放不进cache)+插入排序(尤其适合基本有序的数据)??
Q:连续数组的最大和
A:1. 先求出整体和记为暂时的最大值(即为最大值的下限)
2.遍历数组,求出累加和,若累加和小于0,则累加和清零,否则和当前最大值作比较,若更大则更新。$O(n)$。
Q:一个正整数组成的数组,分成连续的M段,问每段的数之和的最大值最小是多少?
A:在单个数最大值和所有数的区间内部二分法里选阈值,然后贪心搜,$O(n \log k)$
Q:二维直角坐标系上,给定N个点的坐标(float型),一个点C的坐标(float型),一个整数M。问:找一个正方形,它以C点为中心,且四条边分别与x轴和y轴平行,其内部至少包含N个点中的M个点(在边上也算),问这样的正方形边长最小是多少?
A:利用x差值和y差值的最小值进行排序。$O(n)=n\log n$
Q:一个数组里有很多数,只有一个只出现了一次,其他都只出现了两次,怎么找?那如果要找两个只出现了一次的数呢呢?
A:基于①k^k = 0,k^0 = k,②异或运算可调整顺序。则将所有元素进行和0一起做异或操作,结果就是出现了奇数次的数字。$O(n)$。
Q:一个人从原点出发,可以往左走可以往右走,每次走的步数递增1,问能不能到达一个位置x?如果能,给出走的步数最少的方案?
其他面经
Q:Java锁的类型
A:重入锁、读写锁、自旋锁(忙询)
Q:计算机堆栈
A:栈区一般放局部变量等快入快出的数据(Java还有本地方法栈),是线程的私有空间。堆区放几乎所有的对象(新生代、老年代)、静态数据,被所有线程共有。
Q:最大并发数的控制
A:线程池?
Q:分类问题用交叉熵而不用平方损失?
A:平方损失的梯度传递过程受激活函数的梯度影响(梯度消失)
Q:Self-attention
A:从feature中自动学习attention map。
Q:零样本分类问题。即如果测试时出现一个图片是训练时没有的类别,怎么做?
A:用原先的模型做transfer learning,浅层中层的feature提取权重可以使用,后面的输出层增加一维。
Q:TF-IDF文本预处理
A:TF-IDF通过统计词频来标志出跨文章有区分度,单文章内有高词频的词(即潜在的无信息贡献词汇)。
\(TF-IDF(i,j)=文章内词频*逆向文件频率=\frac{n_{i,j}}{\sum_{k}n_{k,j}}*\log \frac{文章总数}{包含单词n的文章总数+1}\)
where i为某特定单词,j为某特定文章
Q:下面两道数学题
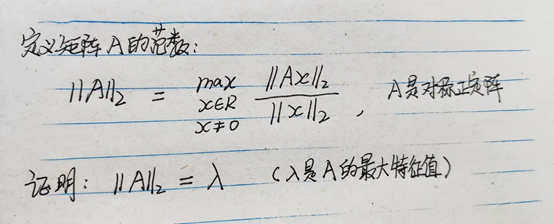

Q:mIoU(图像分割的通用评估指标)的代码实现
A:mIoU是指检测区域和实际区域之间,$\frac{交集面积}{并集面积}$的值,兼顾了查准和查全。
Q:非极大值抑制
A:多个框重叠,要去除概率不是最高的框。
Q:层feature map大小不同怎么办
A:1*1卷积,zero padding,SPP
Q:实现最大并发数的控制
A:Java的方法是维护一个线程池newFixedThreadPool
注
1. Xavier, He。神经网络如果保持每层的信息流动(前向反向)是同一方差, 那么会更加有利于优化。
Xavier是指把参数设置为如下的均匀分布,n为输入的neuron数目(卷积则为长*宽*核数),i为层数,推导略,适合关于0对称的激活函数。
\(U\left[ -\frac{\sqrt{6}}{\sqrt{n_i + n_{i+1}}},\frac{\sqrt{6}}{\sqrt{n_i + n_{i+1}}} \right]. \tag{21}\)
He指如下的正态分布。有ReLU和Leaky ReLU版本。
\(W \sim N[0, \sqrt{\frac{2}{n_i}}]\)
2. Deconvolution。上卷积就是在带孔的feature map上进行卷积,使得到的feature map的前两个维度比输入还要大。上采样的应用场景如超清化等生成场景。也有先上采样再下采样来提升网络表达能力的(如Perceptual Losses for Real-Time Style Transfer and Super-Resolution)。
3. 1x1 conv,1x1卷积现在多用来代替pool的场景,可以在不损失信息量的情况下,减少需要计算的参数量。具体计算过程就是在不同c上同一个位置的激活值求带权和,起到压缩channel数量的作用。
4. Bounding-Box regression, Anchor Box。
Bounding-Box regression,对detect得到的边框做一个线性的调整,要做归一化,平方根来平衡在大box小box上的loss体现
Anchor-box做的是用回归的方法来求解目标的具体位置,包括如下四个连续数值:中心点的xy坐标,框的长宽。每个窗口(来自滑动或RPN)对应N个Anchor-box,对应在一个窗口里去检测几个对象。
5. LSTM与GRU的架构。
如图所示,$z^f$为遗忘控制,来忘记$c^{t-1}$输入的状态,$z^i$为记忆控制,来选择性记忆本cell的激活值$z$(activate by tanh),$z^o$来选择性输出。
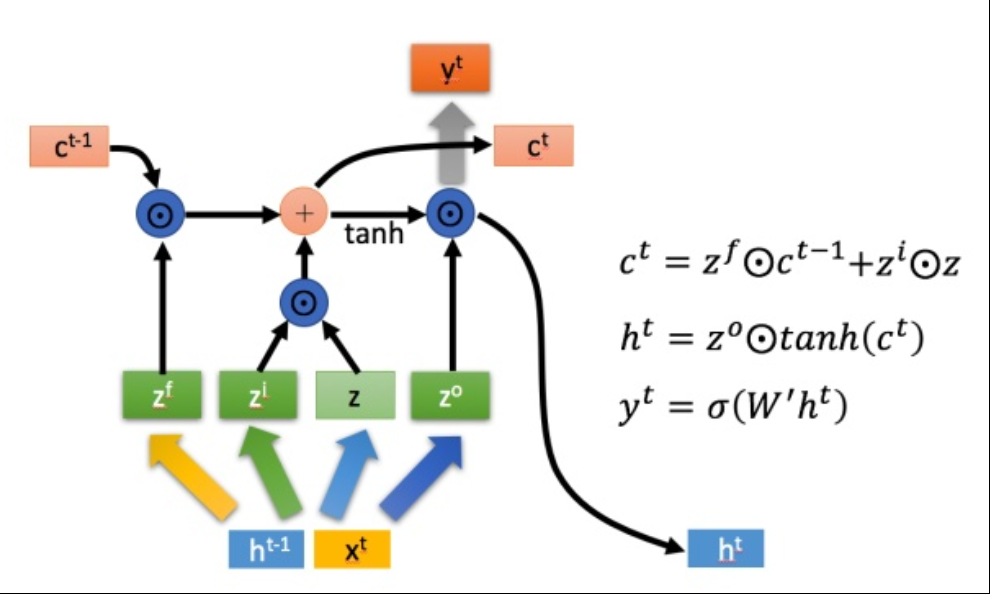 如下图所示,GRU只有$r,z$两组门控信息(压缩)。$r$同样是reset门控负责遗忘,得到$h'$,拿来和$x^t$做concat过tanh,得到本cell的激活值。$h^t = z \odot h^{t-1} + (1 - z)\odot h'$,从而得到输出。可以看到$z$门控同时实现了遗忘和选择记忆。
如下图所示,GRU只有$r,z$两组门控信息(压缩)。$r$同样是reset门控负责遗忘,得到$h'$,拿来和$x^t$做concat过tanh,得到本cell的激活值。$h^t = z \odot h^{t-1} + (1 - z)\odot h'$,从而得到输出。可以看到$z$门控同时实现了遗忘和选择记忆。
6. 梯度下降法的优化。
Batch GD, SGD都是基于控制batch大小的普通GD,SGD用的多是因为单样本做估计计算速度快,虽然比较不稳定,但容易越出局部最优值或鞍点,刷成绩。
AdaGrad,学习率自动衰减,但最后可能会直接停止。可以对低频的参数做较大的更新,对高频的做较小的更新

RMSProp(均方根传播),
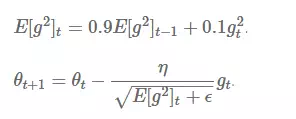 用求梯度平方和的平均数的方式来解决AdaGrad学习率衰减到0的问题(长得太快),修正摆动幅度。
用求梯度平方和的平均数的方式来解决AdaGrad学习率衰减到0的问题(长得太快),修正摆动幅度。
Momentum,带动量的梯度下降,使用指数加权平均来计算平均梯度。$V_{dW}=\beta V_{dW}+(1-\beta)dW$
Adam==AdaGrad+Momentum
牛顿迭代法:二阶收敛,Hessian矩阵(正定的前提下)计算开销大。
7. 信息增益。
8. 金字塔池化backbone。

9. K-Means:无监督聚类,优化如下目标函数
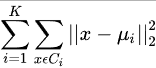
贪心迭代,初始化:从N个样本中随机选择K个作为初始聚类中心;
For t=1:T(此处,T为最大迭代次数)
将N个样本按距离最近原则分配给K个聚类中心;
迭代更新聚类中心;
如果达到终止条件,如全部样本归类无变化,或者样本点到聚类中心的平均距离变化率较低,则退出
时间复杂度为O(TNKD),迭代次数*样本个数*聚类中心数目*样本维度