序
GAN是当下效果较为突出的一种生成模型,但历史工作表明GAN在训练过程中很不稳定,同时对于超参和架构的设置十分敏感,导致实际使用GAN生成的样本难以保证能稳定输出高质量的样本,同时生成样本有比较严重的模式崩塌(mode collapse)的问题。本文主要阐述一系列尝试通过引入集成学习的工作,通过某种特定的策略来综合多个模型来稳定GAN的训练过程。
这方面的工作并不多,因为对于input是noise,输出有随机性的生成模型来说,不好综合多个生成器的输出结果。
Contents
-
Ensembles of GAN:针对Mode Collapse的问题,提出了利用多个生成器集成的方式提高diversity,同时本文也是第一个把集成的思路引入GAN领域的文章。
-
GMulti-AN:提出了集成多个判别器的方式为G提供更优的学习梯度的思想。
-
Dropout-GAN:本文推进了GMAN的思想,通过dropout来动态集成判别器。
-
Generative Adversarial Parallelization:GAP提出了让一组生成器和一组判别器不停交换配对进行训练的方法。
-
Multi-Agent Diverse GAN:MAD-GAN仍然希望通过多个生成器来保证足够的diversity,不同的是,MAD-GAN对判别器进行了特殊的设计保证不同的生成器收敛于不同的mode。
-
Message Passing Multi-Agent GANs:MPM-GAN让多组的生成器、判别器协同工作,其目标分为协作、竞争两部分。
-
AdaGAN:提出了通过在一个重新加权的样本上运行一个 GAN 算法来向混合boost模型中加入一个新的组分的方法。
-
Margin Adaptation for GAN:MAGAN是EBGAN系列的工作,主要是针对EBGAN提出的控制energy上限的超参margin再加入一个动态下降的方法。
Ensembles of Generative Adversarial Networks
他们在实验中观察到G在训练的时候容易产生在多个mode之间跳转的现象,而真实度并没有提升;G在优化JSD的时候总会忽略掉某些数据的分布。

于是提出了三种模型来解决mode collapse的问题。
- Standard Ensembles of GANs(eGANs):直接训练多组GAN,在test的时候随机选一个G出来生成图片。
- Self-ensembles of GANs(seGANs):既然从收敛开始的多个epoch里G的真实度都差不多,而且mode不同,那就直接选最后几个不同epoch时刻的G来作为前面的待随机选择的G集里。
- Cascade of GANs(cGANs):既然GAN对于某些数据捕捉能力不行,那我们就专门针对这些难生成的数据来训练一个GAN。如果D为一张图片打出特别高的分数(收敛后),就说明这个图片G根本没有生成足够真实的图片来误导D,说明这类的图片就是所谓的难生成的图片。设置一个超参$r$作为比例,筛选出前一个GAN生成不好的类别,给下一个新的GAN训练,以此循环,直到新的模型的性能不再提升。
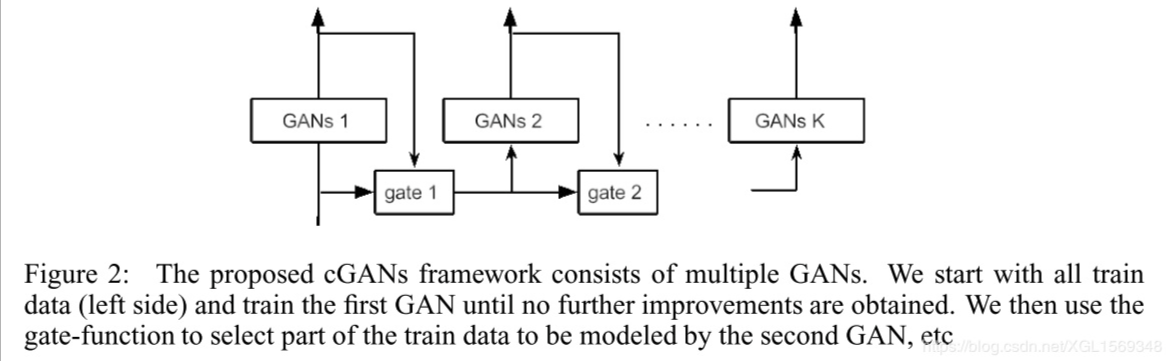 实验中,$r$在0.7-0.8左右效果好。在多版的实验里,seGANs的效果最好。
实验中,$r$在0.7-0.8左右效果好。在多版的实验里,seGANs的效果最好。
问题:前面两种想法很直观很实验,但对于cGANs来说,这样获得的一个生成器集合里,后一个G是前一个G生成低质量样本或低数量样本的补充,联合这些的生成器进行整体输出,并没有避免低质量样本生成的比例。
Generative Multi-Adversarial Networks
GMAN关注于集成多个D,同时保证集成出来的D不是一个苛刻的反对者,而是一个forgiving teacher。
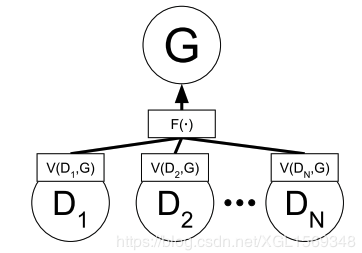
第一个最直观的想法就是通过一个$F(·)$来快速集成多个D的打分结果。D的目标是拉高$V(D,G)$,那么不如直接取最大或者平均值。但实验中这个暴力方法并没有多少提升,而且使用MAX的情况下这样多个D来回切换的过程可能会影响了学习的动态过程。 第二个想法就是想使用BOOSTING的方式来集成多个D。这个想法同样在实验中没有很好的效果,作者推测是集成后的D的对抗力度过强,导致学习梯度没有很好的传向G。(类比先前的文章,D对于fake & true sample有了过于好的分类力度,一个过高分一个过低分导致uniformly negative feedback)
基于以上的想法,作者提出让D的分类力度弱一些的想法(soft discriminator),让max这个操作更soft。
引入三种经典的软化Pythagorean mean方法(算术平均、几何平均、调和平均)即
\(AM_{soft}(V,\lambda)=\sum^{N}_{i} \omega_{i} V_{i}\) \(GM_{soft}(V,\lambda)=-exp(\sum^{N}_{i} \omega_{i} log(-V_{i}))\) \(HM_{soft}(V,\lambda)=(\sum^{N}_{i} \omega_{i} V_{i}^{-1})^{-1}\) where $\omega_{i}=e^{\lambda V_{i}}/\sum_{j}e^{\lambda V_{i}}$,$\lambda$为一个非负的参数,$V_{i}<0$。 $\lambda$等于0的时候,为取平均数,等于无穷大时候,为取最大值。在训练过程中慢慢把$\lambda$向0调小。
文章后面还提了一个平衡G、D之间训练次数的方法,就是在G的目标函数里面加一个$-f(\lambda)$,这项的值会随着$lambda$的减小而增大,从而soft判别器的效果,防止判别器后期过强,实验中设为一个斜率很小的线性函数。
问题:为什么D更好就能保证G更好?这个直观想法会不会有点问题?一个能够传递合理学习梯度的D,意味能够和当前G匹配,指向多个mode,在D上面单独做集成感觉就怪怪的…另外现在来看,平衡次数的方法应该Two Time-Scale Update Rule更流行一些…
Dropout-GAN:Learning from a Dynamic Ensemble of Discriminators
作者认为其实mode collapse就是一种针对单一判别器或静态集成的判别器集的overfit。所以本文提出的就是一个在不同batch中间切换动态集成的一个方法。
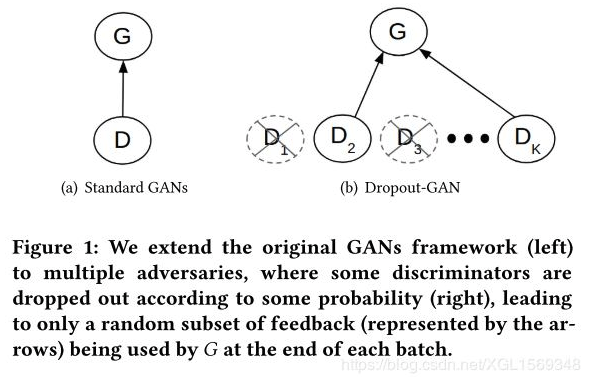
如果所有G和D的feedback连接被丢掉的情况,就重新选一个D来单独监督G
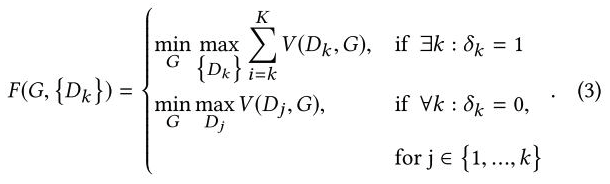
实验内容占了不少,dropout_rate被设置为0.2或0.5的时候表现比较好。判别器的数量越多,收敛速度越慢,超过10个的时候可能会出现更差的结果。同时在每一个iteration中,没有被选中的D也需要进行更新。
Dropout真的是活力无限啊…Dropout ,SpatialDropout ,Stochastic Depth,DropBlock ,Cutout ,DropConnect…
Generative Adversarial Parallelization
GAP的思维基于早期的一个叫做Generative Adversarial Metric的评价GAN效果的工作。
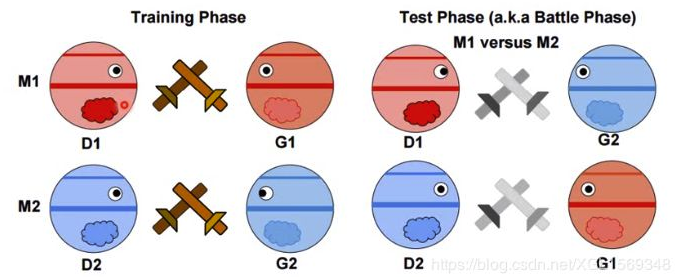
GAM是一个比较两对生成器和判别器的方法,在训练过程中,各自成对训练,在测试阶段,交换进行博弈,然后比较得分,假如说G2打不过D1,即D1给G2生成的样本打出了低分,那就说明G1比G2厉害。
GAP提出的想法,就是每次K步训练之后,就随机交换生成器和判别器的配对情况,最后通过GAM的方式从这组生成器们中选择出来最好的一个。作者认为,这个方法适用于各种GAN的并行化训练,不仅仅是同一种的GAN,也可以是不同类型的GAN混合进行训练。
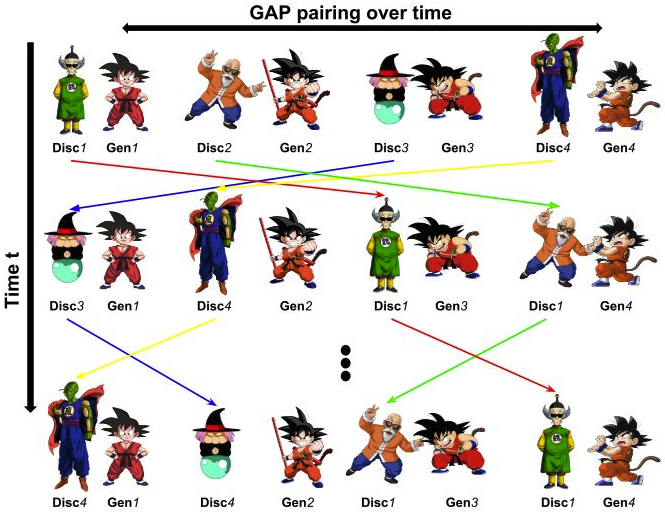
如图,最右边的龟派气功悟空会和比克大魔王、龟仙人、鹤仙人轮流交手,吸收他们的功力 。

实验效果还是非常明显的减少了mode collapse的现象。最后提出了一个GAM的升级版本来应对GAP这种没有特定唯一的判别器的情况。
这个实验效果还是挺有意思的,多组GAN在平行训练间互相传递信息进行互助。问题就是这样交替的过程中,训练的过程不稳定很多,速度也降低了,然后不同架构的GAN可能各自收敛速度就有不小差距,只用了finetune来证明自己的说法。
Multi-Agent Diverse Generative Adversarial Networks
MAD-GAN是组合了多个生成器和一个判别器,希望通过让多个生成器捕捉到不同mode的数据,然后就可以轻松获得多mode的生成结果了。为了实现这个结果,对判别器进行了设计来鼓励生成不同的mode。

为了实现鼓励不同的G生成不同的mode的数据,文章里直接使用了一个比较暴力的方法,直接通过提取生成样本对应的隐空间特征向量,比较向量间的距离作为新的一项loss。 在判别器的输出上,修改为一个多分类器,输出k+1个类,对应来自k个生成器的fake和real。

判别器为了更好的区分类别,就会为G反馈不同的梯度,保证他们生成的样本能够被良好区分。
refer:https://www.youtube.com/watch?v=DP4j2w-x7KI
真暴力…
Message Passing Multi-Agent GANs
MPM-GAN的想法继续推进集成多个生成器的方法,尝试让多个生成器通过传递信息,直接互相学习互相竞争。
先介绍新的目标函数:
Competing Objective:
\(对于G1来说有:E_{z \sim p_{z}(z)}[log(1-D(G_{1}(z)) - f(D(G_{1}(z)) - D(G_{2}{z})))]\)
\(对于G2来说有:E_{z \sim p_{z}(z)}[log(1-D(G_{1}(z)) - f(D(G_{2}(z)) - D(G_{1}{z})))]\)
\(f(x)=max(x,0)\)
其实就是给落后的G加上了一个一项额外的生成差距loss。
Conceding Objective:
\(对于G1来说有:E_{z \sim p_{z}(z)}[log(1-D(G_{1}(z))+ f(D(G_{1}(z)) - D(G_{2}{z})))]\) \(对于G2来说有:E_{z \sim p_{z}(z)}[log(1-D(G_{1}(z))+ f(D(G_{2}(z)) - D(G_{1}{z})))]\)
\(f(x)=max(x,0)\) 这一项和第一个看起来差不多,但是起到的作用是完全不同的。
最后的model就是下图的样子,注意Message Generator和Encoder(MLP)是共享参数的。
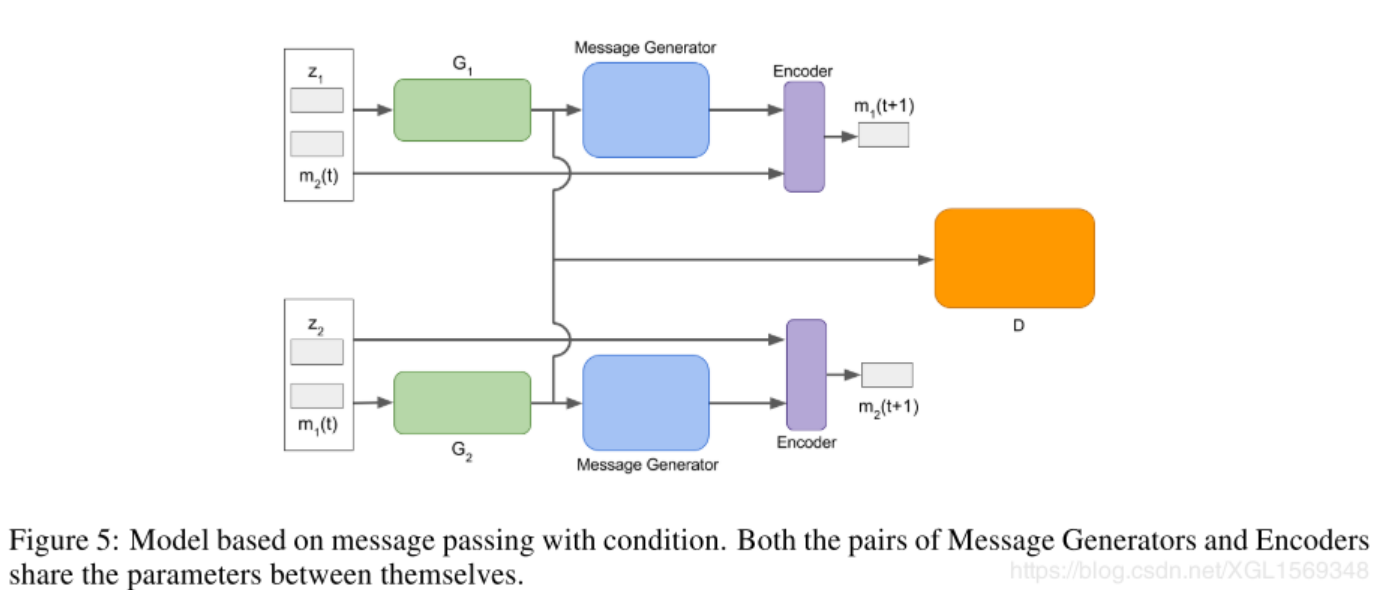
每个message都是前一个收到的message(来自另一个生成器的,作为一个condition)和生成样本经过message gen的结果一起,再过一个encoder得到的结果。
基于以上给出一个正式版本的目标函数:
Conceding Objective
\[对于G1来说有:E_{z \sim [p_{z}(z),enc[msg(G_2(z_2,m_1)),z_2,m_1]]}[log(1-D(G_{1}(z)) + f(D(G_{1}(z)) - D(G_{2}{z})))],G2类似\]Discriminator Objective
\[E_{x \sim p_{data}(x)}[log(D(x))] + E_{z_1 \sim p_{z1}(z1)}[log(1-D(G_1(z_1)))] + E_{z_2 \sim p_{z2}(z2)}[log(1-D(G_2(z_2)))]\]需要注意几个点,不同的G的输入噪音分布应该是不一样的,比如一个是uniform,一个是normal。
想法:文章里没有提到普及到多个G的场景上,感觉多个message的话应该可以做一个简单的整合或者干脆连起来一起?
AdaGAN: Boosting Generative Models
AdaGAN通过重新对训练样本做加权的方式来实现一个类似AdaBoost算法的过程,从而集成多个生成器的结果,最后获得一个性能较好的生成器。
跋
其实使用两组生成器和判别器的方法挺多的,比如之前文章提到的Couple GAN等等,但没那么"ensemble",也难进行组数规模的扩展。