序
本文主要对ECCV 2018上的GAN文章Abstract的内容进行一次汇总,一般不对方法论进行具体阐述,仅为一目录使用。[Abstract翻译(雾)]
paper均可在ECCV 2018对应的open access上进行下载。
How Good is My GAN?
这篇文章主要提出了一种新的量化某个特定GAN模型的能力。文章提出了GAN-train & GAN-test的fan,具体的思路是,既然GAN的目标是能够使生成样本集合的分布和真实样本集合的分布相同,那么基于这个最终目标,任何一个根据其中一个集合训练出来的分类器,在另一个上,应该也具有同样的准确率。
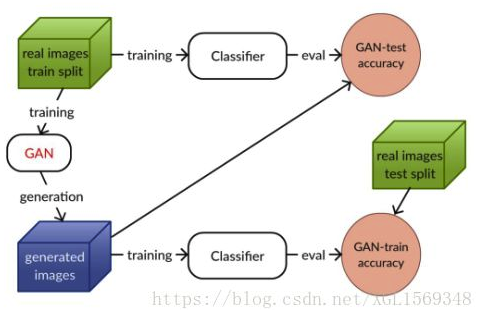
如图,GAN-train 根据 GAN 生成图像训练了一个分类器,并在真实图像上进行测试。该指标评估了 GAN 生成图像的多样性和真实性。GAN-test 根据真实图像训练了分类器,并在 GAN 生成图像上进行评估。该指标评估了 GAN 生成图像的真实性。
本文把现有的一些模型使用这个方法进行了检测,并且提出原来在ImageNet这种超多类数据集上训练的问题可以通过和这个方法得到展示。 refer:https://zhuanlan.zhihu.com/p/43617017
GANimation: Anatomically-aware Facial Animation from a Single Image
原来做人脸多特征变化的经典模型比如StarGAN(一个有多个数据域的GAN模型),而本文提出了一种基于Action Units来解析结构的GAN模型,能够做到人脸的多特征的插值连续变化。通过控制AU的大小来控制特征变化的程度。此外,训练数据除了标记被激活的AU以外不需要其他监督,此外模型引入了attention来帮助解决背景扰动、光线问题。

(本文为ECCV 2018 Best Paper Award, Honorable Mention) refer:https://zhuanlan.zhihu.com/p/44609445
RefocusGAN: Scene Refocusing using a Single Image
本文提出了RefocusGAN,通过去模糊再模糊的方式来对实现对单张图片进行重新对焦的功能。去模糊的过程由一个Conditional GAN完成,训练数据为一张近焦图片和Focus measure response(下图中的黑白图),基于以上两组数据生成全清晰的中距离对焦图片,再基于近焦图片和中焦图片来生成远焦图片。

ReenactGAN: Learning to Reenact Faces via Boundary Transfer
ReenactGAN将面部动作和表情从任意人的单眼视频输入转移到目标人上输出。具体思路为,首先将原始脸映射到人脸特征边界的隐空间。然后训一个网络让源人脸的边界能转移到目标人脸的边界(facial landmark detection)。最后,使用特定于目标的Decoder来生成新的人脸。(在像素空间传输可能导致结构伪影structural artifacts)
只要边界转移的过程表现好,结果就很好。另外,ReenactGAN因为在作用的过程中只有向前传播,效率高,单GTX1080上能实现30FPS。
PS:第一作者的area就是face alignment

refer:https://medium.com/@pomelyu5199/%E8%AB%96%E6%96%87%E7%AD%86%E8%A8%98-eccv18-reenactgan-922f3a5ae5b2
Recycle-GAN: Unsupervised Video Retargeting
Recycle-GAN把一个视频的内容带到另一个视频里,同时保留原视频的风格。具体思路为,除了考虑GAN的对抗loss以外,加入时空的信息(使用patiotemporal constraints)来保证内容的改变和风格的保留。

Sub-GAN: An Unsupervised Generative Model via Subspaces
Sub GAN提出了基于多个子空间的GAN,能够解开多个子隐空间的问题然后生成足够多样性的样本。高维度的自然数据(如图片)本质上仍然是多个低维有密集语义的子空间的联合,Sub GAN还提出一个新的聚类器通过子空间信息和生成器、判别器互相影响。
不同于早期的生成模型,Sub GAN可以通过控制子空间的多样性来控制其生成样本的多样性。另外Sub GAN可以在无监督的前提下来可视化研究的类别信息和隐空间的属性,从而可以防止模型崩塌的问题。
Semi-supervised FusedGAN for Conditional Image Generation
FusedGAN 可以在保证真实性、多样性的前提下,进行可控的采样。不同于同样目的Stacked GAN需要多阶段的分别训练,FusedGAN只是一个单步流水线的方式。FusedGAN的训练也不需要成对的完全监督条件,从而可以利用更多的数据来生成更好的样本,具体的方法为融合了两个生成器,一个是有条件一个是无条件的,两者的隐空间有一定的分享。除此之外Fused GAN也可以在文本转图片,属性转人脸图片的任务得到应用。

To learn image super-resolution, use a GAN to learn how to do image degradation first
本文关注的是图像超清化。他们认为,早期的工作在生成低分辨率图片的时候,都是使用了简单的下采样方式,但这样产生的模型在面对现实世界中的低分辨率图片效果并不好。所以他们使用了一个额外的GAN模型来实现高分辨率到低分辨率的转换过程,而且使用的是非成对的高低分辨率图片数据进行训练,在训练低分辨率到高分辨率的GAN时候,使用的就是成对的图片数据。

Transferring GANs: generating images from limited data
迁移学习的过程被使用在各种各样的判别模型上(分类器等),本文提出了把domain adaptation 用在生成模型上的迁移过程方法。通过评判目标域的大小、源和目的域的距离、cGAN的初始化过程来完成实验。在目标域的数据量有限的时候,这个方法可以体现出比较强的优越性。另外,以上的结论也适用于把无条件GAN的能力迁移到cGAN的过程上。最后,在这样的迁移过程中,源模型如果是在一个数据密度更高(而非多样性)的数据集上训练的,效果更好。

AugGAN: Cross Domain Adaptation with GAN-based Data Augmentation
本文还是和Domain Adaptation有关。本文认为早期的GAN在图片的变化过程中难以保持一致性,尤其是在多域之间的高分辨率图片数据中。为了解决这个问题,作者提出了一个基于encoder、discriminator、generator、parsing net四个组件的架构。在评价多种方法的生成样本效果时,在生成样本上训练FRCNN和YOLO这样的成熟架构,然后比较他们在目标检测的准确度。后面论文里的图片都是基于白天和夜晚的图片。

refer:https://www.youtube.com/watch?v=_ENm7pvO6Rg
Dist-GAN: An Improved GAN using Distance Constraints
本文提出了Dis-GAN,应用了新的训练方法来减少模型崩塌和梯度消失的问题。首先在架构上,增加了一个Autoencoder,把它重构得到的图片作为相对的真实图片给判别器训练,从而降低判别器的拟合速度和防止梯度消失。第二,提出了两个新的约束项latent-data distance constraint 和discriminator-score distance constraint。前者是为了提高隐空间里样本的距离和对应数据样本的距离的匹配度,后者是为了通过判别器的输出来对齐生成样本的分布和真实样本的分布。
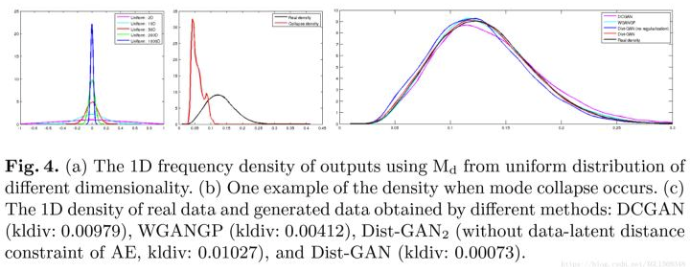
上图就是一个基于密度的模型崩塌程度的展示。
SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network
本文关注的是Object Detection。早期的目标检测方法对于小型的对象表现并不好,本文提出了端到端的Multi-Task GAN来提高对于小目标检测准确度。生成器在其中主要起到把不清晰的小目标提高其分辨率的作用,判别器具有多任务,判别图片真假、分类准确度、bounding box的准确度。在训练的时候,分类准确度和b-box的准确度部分的loss也会反馈梯度给生成器。
Attention-GAN for Object Transfiguration in Wild Image
本文提出的方法是把GAN和Attention做结合来针对野生动物的图片做转换。把生成器的部分分为两个网络,一个来生成一个稀疏Attention map(针对待转换的区域),另一个来负责做转换。同时因为使用了attention map,防止了cycle consistency loss被背景因素干扰。Attention Losses的构建基于X域中x的Attention map和由x转换到Y域中y的Attention map的想法(类似cycle consistency的想法)。
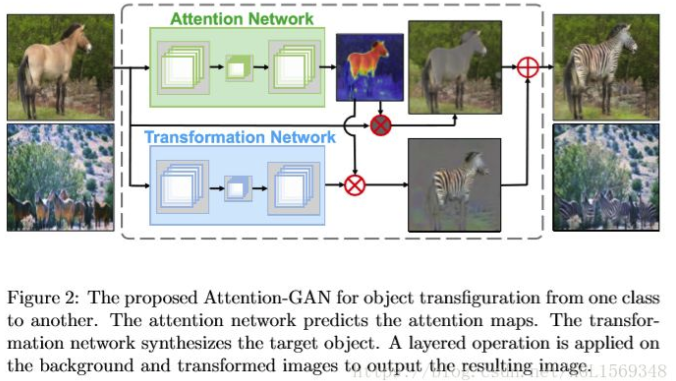
refer:https://www.jianshu.com/p/f87c26f17d2c
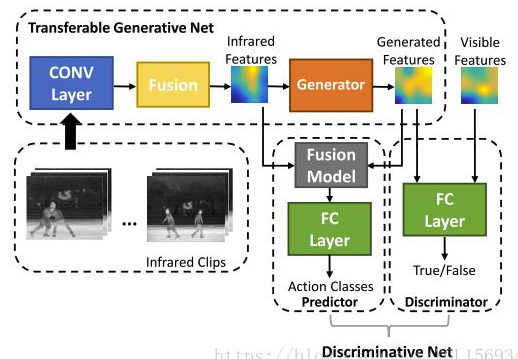
PM-GANs: Discriminative Representation Learning for Action Recognition Using Partial-modalities
作者认为不同模态的数据应有互补的信息(如RGB+红外),本文提出的PM-GAN能够通过部分模态的数据来学习全模态的表示,从而提升动作识别任务的性能。完整的表示是通过生成的表示代替丢失的数据通道来实现的。除此之外提供了一个新公开的行动识别红外数据集。
ELEGANT: Exchanging Latent Encodings with GAN for Transferring Multiple Face Attributes
本文关注于人脸属性迁移。这个任务主要有三个挑战,匹配效果差,不能同时迁移多个属性,低质量结果。ELEGANT这个模型接受输入两张不同的人脸图片,通过交换隐空间特征来交换对应的人脸属性,从而快速完成多属性转移的任务。使用了多尺度判别器来提升高分辨率图片质量。
 PS:这篇文章的第一作者Taihong Xiao(PKU)也有同名知乎账号,还有这文章名真的是疯狂凑梗又藏头诗
PS:这篇文章的第一作者Taihong Xiao(PKU)也有同名知乎账号,还有这文章名真的是疯狂凑梗又藏头诗
ExplainGAN: Model Explanation via Decision Boundary Crossing Transformations
为什么一个图片分类器能为图片正确分类?早期的网络解释方法要么难以做可视化,要么在生成决策边界的过程中生成的图片质量很低、甚至没有明显的解释能力。本文提出了ExplainGAN,能够生成高质量图片来表现决策边界。实验都是基于图片转换的实验来完成的。另外,文章还提出了一个新的能量化网络解释过程的方法。
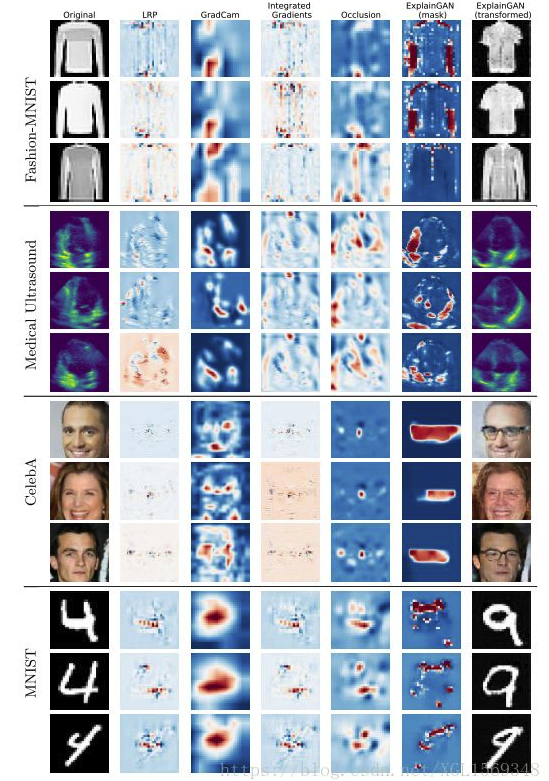
(把GAN用在网络可解释性上还是挺有新意的。
Image Generation from Sketch Constraint Using Contextual GAN
本文关注由手写简笔画到图像的生成。早期方法会受到简笔画边缘的强行约束去生成符合简笔画边缘的图像,使得训练不稳定。本文把简笔画作为弱约束,即边缘不完全吻合。本文提出的新方法为joint image completion,简笔画只提供图像的上下文信息。Contextual GAN能学习简笔画和对应图像的联合分布。实现以下优点:1,图像联合表示可以更简单有效的学习图像/简笔画的联合概率分布,避免跨域学习的问题。2.虽然输出仍然依赖于输入,但是不会像早期的cGAN那样输出严格对齐输入的特征。3.从联合图像的观点来看,图像和简笔画没有什么不同,因此用同一个的网络就能做到图像到简笔画的生成。
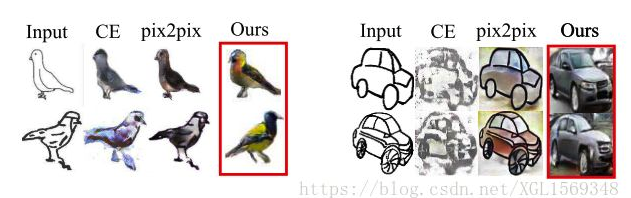
refer:https://zhuanlan.zhihu.com/p/44150864
Attribute-Guided Face Generation Using Conditional CycleGAN
仍然是超清化任务,不同的是,生成的过程中,强监督是从低分辨率图片中提取的属性,基于属性去生成高清图。在模型设计上,用的是带条件的Cycle GAN,能使用不成对的训练数据,并且可以通过扰动属性来控制生成的脸。实验展示了三个部分,属性不变的超清化,修改脸的属性,正脸生成。

Modular Generative Adversarial Networks
本文提出了一种模块化的GAN构建思路,避免了早期工作在多个域之间转换的过程中遇到的三个问题,1.需要构建指数级别多的转换函数,2.学习某个特定域的时候,不能使用其他域的信息,3.差异巨大的域之间转换难度大。本文提出的Modular GAN包含几种可重复利用、可组合的模块,包括生成器、编码器、重构器、转换器和判别器。通过组合不同的(转换器)模块,可以将图像转换到不同的域。

Generative Adversarial Network with Spatial Attention for Face Attribute Editing
本文认为早期针对人脸属性变化的方法都会不可避免地修改到无关的区域,所以提出了加入局部注意力的方式。提出的SaGAN(和SAGAN区分)模型具体为,生成器中包含一个网络来控制人脸属性修改图片,一个带局部注意力的网络来定位指定的属性,判别器就还是判断图片是否真实、人脸属性是否正确(分类器)。

Multimodal Unsupervised Image-to-image Translation
本文提出的新模型,把图片转换过程中产生的隐空间分割成,内容部分和风格部分,同域的数据分享内容部分隐空间,但不同的样本有不同的风格部分隐空间。(disentangled representation learning相关)
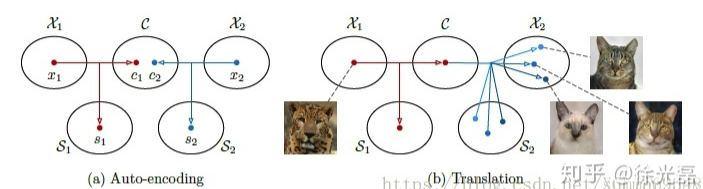
Unsupervised Image-to-Image Translation with Stacked Cycle-Consistent Adversarial Networks
早期的无监督下图片转换在面对高分辨率或者域相差过多的情况下表现不好,本文提出了一个类似于Stack GAN的多阶段转换方法,在coarse-to-fine的过程中提高图片细节精度。除此之外提出了一个新的多阶段之间的融合方法。(类似于Stack+Cycle的组合…)
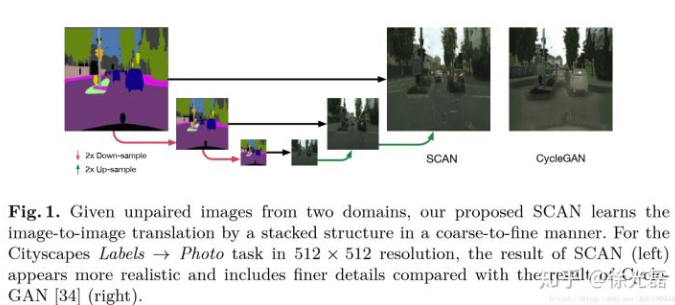
Estimating the Success of Unsupervised Image to Image Translation
本篇FAIR的文章主要是提出了一个度量无监督下图片转换任务的评价标准。有监督情况可以用validation error这样的无偏估计,但对于无监督任务就很难说一个合适的标准。本文提出了一个基于Simplicity Principle的方法来度量,效果可以用于观察模型效果、超参调整等。(偏理论)
future work:
Deep Recursive HDRI: Inverse Tone Mapping using Generative Adversarial Networks
本文提出了利用GAN的方式为单张图片提高动态范围的方法。
Discriminative Region Proposal Adversarial Networks for High-Quality Image-to-Image Translation
Real-Time Hair Rendering using Sequential Adversarial Networks
Wasserstein Divergence for GANs
本文提出一个Wasserstein Divergence来避免碰到评价Wasserstein Distance时需要进行Lipschitz约束的问题。(偏理论)
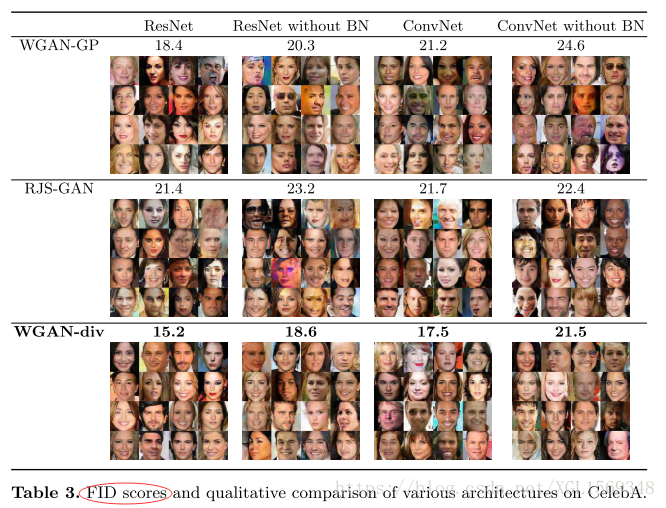
Fictitious GAN: Training GANs with Historical Models
本文利用博弈论的观点来研究训练过程的收敛过程,提出的Fictitious GAN通过混合历史模型的方法来训练网络,能够解决一些原始训练方法无法解决的拟合失败问题,同时可以证明生成分布和目标分布的均值相等。(偏理论)